
Tại sao các công cụ tóm tắt LLM thường thất bại: Bài học về bước "Nhận dạng" từ Suy luận Nhân quả
Bài viết phân tích lý do các công cụ tóm tắt cuộc họp dựa trên LLM thường tạo ra thông tin sai lệch do bỏ qua bước "nhận dạng" dữ liệu. Tác giả đề xuất một kiến trúc pipeline mới với cơ chế kiểm toán nghiêm ngặt, chỉ cho phép làm yếu hoặc xóa các nhận định thay vì tô vẽ chúng, nhằm đảm bảo tính trung thực của bản tóm tắt.

Hãy tưởng tượng một công cụ tóm tắt cuộc họp lấy một đoạn trao đổi năm phút và trả về tám phần rõ ràng: Quyết định, Hành động cần làm, Rủi ro, Câu hỏi mở, v.v. Mỗi phần đọc rất trôi chảy, giống như được viết bởi một người đã chú ý lắng nghe toàn bộ cuộc thảo luận.
Tuy nhiên, khi đọc lại bản ghi âm (transcript) gốc, bạn sẽ phát hiện ra rằng hai trong số các phần đó được suy ra từ một câu duy nhất mơ hồ, một phần bịa đặt hoàn toàn, và ba phần khác chỉ là khớp mẫu từ dữ liệu huấn luyện trước đó của mô hình về những gì một bản tóm tắt nên có. Kết quả đầu nghe rất tự tin, định dạng đẹp mắt, về mặt cấu trúc không thể phân biệt được với một bản tóm tắt của cuộc họp thực sự nơi những điều đó đã xảy ra.
Đây không phải là vấn đề "ảo giác" (hallucination) theo nghĩa thông thường. Mô hình không bịa ra một sự thật về thế giới, mà nó đang bịa ra một sự thật về cuộc họp. Và chế độ thất bại này không hiển thị trong đầu ra. Đó chỉ là văn bản nghe có vẻ tự tin mà người đọc không thể dễ dàng xác minh dựa trên nguồn gốc.
Trong một lĩnh vực khác, có một tên gọi cho chế độ thất bại này, và nó cũ hơn nhiều so với các mô hình ngôn ngữ. Đó là điều xảy ra khi bạn thực hiện ước lượng mà không có sự nhận dạng (identification).
Bước bị thiếu: Nhận dạng (Identification) so với Ước lượng (Estimation)
Suy luận nhân quả (Causal inference) là truyền thống phân tích hình thức hóa sự khác biệt giữa việc nhận dạng một đại lượng và ước lượng nó. Nhận dạng là lập luận rằng dữ liệu bạn có thể hỗ trợ cho tuyên bố bạn muốn đưa ra. Ước lượng là quy trình tạo ra một con số khi việc nhận dạng đã được giải quyết. Thứ tự này không thể thương lượng. Bạn không thể ước lượng hiệu quả điều trị nếu bạn chưa lập luận rằng nó có thể nhận dạng được từ dữ liệu quan sát của mình, vì con số kết quả sẽ vô nghĩa.
Các nhà thực hành làm việc trong môi trường quan sát dành một phần lớn thời gian cho việc nhận dạng. Họ vẽ đồ thị nhân quả. Họ tranh luận về các yếu tố gây nhiễu (confounders). Họ phân biệt giữa những gì dữ liệu có thể hỗ trợ và những gì không thể. Bước ước lượng, khi cuối cùng đến, thường là phần dễ dàng.
Hãy xem xét những gì một công cụ tóm tắt LLM làm. Nó nhận một bản ghi âm. Nó tạo ra các tuyên bố có cấu trúc về nội dung của bản ghi đó: các quyết định được đưa ra, các cam kết được chấp nhận, các rủi ro được nêu ra, các bước tiếp theo được giao. Mỗi tuyên bố, theo một nghĩa thực sự, là một ước lượng của một đại lượng tiềm ẩn. Quyết định đã được đưa ra hoặc không. Cam kết đã được chấp nhận hoặc không. Bản tóm tắt đang khẳng định một giá trị cho mỗi đại lượng này.
Vấn đề là: Không có bước nhận dạng nào. Mô hình không hỏi liệu bản ghi có chứa đủ bằng chứng để hỗ trợ cho tuyên bố hay không. Nó tạo ra tuyên bố chỉ vì định dạng yêu cầu một cái.
