
SysMoBench: Liệu LLM có thực sự mô hình hóa được hệ thống thực tế bằng TLA+ hay chỉ "thuộc lòng" giáo trình?
SysMoBench là một chuẩn mực mới đánh giá khả năng của các mô hình ngôn ngữ lớn (LLM) trong việc tạo đặc tả hình thức TLA+. Kết quả cho thấy dù LLM rất giỏi về cú pháp, chúng thường gặp khó khăn trong việc mô hình hóa chính xác hành vi của hệ thống thực tế so với các ví dụ lý thuyết trong sách giáo khoa.
Trí tuệ nhân tạo đang ngày càng đóng vai trò quan trọng trong việc thúc đẩy các ứng dụng thực tế của phương pháp hình thức trong hệ thống máy tính. Tuy nhiên, một câu hỏi lớn vẫn còn bỏ ngỏ: Liệu các Mô hình Ngôn ngữ Lớn (LLM) có thực sự khả năng trong việc mô hình hóa chính xác một hệ thống tính toán, hay chúng chỉ đơn thuần đang "thuộc lòng" và lặp lại các tài liệu tham khảo?
Đội ngũ Specula đã chia sẻ trải nghiệm đánh giá LLM trên việc mô hình hóa mã hệ thống bằng TLA+—ngôn ngữ đặc tả dành cho các hệ thống đồng thời và phân tán—cũng như giới thiệu SysMoBench, một chuẩn mực mới nhằm giải quyết vấn đề này.
Thách thức từ Etcd và "bài mẫu" Raft
Cách đây vài tháng, đội ngũ đã yêu cầu Claude viết một đặc tả TLA+ cho triển khai Raft của Etcd. Kết quả ban đầu rất khả quan: mã vượt qua kiểm tra cú pháp, chạy qua bộ kiểm tra mô hình TLC và trông giống như một mô hình hình thức hoàn chỉnh.
Tuy nhiên, khi soi xét kỹ hơn, họ nhận ra một vấn đề lớn: đặc tả này trông giống hệt như mã trong bài báo gốc của Raft và có rất ít liên quan đến các chi tiết cụ thể của Etcd. Những gì Claude tạo ra không phải là đặc tả cho Etcd, mà là bản sao từ phụ lục bài báo Raft.
Điều này đặt ra một câu hỏi khó khăn hơn khi LLM ngày càng hoàn thiện: Làm sao để phân biệt AI đang trung thực mô hình hóa hệ thống hay chỉ đang recite (trích dẫn lại) tài liệu tham khảo của hệ thống đó?
SysMoBench: Chuẩn mực đánh giá mới
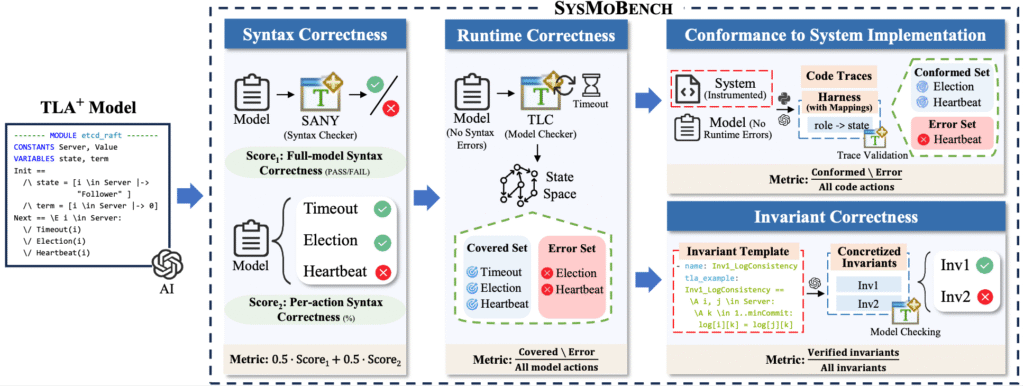
Để phân biệt hai khả năng này, SysMoBench đã được ra đời như một giải pháp đánh giá tự động. SysMoBench cung cấp cho LLM 11 hệ thống khác nhau bao gồm cả đồng bộ hóa đồng thời và giao thức phân tán.
 Tổng quan về SysMoBench
Tổng quan về SysMoBench
Quy trình đánh giá diễn ra qua 4 giai đoạn:
- Giai đoạn Cú pháp: Kiểm tra xem đặc tả có biên dịch được hay không.
- Giai đoạn Thời gian chạy (Runtime): Kiểm tra xem TLC có thể thực thi đặc tả mà không gặp lỗi.
- Giai đoạn Tương thích (Conformance): Sử dụng xác thực vết (trace validation) để so sánh vết thực thi từ mã nguồn với mô hình.
