
Tại sao Lịch trình Retraining MLOps Thường Thất bại: Mô hình Không "Quên", Chúng Bị "Sốc"
Phân tích trên 555.000 giao dịch gian lận cho thấy mô hình Machine Learning trong môi trường thực tế thường không suy giảm hiệu suất một cách êm dịu mà gặp phải những "cú sốc" đột ngột. Kết quả này bác bỏ giả thuyết về đường cong quên lãng (forgetting curve) và khẳng định rằng việc retraining theo lịch cố định là lãng phí, thay vào đó cần chuyển sang cơ chế phát hiện cú sốc dựa trên sự kiện.

Tại sao Lịch trình Retraining MLOps Thường Thất bại: Mô hình Không "Quên", Chúng Bị "Sốc"
Hầu hết các kỹ sư MLOps đều mặc định rằng hiệu suất của mô hình Machine Learning sẽ suy giảm dần theo thời gian, giống như con người quên kiến thức theo đường cong Ebbinghaus. Tuy nhiên, thực tế dữ liệu từ môi trường sản xuất (production) lại cho thấy một bức tranh hoàn toàn khác: các mô hình không "quên" từ từ, chúng bị "sốc" và thất bại đột ngột.
Khi áp dụng đường cong suy giảm hàm mũ (exponential forgetting curve) vào 555.000 giao dịch gian lận mô phỏng môi trường thực, kết quả thu được là R² = −0.31. Con số này thậm chí còn tệ hơn cả việc dự đoán bằng một đường thẳng trung bình. Điều này giải thích tại sao việc lên lịch retraining (huấn luyện lại) theo lịch cố định hàng tháng hay hàng tuần thường thất bại trong thực tế.
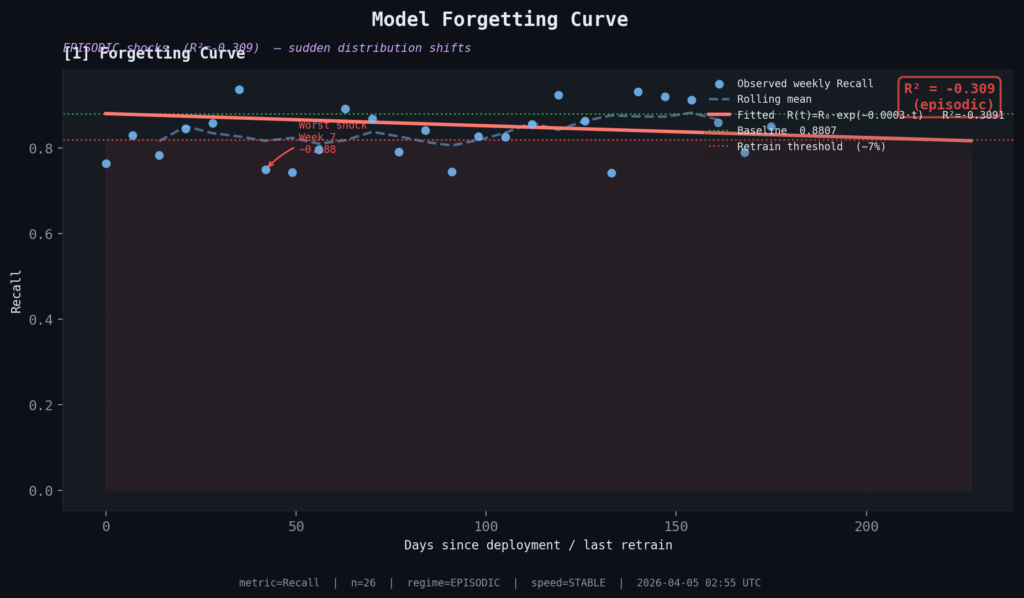 Đường cong quên lãng không khớp với dữ liệu thực tế
Đường cong quên lãng không khớp với dữ liệu thực tế
Chẩn đoán trước khi lên lịch
Trước khi thiết lập bất kỳ lịch trình retraining nào, bạn cần chạy một chẩn đoán nhanh 3 dòng code trên các chỉ số hàng tuần hiện có để xác định chế độ hoạt động của mô hình:
report = tracker.report()
print(report.forgetting_regime) # "smooth" hoặc "episodic"
print(report.fit_r_squared) # Giá trị R²
Nếu R² ≥ 0.4, hệ thống ở chế độ Smooth (Mượt mà). Mô hình suy giảm dự đoán được và bạn có thể lên lịch retraining an toàn dựa trên tốc độ suy giảm.
