
Tại sao bạn nên thêm Observability vào quy trình trích xuất dữ liệu với OpenTelemetry
Bài viết này sẽ hướng dẫn bạn cách thêm khả năng quan sát (observability) vào pipeline trích xuất dữ liệu sử dụng OpenTelemetry. Bạn sẽ học cách phát hiện các lỗi ẩn như thời gian chờ (timeout) và các yêu cầu thử lại (retry) tốn kém mà mã xử lý lỗi thông thường thường bỏ qua.

Bất kỳ hệ thống nào lấy dữ liệu ở quy mô lớn đều đối mặt với một lớp lỗi mà xử lý lỗi thông thường không thể bắt được. Không phải vì mã của bạn tệ, mà vì các lần thử lại (retry) cuối cùng thành công, các truy vấn mất thời gian gấp 10 lần trung bình, và các miền bị timeout âm thầm — chúng không ném ra ngoại lệ vì về mặt kỹ thuật chúng không phải là lỗi. Và bạn sẽ không bao giờ biết điều đó. Giải pháp thực sự là thêm khả năng quan sát (observability) phù hợp.
Liệu có quá mức cần thiết? Không hề. Vì một pipeline dữ liệu — bất kỳ pipeline nào — với các cuộc gọi mạng, retry, timeout và độ trễ thay đổi hoang dáng giữa các truy vấn và miền khác nhau là một ví dụ điển hình của hệ thống phân tán. Nó có tất cả các chế độ lỗi giống nhau, vì vậy nó xứng đáng có cùng công cụ hỗ trợ.
Trong bài viết này, chúng ta sẽ xây dựng một pipeline SERP trên API của Bright Data và trang bị nó với OpenTelemetry, tiêu chuẩn mã nguồn mở để truy vết phân tán (distributed tracing). Bright Data giúp giảm các rắc rối về chặn và proxy ngay từ đầu — nhưng truy vết Otel phù hợp sẽ cho bạn thấy chính xác rủi ro còn lại ở đâu.
 Giao diện tìm kiếm của Jaeger
Giao diện tìm kiếm của Jaeger
Lợi ích thực tế
Mục tiêu ở đây là làm nổi bật các vấn đề mà bạn có thể gặp phải, nếu không bạn sẽ âm thầm trả tiền cho chúng. Các mô hình này tương ứng gần như 1-1 với bất kỳ pipeline trích xuất dữ liệu nào trông giống như trong môi trường sản xuất.
- Phát hiện "retry storm" (Bão thử lại): Nếu một miền bắt đầu chặn mạnh mẽ, bạn sẽ không thấy nó là lỗi cứng (hard error) nữa, mà là sự gia tăng dần dần trong các span
scraper.retries > 0. Đó là cảnh báo sớm trước khi bạn kích hoạt lệnh cấm hoàn toàn hoặc vượt quá hạn ngạch proxy trong tháng. - Thấy rõ chi phí thực tế: Mỗi lần retry là một yêu cầu proxy khác. Nếu bạn trả tiền theo yêu cầu hoặc theo GB,
scraper.retriestrên các span của bạn ánh xạ trực tiếp đến một mục trên hóa đơn. Bạn có thể tổng hợp điều này và thiết lập cảnh báo. - Phân tích độ trễ theo từng truy vấn: Một số truy vấn về mặt cấu trúc chậm hơn — các thuật ngữ cạnh tranh hơn, trang kết quả nặng hơn, nhiều cạnh tranh hơn trong pool proxy. Traces cho phép bạn thấy điều này theo từng truy vấn thay vì một mức trung bình hòa trộn làm cho mọi thứ trông có vẻ ổn.
Về cơ bản, nếu bạn chỉ lấy đi một điều từ bài viết này, hãy để nó là điều này: pipeline dữ liệu có chính xác các chế độ lỗi như bất kỳ hệ thống phân tán nào khác — timeout, lỗi một phần, khuếch đại retry, suy giảm âm thầm — dù dữ liệu có được lấy thông qua cuộc gọi API hay chỉ là scraping.
Cài đặt ban đầu
Dưới đây là những gì bạn cần:
opentelemetry-api>=1.20.0
opentelemetry-sdk>=1.20.0
opentelemetry-instrumentation-requests>=0.41b0
opentelemetry-exporter-otlp-proto-http>=1.20.0
requests>=2.28.0
python-dotenv>=1.0.0
Các thư viện quan trọng:
opentelemetry-instrumentation-requests— cung cấp truy vết HTTP tự động. Không cần công thủ công nào cả.opentelemetry-exporter-otlp-proto-http— dùng khi bạn muốn gửi traces đến một nơi thực sự như Jaeger.