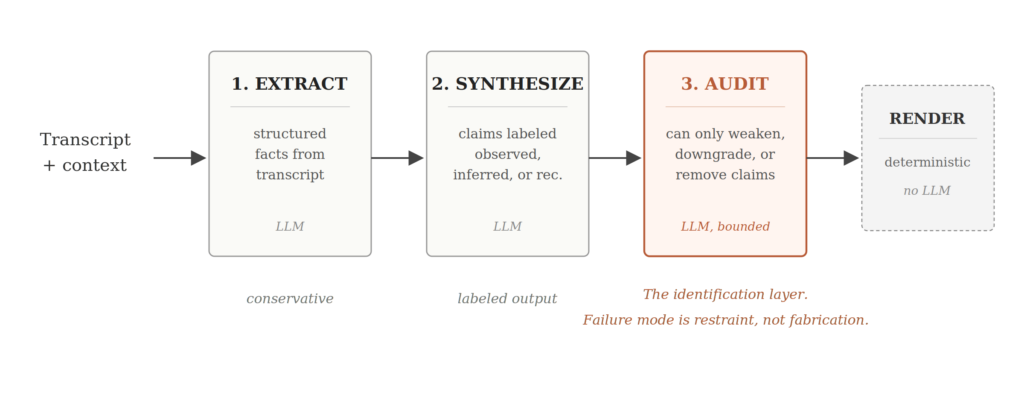 Kiến trúc Pipeline gồm 3 giai đoạn LLM và một bộ kết xuất xác định
Kiến trúc Pipeline gồm 3 giai đoạn LLM và một bộ kết xuất xác định
Một pipeline áp dụng kỷ luật nhận dạng
Để khắc phục vấn đề này, chúng ta cần một kiến trúc coi các bản tóm tắt do LLM tạo ra là các tuyên bố có cấu trúc trên một nguồn, yêu cầu mỗi tuyên bố phải khai báo danh mục hỗ trợ của nó, và hạn chế các giai đoạn xem xét để chúng chỉ có thể làm yếu các tuyên bố không được hỗ trợ thay vì làm cho đầu ra mượt mà hơn.
Kiến trúc đề xuất bao gồm ba giai đoạn LLM và một bộ kết xuất (renderer) xác định:
- Giai đoạn 1 - Trích xuất (Extraction): Trích xuất các sự kiện có cấu trúc từ bản ghi. Các lượt nói của người nói, các cam kết rõ ràng, các quyết định rõ ràng, các số lượng rõ ràng. Giai đoạn này được thiết kế một cách bảo thủ. Nó được phép bỏ sót things, nhưng không được phép bịa ra chúng.
- Giai đoạn 2 - Tổng hợp (Synthesis): Tổng hợp các sự kiện đó thành các đối tượng tuyên bố trên tám phần. Mỗi tuyên bố mang một nhãn: quan sát được (observed), suy luận (inferred), hoặc đề xuất (recommendation). Mỗi tuyên bố mang một con trỏ đến bằng chứng trong các sự kiện đã trích xuất. Đây là nơi công việc phân tích diễn ra và cũng là nơi mô hình có khả năng trôi đi nhất.
- Giai đoạn 3 - Kiểm toán (Audit): Đây là giai đoạn thực hiện công việc nhận dạng, và ràng buộc trên nó là phần quan trọng nhất của thiết kế.
Giai đoạn kiểm toán không được phép viết lại phân tích thành cái gì đó mượt mà hơn. Nó không thể thêm một đề xuất nghe hay hơn. Nó không thể bịa ra bối cảnh bị thiếu. Nó được cung cấp một tập hợp các thao tác bị chặn và bị cấm làm bất cứ điều gì khác.
 Năm thao tác mà giai đoạn kiểm toán được phép áp dụng
Năm thao tác mà giai đoạn kiểm toán được phép áp dụng
Nó có thể xóa một tuyên bố. Nó có thể hạ cấp một tuyên bố từ quan sát được xuống suy luận, hoặc từ suy luận xuống đề xuất. Nó có thể di chuyển một tuyên bố sang một phần phù hợp hơn. Nó có thể thay thế một tuyên bố bằng một trình giữ chỗ "bằng chứng không đủ" (insufficient-evidence). Nó có thể thu gọn toàn bộ một phần khi không có gì trong đó sống sót qua quá trình xem xét.
Tại sao sự bất đối xứng này lại quan trọng? Một người xem xét được phép cải thiện phân tích sẽ trở thành một nguồn khác của cùng một vấn đề mà hệ thống đang cố gắng giải quyết. Một người xem xét chỉ được phép làm yếu hoặc loại bỏ chỉ có thể thất bại theo một hướng: quá thận trọng. Đó là một chế độ thất bại có thể chấp nhận được. Điều ngược lại thì không.
Kết quả: Sự trung thực hơn là trôi chảy
Thiết kế này tạo ra kết quả gì? Trong các thử nghiệm với ba bản ghi âm khác nhau (một cuộc họp ra quyết định, một buổi làm việc về vấn đề đo lường, và một cuộc họp ngắn ít nội dung), pipeline đã tạo ra zero cam kết bịa đặt và zero số lượng không có căn cứ.
Kết quả thú vị hơn là tỷ lệ từ chối (abstention rate).
