
Tạm biệt Vector Database: Xây dựng trí nhớ AI cho Obsidian với Pattern Memory Agent của Google
Bài viết chia sẻ cách xây dựng hệ thống trí nhớ AI bền vững mà không cần Vector Database phức tạp. Tận dụng cửa sổ ngữ cảnh lớn của LLM hiện đại, tác giả áp dụng Memory Agent Pattern để quản lý ghi chú Obsidian hiệu quả hơn và chính xác hơn so với phương pháp RAG truyền thống.

Mọi chuyện bắt đầu khi trợ lý AI trên Obsidian của tôi liên tục bị "mất trí nhớ". Tôi không muốn phải dựng lên một server Pinecone hay Redis phức tạp chỉ để Claude có thể nhớ rằng Alice đã duyệt ngân sách quý III vào tuần trước. Và hóa ra, với các cửa sổ ngữ cảnh (context window) lên tới hơn 200K token hiện nay, có thể chúng ta hoàn toàn không cần những thứ đó.
Tôi muốn chia sẻ một cơ chế mới mà tôi đang áp dụng. Đó là một hệ thống được xây dựng dựa trên SQLite và khả năng suy luận trực tiếp của LLM, hoàn toàn không sử dụng cơ sở dữ liệu vector (Vector DB), không có pipeline xử lý embeddings. Trước đây, tìm kiếm vector chủ yếu là một giải pháp thay thế cho các cửa sổ ngữ cảnh quá nhỏ nhằm tránh việc câu lệnh (prompt) trở nên rối rắm. Nhưng với kích thước ngữ cảnh khổng lồ của các mô hình hiện đại, bạn có thể bỏ qua bước đó và chỉ cần để mô hình đọc trực tiếp các "kỷ niệm" của bạn.
 Mô hình kiến trúc Memory Agent
Mô hình kiến trúc Memory Agent
Bối cảnh và Vấn đề
Tôi có thói quen ghi chép rất chi tiết, cả trong cuộc sống cá nhân và công việc. Trước đây tôi dùng sổ tay, nhưng chúng thường bị thất lạc hoặc bỏ quên trên kệ. Một vài năm gần đây, tôi chuyển sang sử dụng Obsidian cho mọi thứ và nó thật tuyệt vời. Trong năm qua, tôi bắt đầu kết nối genAI vào các ghi chú của mình.
Tôi sử dụng cả Claude Code (cho ghi chú cá nhân) và Kiro-CLI (cho ghi chú công việc). Tôi có thể đặt câu hỏi, yêu cầu tổng hợp báo cáo cho lãnh đạo, theo dõi mục tiêu và viết báo cáo. Nhưng nó luôn có một điểm yếu chí mạng: trí nhớ. Khi tôi hỏi về một cuộc họp, nó sử dụng Obsidian MCP để tìm kiếm trong kho lưu trữ (vault). Quá trình này tốn thời gian, dễ sai sót và tôi cần nó tốt hơn.
Giải pháp hiển nhiên là sử dụng Vector Database. Mã hóa kỷ niệm (embeddings), lưu trữ vector và thực hiện tìm kiếm tương đồng (similarity search) khi truy vấn. Cách này hoạt động, nhưng đồng nghĩa với việc bạn cần một Redis stack, tài khoản Pinecone, hoặc một instance Chroma chạy cục bộ, cộng thêm API embedding và mã pipeline để kết nối mọi thứ. Đối với một công cụ cá nhân, đó là quá nhiều rắc rối. Hơn nữa, tôi cần hỏi những câu như "đã xảy ra chuyện gì vào ngày 1/2/2026" hoặc "tóm tắt cuộc họp gần nhất tôi có với người này", những thứ mà embeddings và RAG không thực sự xuất sắc.
Giải pháp: Memory Agent Pattern của Google
Sau đó, tôi tìm thấy dự án "always-on-memory-agent" của Google Cloud Platform. Ý tưởng rất đơn giản: hoàn toàn không thực hiện tìm kiếm tương đồng; chỉ cần cung cấp các kỷ niệm gần đây cho LLM và để nó tự suy luận.
Tôi muốn kiểm tra xem cách này có hoạt động tốt trên AWS Bedrock với Claude Haiku 4.5 hay không. Vì vậy, tôi đã xây dựng nó (tất nhiên là với sự trợ giúp của Claude Code) và thêm vào một số tính năng mở rộng.
Một Sự Thay Đổi Trong Tư Duy
Các mô hình cũ giới hạn ở 4K hoặc 8K token. Bạn không thể nhét nhiều tài liệu vào một câu lệnh. Embeddings giúp bạn truy xuất tài liệu liên quan mà không cần tải tất cả. Đó là điều thực sự cần thiết lúc bấy giờ. Tuy nhiên, Haiku 4.5 cung cấp cửa sổ ngữ cảnh lên tới 250k token, vậy chúng ta có thể làm gì với điều đó?
