
Thay thế GPT-4 bằng SLM cục bộ: Cách tôi chấm dứt sự cố trong pipeline CI/CD
Bài viết chia sẻ hành trình chuyển đổi từ GPT-4 sang mô hình ngôn ngữ nhỏ (SLM) cục bộ để xử lý dữ liệu có cấu trúc trong pipeline CI/CD. Mặc dù GPT-4 mạnh mẽ, tính ngẫu nhiên của nó gây ra các lỗi khó chịu, trong khi SLM cục bộ với tính xác định (determinism) đã mang lại sự ổn định tuyệt đối cho hệ thống.
Tôi đang viết lại lần thứ 7 cho cùng một câu lệnh hệ thống (system prompt).
"Bạn PHẢI trả về ĐÚNG JSON hợp lệ. Không markdown. Không code fences. Không giải thích. CHỈ đối tượng JSON."
Tôi đã viết từ PHẢI in hoa. Với một mô hình ngôn ngữ. Như việc nhấn mạnh sẽ tác động đến thứ không có cảm xúc hoặc, dường như, không có định nghĩa nhất quán về "JSON hợp lệ".
Nó không hiệu quả. Nhưng điều dưới đây thì có.
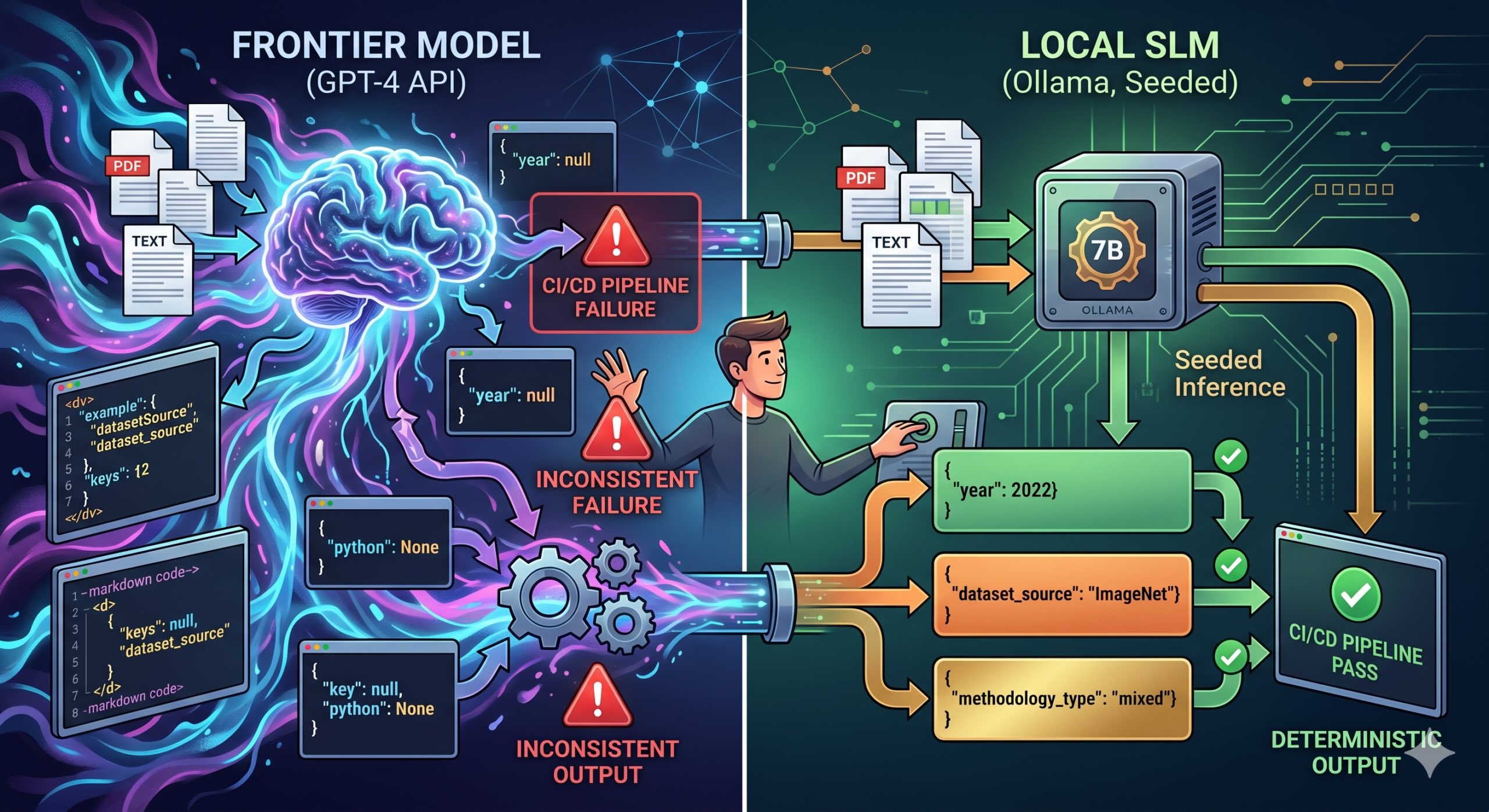
Cách GPT-4 xuất hiện trong một công việc hàng loạt (Batch Job)
Đội ngũ của chúng tôi tiêu thụ các tài liệu nghiên cứu, chẳng hạn như PDF và văn bản thuần túy, thỉnh thoảng là những báo cáo bán cấu trúc khó chịu mà một nhà cung cấp nào đó rõ ràng đã xuất từ bảng tính mà họ rất tự hào. Một phần của pipeline này phân loại chúng và trích xuất các trường có cấu trúc trước khi bất kỳ thứ gì chạm vào kho dữ liệu (data warehouse). Loại phương pháp luận, nguồn dữ liệu, các chỉ số chính.