Trước khi chạy pip install -r requirements.txt, hãy tạo tệp .env với nội dung sau:
BRIGHT_DATA_API_KEY=your_api_key
BRIGHT_DATA_ZONE=serp
BRIGHT_DATA_COUNTRY=us # tùy chọn
OTEL_EXPORTER=console # đặt thành "jaeger" để gửi traces đến Jaeger
Khởi tạo OpenTelemetry
Chúng ta muốn hai chế độ: một exporter console cho phát triển nơi traces được in ngay trong terminal, và một exporter OTLP cho sản xuất. Một biến môi trường duy nhất sẽ chuyển đổi giữa chúng:
import os
from opentelemetry import trace
from opentelemetry.instrumentation.requests import RequestsInstrumentor
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import BatchSpanProcessor, ConsoleSpanExporter
from opentelemetry.sdk.resources import SERVICE_NAME, Resource
def init_otel(exporter: str = "console", service_name: str = "bd-scraper"):
resource = Resource.create(attributes={SERVICE_NAME: service_name})
provider = TracerProvider(resource=resource)
if exporter == "jaeger":
from opentelemetry.exporter.otlp.proto.http.trace_exporter import OTLPSpanExporter
endpoint = os.getenv("OTEL_EXPORTER_OTLP_ENDPOINT", "http://localhost:4318")
processor = BatchSpanProcessor(OTLPSpanExporter(endpoint=f"{endpoint}/v1/traces"))
else:
processor = BatchSpanProcessor(ConsoleSpanExporter())
provider.add_span_processor(processor)
trace.set_tracer_provider(provider)
RequestsInstrumentor().instrument() # điều kỳ diệu xảy ra ở đây!
return trace.get_tracer(service_name, "1.0.0")
Dòng duy nhất đó — RequestsInstrumentor().instrument() — móc vào thư viện requests một cách toàn cục. Mọi cuộc gọi HTTP mà mã của bạn thực hiện từ thời điểm này đều nhận được một trace span, bao gồm cả những mã trong thư viện bên thứ ba mà bạn không viết. Bạn có được thứ đó miễn phí.
Một điều sẽ làm bạn vấp ngã nếu không cẩn thận: init_otel phải chạy trước khi bất kỳ requests.Session nào được tạo. Điều đó có nghĩa là gọi nó trước khi nhập BrightDataClient trong điểm nhập của bạn.
Client với các Span tùy chỉnh
Truy vết HTTP tự động rất tuyệt, nhưng nó chỉ cho bạn biết về lớp truyền tải. Nó không có ý kiến rằng cuộc gọi này là cho truy vấn "machine learning", hoặc rằng nó nhắm vào google.com, hoặc rằng nó phải thử lại một lần trước khi hoạt động. Bối cảnh đó chính là mục đích của các span tùy chỉnh.
# ... mã nhập khẩu và khởi tạo lớp ...
def search(self, query: str, num_results: int = 10, ...):
from opentelemetry import trace
from opentelemetry.trace import StatusCode
tracer = trace.get_tracer(__name__, "1.0.0")
target_domain = "google.com"
with tracer.start_as_current_span("bright_data.search") as span:
span.set_attribute("scraper.query", query)
span.set_attribute("scraper.target_domain", target_domain)
span.set_attribute("scraper.num_results", num_results)
start = time.perf_counter()
last_err = None
for attempt in range(max_retries + 1):
try:
result = self._do_search(...)
latency_ms = (time.perf_counter() - start) * 1000
span.set_attribute("scraper.latency_ms", round(latency_ms, 2))
span.set_attribute("scraper.retries", attempt)
if attempt == 0:
span.set_status(StatusCode.OK)
else:
# đã khôi phục, nhưng chúng ta muốn nó hiển thị trong Jaeger
span.set_status(StatusCode.ERROR, "Recovered after retry")
return result
except Exception as e:
last_err = e
span.set_attribute("scraper.retries", attempt + 1)
if attempt < max_retries:
time.sleep(0.5 * (attempt + 1))
# tất cả các lần thử lại đã hết
span.set_attribute("scraper.error", str(last_err))
span.set_status(StatusCode.ERROR, str(last_err))
span.record_exception(last_err)
raise last_err
Hàm trợ giúp _do_search xây dựng URL mục tiêu và POST nó đến điểm cuối API của chúng ta. Khi cuộc gọi đó chạy, RequestsInstrumentor tự động tạo một span con POST bên trong span cha bright_data.search của chúng ta. Chúng chia sẻ cùng một trace_id.
Trong Jaeger, bạn sẽ nhận được một dòng thời gian phù hợp: hoạt động kinh doanh bên ngoài bao bọc cuộc gọi HTTP bên trong. Sự lồng ghép đó là điều làm cho traces thực sự hữu ích — bạn thấy cả câu chuyện, không chỉ là các sự kiện riêng lẻ.