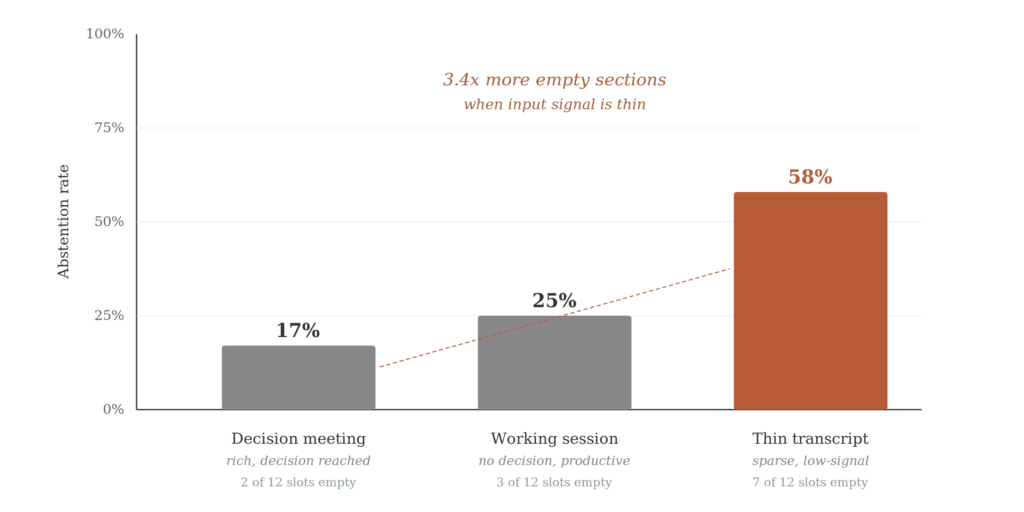 Tỷ lệ từ chối tăng lên khi tín hiệu đầu vào mỏng
Tỷ lệ từ chối tăng lên khi tín hiệu đầu vào mỏng
Trên cuộc họp ra quyết định phong phú, pipeline để lại mười bảy phần trăm các phần trống hoặc thay thế bằng trình giữ chỗ bằng chứng không đủ. Trên buổi làm việc, con số này tăng lên hai mươi lăm phần trăm. Trên cuộc họp ngắn, nó đạt năm mươi tám phần trăm. Hệ thống tạo ra khoảng ba lần rưỡi số lượng phần trống khi tín hiệu đầu vào mỏng so với khi phong phú.
Đó chính xác là hành vi mà thiết kế này hướng tới. Một công cụ tóm tắt lấp đầy cùng tám phần bất kể đầu vào không phải là đang tóm tắt. Nó đang tạo ra đầu ra phù hợp với một mẫu. Các phần trống không phải là thất bại của mô hình. Đó là mô hình từ chối khẳng định những gì nguồn không hỗ trợ.
Tổng kết và mở rộng
Có một lập luận cho rằng các phần trống là vấn đề về khả năng sử dụng. Người đọc mong đợi một bản tóm tắt hoàn chỉnh. Tuy nhiên, người đọc nhận được một bản tóm tắt trôi chảy tám phần của một cuộc trao đổi năm phút thực sự đang làm nhiều việc hơn, chỉ là vô hình. Họ sẽ đọc bản tóm tắt, hành động dựa trên nó, và tại một thời điểm nào đó phát hiện ra rằng hai trong số các hành động thực sự không được đồng ý và một rủi ro chưa bao giờ được nêu ra.
Sự trống rỗng trung thực đẩy chi phí đó lên phía trước. Người đọc thấy khoảng trống ngay lập tức và có thể quyết định cách xử lý nó: mở bản ghi, hỏi người tham gia, hoặc coi cuộc họp là chưa kết luận. Mỗi phản ứng đó đều tốt hơn là hành động dựa trên một bản tóm tắt tự tin được tạo ra từ một sự tự tin mà nguồn dữ liệu không xứng đáng có được.
Kiến trúc này có thể chuyển đổi sang bất kỳ quy trình công việc LLM nào tạo ra các tuyên bố có cấu trúc từ một nguồn: xem xét tài liệu pháp lý, tóm tắt ghi chú bệnh nhân, phân tích cuộc gọi khách hàng, tóm tắt xem xét mã nguồn. Tất cả đều có thể được kiểm toán tốt hơn với một kiến trúc tương tự: trích xuất bảo thủ, tổng hợp tạo ra các tuyên bố có nhãn với con trỏ bằng chứng, và kiểm toán bị cấm thêm hoặc củng cố bất cứ thứ gì.
Kỷ luật từ chối tạo ra một tuyên bố mà nguồn không hỗ trợ là điều đang thiếu ở nhiều hệ thống LLM hiện nay. Các kỹ thuật để làm cho các hệ thống phân tích LLM đáng tin cậy có thể không đến chủ yếu từ trong tài liệu LLM, mà từ các ngành khác như suy luận nhân quả, phương pháp điều tra, hoặc kế toán pháp y, nơi đã tìm ra việc phân tích trung thực dưới các điều kiện hạn chế là gì.
Bài viết liên quan

Phần mềm
Tối ưu hóa hệ thống gợi ý bằng LLM và Python: Cách cân bằng giữa tốc độ và độ chính xác
08 tháng 6, 2026

Phần mềm
Giám đốc Rimini Street: "Headless ERP" và mã nguồn mở là chìa khóa thoát khỏi sự kiểm soát của nhà cung cấp
16 tháng 6, 2026

Công nghệ
Amazon ra mắt tính năng Sleep Studio giúp trẻ em đi ngủ dễ dàng hơn trên loa Echo
10 tháng 6, 2026