- Giai đoạn Bất biến (Invariant): Kiểm tra xem đặc tả có thỏa mãn các thuộc tính an toàn và tính sống còn chính xác hay không.
Cách tiếp cận đa giai đoạn này giúp lộ ra những khoảng trống giữa một đặc tả "thuộc lòng" sách giáo khoa và một đặc tả thực sự mô phỏng hệ thống.
Mô hình hóa theo "sách giáo khoa" và những sai lầm hệ thống
Khi chạy các LLM hàng đầu hiện nay như Claude, GPT, Gemini, DeepSeek... trên SysMoBench, một mô hình lặp lại xuất hiện. Các đặc tả của chúng hoạt động rất tốt ở hai giai đoạn đầu (Cú pháp và Runtime). Hầu hết đều biên dịch sạch sẽ và chạy qua TLC mượt mà.
Tuy nhiên, khi bước vào giai đoạn Tương thích, hai hình thức "mô hình hóa sách giáo khoa" sai lệch bộc lộ rõ:
- Đặc tả đi vào các trạng thái mà hệ thống thực tế không bao giờ đạt được.
- Đặc tả thất bại trong việc đạt được các trạng thái mà hệ thống thực tế luôn đạt được.
Kết quả là các LLM hàng đầu hiện nay chỉ đạt trung bình khoảng 46% trên điểm tương thích và 41% trên điểm bất biến, dù có điểm cú pháp gần như hoàn hảo.
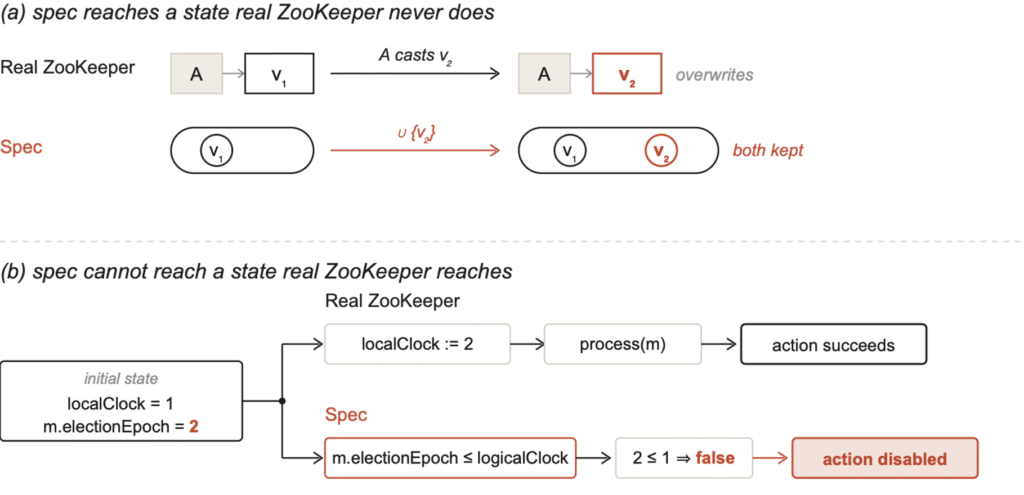 Các chế độ thất bại trong đặc tả ZooKeeper FLE do LLM tạo ra
Các chế độ thất bại trong đặc tả ZooKeeper FLE do LLM tạo ra
Một ví dụ điển hình đến từ đặc tả ZooKeeper Fast Leader Election (FLE) của Claude Sonnet. Trong mã nguồn ZooKeeper, recvset là một bản đồ (map) được khóa bởi người gửi; khi cùng một peer gửi một lá phiếu mới trong vòng mới, nó sẽ ghi đè lá phiếu cũ. Tuy nhiên, Sonnet đã viết nó dưới dạng phép hợp tập hợp (set union), giữ cả lá phiếu cũ và mới. Mô hình "tích lũy tất cả các phiếu bầu" này phổ biến trong sách giáo khoa phương pháp hình thức nhưng không phù hợp với ngữ nghĩa của ZooKeeper.
Trong trường hợp ngược lại, LLM thường gộp các thao tác trải dài nhiều bước trong mã thành một bảo vệ nguyên tử (guard), khiến các chuyển đổi trạng thái trở nên bất khả thi trong đặc tả.
Xác thực chuyển đổi: Đọc đặc tả ở cấp độ hành động
Thay vì chỉ đưa ra một điểm số tổng hợp, SysMoBench cung cấp chẩn đoán ở cấp độ từng hành động hoặc bất biến. Đặc biệt là giai đoạn Tương thích sử dụng phương pháp gọi là Transition Validation (Xác thực chuyển đổi).