Những gì traces thực sự cho thấy
Chạy nó ở chế độ console có vẻ bình thường: tất cả các truy vấn đều trả về kết quả, không có lỗi nào được in ra. Trông hoàn toàn khỏe mạnh... phải không? Hãy xem traces nói gì.
Truy vấn "data science" đã in ra 9 kết quả. Trừ khi traces cho thấy ba span cho cuộc gọi đơn đó. Cuộc gọi đó đã đạt đến thời gian chờ đọc 30 giây, chờ đợi cho retry backoff, thử lại lần nữa, và cuối cùng trả về dữ liệu — tốn của bạn hai yêu cầu proxy và 55 giây thay vì một yêu cầu và ~4 giây.
Bạn sẽ hoàn toàn không có ý tưởng từ chính đầu ra terminal. Điều này xảy ra thường xuyên hơn bạn nghĩ — các lỗi âm thầm hòa trộn với các cuộc gọi sạch xung quanh nó.
Đây là phân tích độ trễ trên tất cả năm truy vấn:
| Query | Latency | Retries |
|---|---|---|
| python programming | 3,686ms | 0 |
| machine learning | 6,558ms | 0 |
| web development | 3,079ms | 0 |
| data science | 55,113ms | 1 |
| cloud computing | 4,600ms | 0 |
Bốn trong số năm cuộc gọi là sạch. Một cái chậm hơn trung bình 15 lần và bạn chỉ biết điều đó vì bạn đang xem traces.
Đưa vào sản xuất với Jaeger
Console exporter rất tốt để phát triển, nhưng cho bất kỳ thứ gì thực sự chạy trong sản xuất, bạn muốn traces đi đến một nơi lưu trữ liên tục. Điểm bắt đầu dễ nhất là hình ảnh Docker all-in-one của Jaeger:
docker run -d --name jaeger \
-p 16686:16686 \
-p 4318:4318 \
jaegertracing/all-in-one:latest
Sau đó, bạn có thể chạy script của mình và mở http://localhost:16686 để tìm kiếm tên dịch vụ của bạn (ví dụ: bd-scraper). Bạn sẽ thấy mỗi span bright_data.search dưới dạng một hàng trong dòng thời gian trace với các span POST lồng nhau bên trong.
Truy vấn "data science" lại chậm một lần nữa, nhưng ít nhất là nó không thất bại? Những chiến thắng nhỏ. Nó nổi bật ngay lập tức trong giao diện người dùng Jaeger — một cái rộng hơn mọi thứ khác trên màn hình.
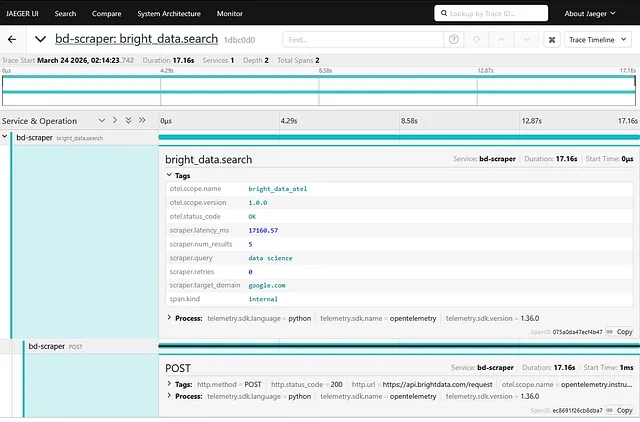 Chi tiết trace trong Jaeger
Chi tiết trace trong Jaeger
Bạn có thể mở rộng qua các trace tại đây đến mức độ chi tiết tinh tế bao nhiêu tùy thích. Đối với thiết lập thực tế, hãy thay thế Jaeger bằng bất kỳ backend nào bạn đang chạy. Grafana Tempo, Honeycomb, Datadog — exporter OTLP nói cùng một giao thức với tất cả chúng.
Việc thêm observability mang lại cho bạn khả năng hiển thị về những điều mà có thể bạn chưa từng nghĩ đến. Bạn không thể điều chỉnh những gì bạn không thể nhìn thấy.
Bài viết liên quan

Công nghệ
Các tác nhân AI đã khiến thế giới công nghệ chao đảo: Câu chuyện đằng sau cuộc cách mạng Claude Code và OpenClaw
26 tháng 5, 2026

Công nghệ
Threads cán mốc 500 triệu người dùng hoạt động hàng tháng
16 tháng 6, 2026

Công nghệ
Alienware 15 mới: Dell đang làm loãng thương hiệu cao cấp vì khủng hoảng RAM?
14 tháng 5, 2026