Một kỷ niệm có cấu trúc (tóm tắt, thực thể, chủ đề, điểm quan trọng) chiếm khoảng 300 token. Điều này có nghĩa là chúng ta có thể tải khoảng 650 kỷ niệm trước khi chạm trần. Trong thực tế, con số này thấp hơn một chút do câu lệnh hệ thống và truy vấn cũng tiêu tốn token, nhưng đối với một trợ lý cá nhân theo dõi các cuộc họp, ghi chú và cuộc trò chuyện, đó là bối cảnh của nhiều tháng trời.
Không embeddings, không chỉ mục vector, không độ tương đồng cosine. LLM suy luận trực tiếp trên ngữ nghĩa, và nó làm việc này tốt hơn cosine similarity.
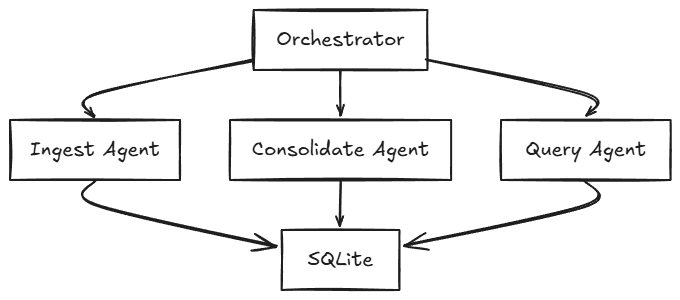
Kiến trúc Hệ thống
Orchestrator không phải là một dịch vụ riêng biệt. Nó là một lớp Python bên trong quy trình FastAPI điều phối ba tác nhân (agent):
-
IngestAgent: Nhiệm vụ đơn giản: lấy văn bản thô và hỏi Haiku điều gì đáng nhớ. Nó trích xuất tóm tắt, thực thể (tên, địa điểm, sự vật), chủ đề và điểm quan trọng từ 0 đến 1. Gói thông tin này được đưa vào bảng
memories. -
ConsolidateAgent: Chạy với lịch trình thông minh: khi khởi động nếu có kỷ niệm tồn tại, khi đạt ngưỡng (mặc định là 5+ kỷ niệm), và hàng ngày như một lần buộc phải chạy. Khi được kích hoạt, nó lấy các kỷ niệm chưa hợp nhất và yêu cầu Haiku tìm các kết nối chéo và tạo ra thông tin chi tiết (insights). Kết quả được lưu vào bảng
consolidations. -
QueryAgent: Đọc các kỷ niệm gần đây cộng với thông tin chi tiết từ hợp nhất vào một câu lệnh duy nhất và trả về câu trả lời đã tổng hợp kèm theo ID trích dẫn.
Dữ Liệu Được Lưu Trữ Như Thế Nào
Khi bạn nhập văn bản như "Hôm nay gặp Alice. Ngân sách Q3 được duyệt, 2,4 triệu USD", hệ thống không chỉ đổ chuỗi thô đó vào cơ sở dữ liệu. Thay vào đó, IngestAgent gửi nó cho Haiku và hỏi "Điều gì quan trọng ở đây?".
LLM trích xuất siêu dữ liệu có cấu trúc, bao gồm tóm tắt, thực thể, chủ đề và điểm quan trọng.
Bảng memories giữ các bản ghi riêng lẻ này. Với khoảng 300 token mỗi kỷ niệm khi định dạng vào câu lệnh, trần lý thuyết là khoảng 650 kỷ niệm trong cửa sổ ngữ cảnh 200K của Haiku. Tôi cố ý đặt mặc định là 50 kỷ niệm gần đây để đảm bảo an toàn.
Khi ConsolidateAgent chạy, nó không chỉ tóm tắt. Nó suy luận về chúng, tìm ra các mẫu (patterns), vẽ ra các kết nối và tạo ra thông tin chi tiết về ý nghĩa của các kỷ niệm đó. Các thông tin chi tiết này được lưu trữ dưới dạng bản ghi riêng trong bảng consolidations.
Khi bạn truy vấn, hệ thống tải cả kỷ niệm thô và thông tin chi tiết từ hợp nhất vào cùng một câu lệnh. LLM suy luận trên cả hai lớp cùng lúc, bao gồm cả sự kiện gần đây và các mẫu đã tổng hợp. Đó là cách bạn nhận được câu trả lời như: "Alice đã nêu lo ngại về ngân sách trong ba cuộc họp riêng biệt [memory:a3f1c9d2...] và mẫu này cho thấy đó là mức độ ưu tiên cao [consolidation:3c765a26]".