Nghe có vẻ như một vấn đề đã được giải quyết. Thường là vậy, cho đến khi có khoảng bốn mươi loại phương pháp được liệt kê và các tài liệu không còn giống bất kỳ thứ gì bạn đã từng đào tạo.
Một thời gian, chúng tôi xử lý việc này bằng cách sử dụng regex, bộ trích xuất dựa trên quy tắc và mô hình BERT tinh chỉnh (fine-tuned). Điểm tốt là nó hoạt động, nhưng việc bảo trì nó cảm giác như sửa một tệp CSS từ năm 2015, nơi bạn chạm vào một quy tắc và một thứ không liên quan bị hỏng trên một trang mà bạn đã không ghé thăm trong nhiều tháng.
Vì vậy, khi GPT-4 xuất hiện, chúng tôi đã thử nó.
Thành thật mà nói, nó thực sự đáng kinh ngạc. Các trường hợp ngoại lệ (edge cases) khiến BERT điên đảo trong nhiều tháng, các định dạng chúng tôi chưa từng thấy, và các tài liệu có các phần không nhất quán đều được GPT-4 xử lý sạch sẽ.
Buổi demo của đội ngũ diễn ra tốt đẹp. Ý là, có người thậm chí còn nói "wow" thành tiếng.
Tối hôm đó, tôi nhắn tin cho quản lý: "nghĩ là chúng tôi đã giải quyết được vấn đề trích xuất". Được gửi với sự tự tin.
Hai tuần sau khi chúng tôi triển khai, các lỗi bắt đầu xuất hiện.
Vấn đề với sự "ổn định phần lớn"
Theo kinh nghiệm của tôi, GPT-4 có khả năng nhưng là phi xác định (non-deterministic).
Đối với nhiều trường hợp sử dụng, tính phi xác định không quan trọng. Nhưng đối với một pipeline hàng loạt hàng đêm cung cấp dữ liệu cho kho dữ liệu, nó quan trọng rất nhiều.
Ở temperature=0, bạn nhận được đầu ra phần lớn nhất quán. Trong bối cảnh CI/CD, "phần lớn" có nghĩa là "nó sẽ bị hỏng vào một ngày thứ Sáu".
Các lỗi cũng không kịch tính; nếu không, việc gỡ lỗi sẽ dễ dàng hơn. GPT-4 không bị ảo giác các trường hay trả về rác.
Nó làm những điều tinh tế. "dataset_source" một đêm, "datasetSource" đêm sau, "source_dataset" đêm hôm sau. Các hàng rào code fence markdown bao quanh JSON mặc dù chúng tôi đã bảo nó không làm vậy, qua mọi phiên bản của prompt. Các số được trả về dưới dạng chuỗi. JSON null được trả về dưới dạng chuỗi Python "None"; tôi đã dành nhiều thời gian hơn mức tôi muốn thừa nhận để nhìn chằm chằm vào cái đó.
Mỗi lỗi đều theo cùng một nghi thức.
Pydantic bắt lỗi ở hạ nguồn, pipeline thất bại, tôi xác nhận đó là một quirk định dạng khác, sau đó tôi bắt tay vào làm việc ngay lập tức để chạy lại thủ công. Nó vượt qua, rồi khoảng ba ngày sau, một quirk khác lại xuất hiện.
Vì vậy tôi bắt đầu giữ một nhật ký. Sáu tuần trôi qua:
- 23 lỗi pipeline do sự không nhất quán của đầu ra GPT-4.