Tuy nhiên, nếu R² < 0.4, hệ thống ở chế độ Episodic (Đoạn tính/Gián đoạn). Trong trường hợp này, mô hình suy giảm hàm mũ hoàn toàn vô nghĩa. Thời gian bán hủy (half-life) có thể lên tới hàng nghìn ngày, nhưng mô hình vẫn có thể sụp đổ bất ngờ chỉ trong một tuần. Lúc này, bạn cần bỏ qua lịch trình cố định và triển khai cơ chế phát hiện cú sốc (shock detection).
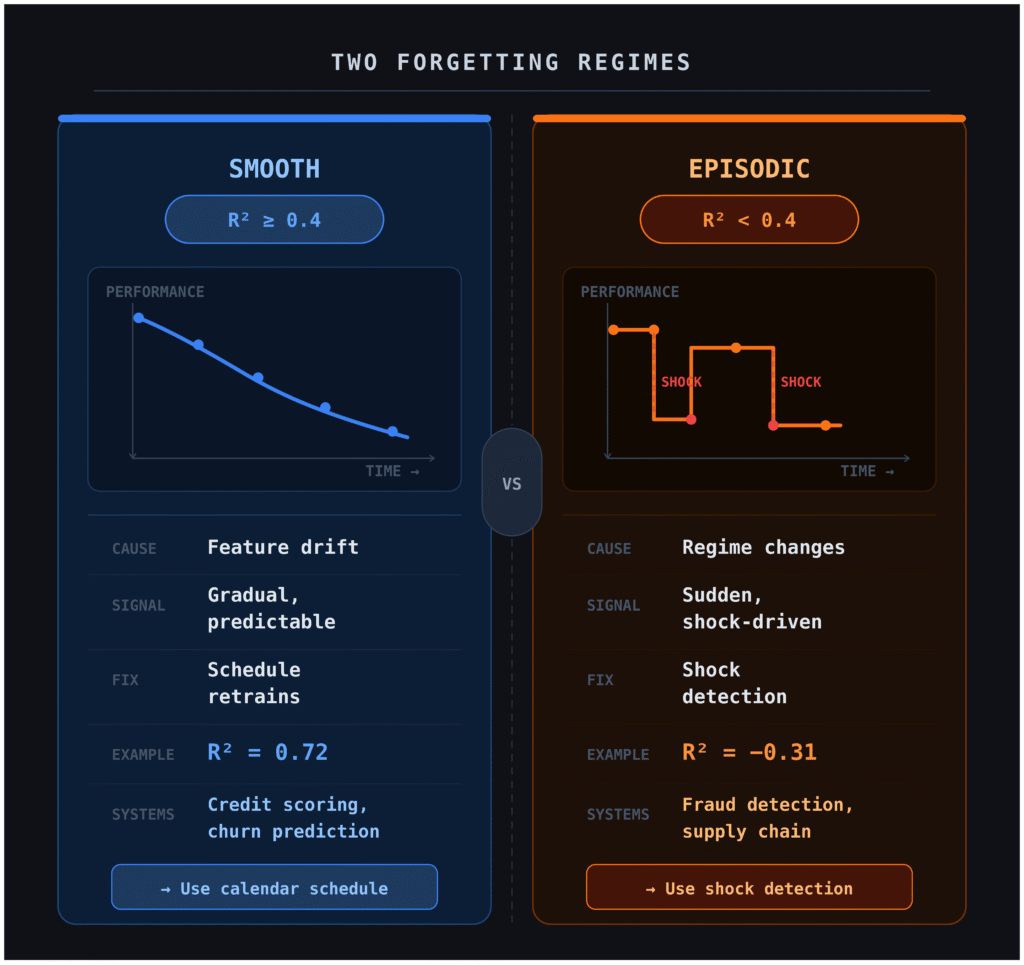 So sánh chế độ suy giảm mượt mà và gián đoạn
So sánh chế độ suy giảm mượt mà và gián đoạn
Tại sao lịch trình cố định thất bại?