Thiết kế hai bảng này là toàn bộ lớp lưu trữ (persistence layer). Chỉ một file SQLite duy nhất. Không Redis. Không Pinecone. Không pipeline embedding. Chỉ các bản ghi có cấu trúc mà LLM có thể suy luận trực tiếp.
Tại Sao Không Cần Vector DB?
Việc bạn có cần embeddings cho ghi chú cá nhân hay không phụ thuộc vào hai yếu tố: bạn có bao nhiêu ghi chú và bạn muốn tìm kiếm chúng như thế nào.
Tìm kiếm vector thực sự cần thiết khi bạn có hàng triệu tài liệu và không thể vừa các tài liệu liên quan trong ngữ cảnh. Đó là một tối ưu hóa truy xuất cho các vấn đề quy mô lớn.
Ở quy mô cá nhân, bạn đang làm việc với hàng trăm kỷ niệm, không phải hàng triệu. Vector có nghĩa là bạn đang chạy pipeline embedding, trả tiền cho API calls, quản lý chỉ mục và triển khai tìm kiếm tương đồng để giải quyết một vấn đề mà cửa sổ ngữ cảnh 200K đã giải quyết được.
Đối với các ghi chú cá nhân, tôi không thể biện minh cho việc phải cài đặt và duy trì cơ sở dữ liệu vector, ngay cả khi là FAISS.
Theo Dõi Tệp và Phát Hiện Thay Đổi
Tôi có một kho lưu trữ Obsidian với hàng trăm ghi chú và tôi không muốn nhập thủ công từng cái. Tôi muốn trỏ trình theo dõi (watcher) vào kho lưu trữ và để nó xử lý phần còn lại.
Khi khởi động, trình theo dõi quét thư mục và nhập mọi thứ nó chưa thấy trước đó. Nó chạy hai chế độ trong nền:
- Quét nhanh mỗi 60 giây để kiểm tra tệp mới.
- Quét đầy đủ mỗi 30 phút, tính toán băm SHA256 và so sánh với giá trị đã lưu. Nếu tệp thay đổi, hệ thống xóa kỷ niệm cũ, dọn dẹp các hợp nhất tham chiếu đến chúng, nhập lại phiên bản mới và cập nhật bản ghi theo dõi.
Chỉnh sửa một ghi chú trong Obsidian, và trong vòng 30 phút, bộ nhớ của tác nhân sẽ phản ánh sự thay đổi đó.
Cách Sử Dụng
Dự án có sẵn trên GitHub (ProtoGensis/memory-agent-bedrock). Viết bằng Python, không có phụ thuộc lạ mắt, chỉ có boto3, FastAPI và SQLite. Mô hình mặc định là us.anthropic.claude-haiku-4-5-20251001-v1:0 trên AWS Bedrock.
Bạn có thể cấu hình qua file .env và khởi động server bằng script có sẵn.
Để tương tác, dự án cung cấp hai đường dẫn:
- Claude Code / Kiro-CLI skill: Tự kích hoạt khi liên quan. Nói "nhớ rằng Alice đã duyệt ngân sách Q3" và nó sẽ lưu mà không cần bạn gọi lệnh. Hỏi "Alice nói gì về ngân sách?" vào tuần sau và nó sẽ kiểm tra bộ nhớ trước khi trả lời.
- CLI: Dành cho người dùng terminal hoặc scripting để nhập liệu, truy vấn và kiểm tra trạng thái.
Kết Luận
Nếu bạn đang xây dựng công cụ AI cá nhân và đang gặp khó khăn với vấn đề bộ nhớ, mẫu Memory Agent này đáng để xem xét. Với việc tận dụng tối đa cửa sổ ngữ cảnh lớn và khả năng suy luận của các mô hình mới, chúng ta có thể đơn giản hóa kiến trúc hệ thống, loại bỏ sự phụ thuộc vào các Vector Database phức tạp mà vẫn đạt được hiệu suất cao ở quy mô cá nhân.
Dự án này là một minh chứng cho thấy đôi khi, giải pháp tốt nhất không phải là thêm vào nhiều công nghệ hơn, mà là biết cách tận dụng triệt để sức mạnh của những công nghệ hiện có.
Bài viết liên quan

Công nghệ
Các tác nhân AI đã khiến thế giới công nghệ chao đảo: Câu chuyện đằng sau cuộc cách mạng Claude Code và OpenClaw
26 tháng 5, 2026

Công nghệ
Alienware 15 mới: Dell đang làm loãng thương hiệu cao cấp vì khủng hoảng RAM?
14 tháng 5, 2026

Công nghệ
Pinterest áp dụng "vân tay nội dung" để loại bỏ URL trùng lặp trên hàng triệu tên miền
08 tháng 6, 2026