Phương pháp này thu thập các vết thực thi từ hệ thống thực, sau đó cắt mỗi vết thành một chuỗi các "cửa sổ chuyển đổi". Mỗi cửa sổ là một bộ ba: (trạng thái_trước, hành_động, trạng thái_sau). TLC sẽ kiểm tra xem hành động của đặc tả có thể di chuyển từ trạng thái trước sang trạng thái sau hay không. Điều này giúp chỉ ra chính xác hành động nào hoặc chuyển đổi trạng thái cụ thể nào đang bị sai lệch.
Kết quả đánh giá và Khoảng cách thực tế
Việc chạy các LLM hàng đầu trên 11 hệ thống cho thấy chúng rất giỏi trong việc tạo ra cú pháp TLA+ chính xác nhưng gặp khó khăn trong việc đảm bảo tính tương thích và bất biến phù hợp.
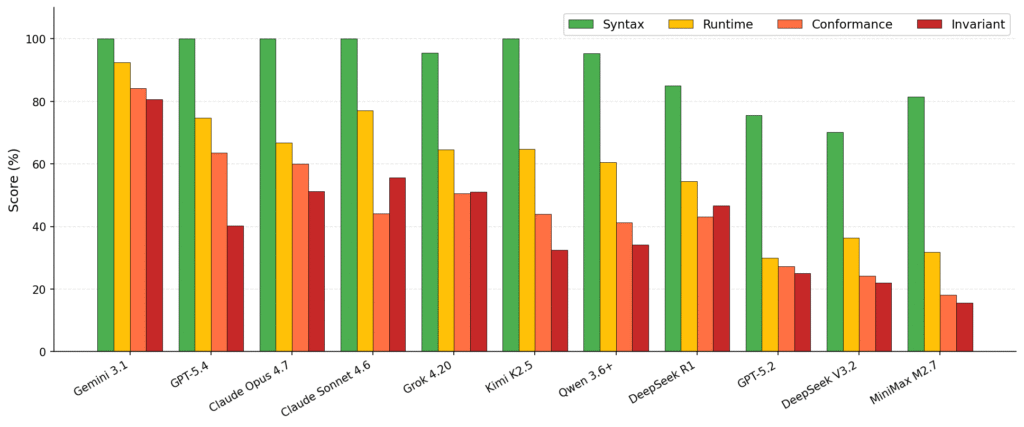 Điểm số qua từng giai đoạn trên SysMoBench
Điểm số qua từng giai đoạn trên SysMoBench
Hầu hết các LLM đều đạt gần 100% ở giai đoạn Cú pháp. Tuy nhiên, khoảng cách thực sự mở ra ở Tương thích và Bất biến. Với các hệ thống phân tán phức tạp như Etcd, RedisRaft, CURP, LLM thường đạt điểm cao ở giai đoạn 1 nhưng bắt đầu gặp trục trặc từ giai đoạn 2 trở đi. Ngay cả Claude Sonnet 4.6, một trong những LLM mạnh nhất, cũng chỉ đạt 25% tổng thể trên RedisRaft và CURP.
Viết một mô-đun TLA+ biên dịch được là khả thi, nhưng việc căn chỉnh mô-đun đó với hành vi thực tế của một hệ thống cụ thể là một thách thức lớn.
Thách thức và Tương lai
Vẫn còn một số vấn đề chưa được giải quyết. Đầu tiên, việc đánh giá ở cấp độ cửa sổ phụ thuộc nhiều vào việc lấy mẫu vết (trace sampling). Thứ hai, sự trừu tượng hóa trạng thái tất yếu làm mất thông tin. Thứ ba, tính tổng quát hóa giữa các nhiệm vụ vẫn là thách thức khi thêm hệ thống mới vẫn cần viết tay các bộ công cụ.
Đội ngũ Specula đang phát triển các tác nhân AI (AI agents) chuyên biệt hơn. Họ nhận thấy rằng các tác nhân mã biên giới như Claude Code và Codex đã có khả năng mạnh mẽ trong việc mô hình hóa TLA+. Specula—một tác nhân chuyên biệt cho mô hình hóa hình thức TLA+—đã đạt điểm số hoàn toàn về tính tương thích và bất biến trên các nhiệm vụ SysMoBench hiện tại.
Bảng xếp hạng tại sysmobench.com đang được cập nhật liên tục và đội ngũ chào đón sự đóng góp của cộng đồng cho các hệ thống, LLM và kết quả mới.
Nguồn bài viết gốc: SIGOPS Blog
Bài viết liên quan
Công nghệ
Open Terminal: Ứng dụng phong cách Bloomberg giúp dân đầu tư cá nhân tiếp cận dữ liệu tài chính chuyên sâu
04 tháng 6, 2026

Phần mềm
Triển khai mảng động trong C: Không cần Struct, không lưu trữ dung lượng
13 tháng 6, 2026

Phần mềm
Giám đốc Rimini Street: "Headless ERP" và mã nguồn mở là chìa khóa thoát khỏi sự kiểm soát của nhà cung cấp
16 tháng 6, 2026