Trong chế độ Episodic, hiệu suất của mô hình không đi xuống dần đều mà có những đợt sụt giảm nghiêm trọng và khó lường trước. Ví dụ, trong dữ liệu phân tích, có một tuần hiệu suất Recall giảm tới 18.75 điểm, trong khi các tuần khác vẫn ổn định.
Nếu chỉ nhìn vào biểu đồ tổng hợp hàng tháng, các đợt sụt giảm này sẽ bị che mờ bởi sự ổn định trung bình. Một lịch trình retraining theo lịch dương lịch sẽ vô dụng vì:
- Nó kích hoạt retraining vào những lúc mô hình đang ổn định (lãng phí tài nguyên).
- Nó bỏ lỡ những thời điểm "cú sốc" thực sự xảy ra giữa các mốc retraining.
 Bộ đếm ngược retraining trở nên vô nghĩa trong chế độ gián đoạn
Bộ đếm ngược retraining trở nên vô nghĩa trong chế độ gián đoạn
Giải pháp: Retraining dựa trên sự kiện (Event-driven)
Thay vì retraining theo lịch, trong chế độ Episodic, hãy thay thế bằng ba cơ chế phát hiện sau:
- Bộ phát hiện cú sốc theo tuần: So sánh Recall của tuần hiện tại với trung bình trượt 4 tuần trước đó. Nếu Recall giảm hơn 8% so với trung bình, kích hoạt cảnh báo.
- Recall có trọng số theo khối lượng: Sử dụng trung bình có trọng số của Recall dựa trên số lượng giao dịch gian lận trong tuần đó. Điều này tránh việc các tuần có ít dữ liệu gây nhiễu.
- Kích hoạt liên tiếp hai tuần: Chỉ thực sự retrain khi hiệu suất thấp ngưỡng trong hai tuần liên tiếp. Điều này giúp giảm thiểu các cảnh báo giả dương (false alarms) do nhiễu ngắn hạn.
# Cơ chế 1: Bộ phát hiện cú sốc
rolling_mean = recall_series.rolling(window=4).mean()
shock_flags = recall_series < (rolling_mean * 0.92)
# Cơ thể 2: Recall có trọng số
weighted_recall = np.average(recall_series, weights=fraud_counts)
# Cơ thể 3: Kích hoạt liên tiếp
breach = recall_series < (recall_series.mean() * (1 - 0.07))
retrain_trigger = breach & breach.shift(1).fillna(False)
Kết luận cho thực hành MLOps
Sự khác biệt giữa chế độ Smooth và Episodic là then chốt để xây dựng chiến lược MLOps hiệu quả.
Đối với hệ thống Smooth, hãy tiếp tục sử dụng lịch trình retraining, nhưng hãy điều chỉnh tần suất dựa trên tốc độ suy giảm thực nghiệm (decay rate) thay vì theo quy ước hàng tháng.
Đối với hệ thống Episodic, việc retraining theo lịch là lãng phí vận hành. Hãy chuyển sang retraining dựa trên sự kiện, được kích hoạt bởi các cú sốc đột ngột trong dữ liệu. Chẩn đoán R² là công cụ đơn giản giúp bạn quyết định nên mở hộp công cụ nào cho mô hình của mình.
Đừng để những chỉ số tổng hợp đánh lừa. Hãy chạy chẩn đoán chi tiết để hiểu rõ hành vi của mô hình trước khi thiết lập bất kỳ quy trình tự động hóa nào.
Bài viết liên quan

Phần cứng
Gemma 4 áp dụng Multi-Token Prediction, tăng tốc độ suy luận lên tới 3 lần
25 tháng 5, 2026

Công nghệ
Các tác nhân AI đã khiến thế giới công nghệ chao đảo: Câu chuyện đằng sau cuộc cách mạng Claude Code và OpenClaw
26 tháng 5, 2026

Phần cứng
Nvidia chính thức đưa siêu vi xử lý Grace Blackwell lên PC với dòng notebook RTX Spark
01 tháng 6, 2026