- ~18 phút trung bình để chẩn đoán và chạy lại.
- 0 lỗi thực tế trong mã pipeline.
Không có lỗi thực sự nào. Mọi lần thất bại đều là do mô hình khác biệt một cách tinh tế so với những gì nó đã là đêm trước. Đó là con số khiến tôi ngừng bảo vệ thiết lập này.
Những gì tôi đã thử trước khi thừa nhận vấn đề thực sự
Viết Prompt (Prompting)
Bảy lần viết lại trong hai ngày.
Tôi thậm chí không nhận ra nó đã nhiều đến thế. Tôi chỉ muốn một bản sửa tốt. Và nó thậm chí không dừng lại ở đó.
Tôi đã thử hướng dẫn in hoa, ví dụ few-shot, và các phản ví dụ với tiêu đề "ĐỪNG làm điều này". Tôi thậm chí còn thử thêm một lời nhắc ở cuối thông điệp người dùng như một cú hích cuối cùng, như thể mô hình sẽ đến dòng đó và nghĩ ô đúng rồi, chỉ JSON thôi, suýt nữa thì quên.
Một thời điểm, cùng một hướng dẫn xuất hiện ở ba nơi khác nhau trong cùng một prompt, và tôi thực sự nghĩ rằng có thể giúp ích. Các lỗi tiếp diễn, không thay đổi.
Bộ phân tích dọn dẹp (Cleanup parser)
Khi viết prompt thất bại, tôi viết mã để dọn dẹp mọi lộn xộn mà GPT-4 ném lại cho tôi.
Loại bỏ markdown fences, tìm đối tượng JSON nếu nó bị chôn vùi trong văn bản, và ghi lại đầu ra thô khi không có gì hoạt động.
Phương pháp này thực sự hoạt động được khoảng một tuần, đủ thời gian để tôi cảm thấy tốt về nó.
Sau đó GPT-4 bắt đầu trả về JSON cấu trúc hợp lệ nhưng với tên khóa sai, camelCase thay vì snake_case. Bộ phân tích cho nó qua tốt, và lỗi xuất hiện ba bước sau đó.
Tôi đang chơi trò đập chuột (whack-a-mole) với một mô hình có vô số con chuột.
response_format + temperature=0
response_format={"type": "json_object"} của OpenAI kết hợp với temperature=0 đã giảm lỗi từ 23 xuống khoảng 9. Tiến bộ có ý nghĩa. Vẫn chưa bằng không, và "chín lỗi ngẫu nhiên mỗi sáu tuần" không phải là thuộc tính pipeline mà tôi có thể bảo vệ.
Function calling
Đây là cái gần như hoạt động. Ép đầu ra qua một hợp đồng lược đồ kiểu (typed schema contract) thực sự đã thắt chặt mọi thứ.
Tôi ngừng kiểm tra nhật ký mỗi sáng, ngừng chuẩn bị cho thông báo Slack. Nói với một người trong đội ngũ rằng nó ổn định. Điều mà, nếu bạn làm việc trong phần mềm, bạn biết đó là cách nhanh nhất để gây xui xẻo cho một cái gì đó.
Sau đó, một ngày thứ Ba, API OpenAI có sự cố gián đoạn 20 phút. Pipeline thất bại nặng nề; không phải là vấn đề mô hình, chỉ là sự phụ thuộc mạng mà chúng tôi chưa bao giờ tính toán đúng.
Chúng tôi không thể khóa phiên bản mô hình, không thể chạy ngoại tuyến, không thể trả lời câu hỏi "điều gì đã thay đổi giữa lần chạy hoạt động và lần chạy không?" vì mô hình ở đầu kia không phải của chúng tôi.
Ngồi đó chờ API của người khác hồi phục, tôi cuối cùng đã đặt câu hỏi mà tôi lẽ ra nên hỏi từ nhiều tháng trước: Công việc cụ thể này có thực sự cần một mô hình tiên phong (frontier model) không?
Các mô hình cục bộ tốt hơn tôi mong đợi
Tôi bước vào với kỳ vọng đầy đủ rằng sẽ dành một ngày để xác nhận chúng không đủ tốt. Tôi đã có một kết luận sẵn sàng trước khi chạy bất kỳ bài kiểm tra nào: đã thử, chất lượng không ở đó, ở lại GPT-4 với logic thử lại tốt hơn. Một câu chuyện mà quyết định đầu tiên vẫn có thể bảo vệ.
Mất khoảng ba giờ để nhận ra tôi đã suy nghĩ sai về vấn đề này.
Việc trích xuất tài liệu vào một lược đồ cố định thực sự không phải là một nhiệm vụ khó đối với mô hình ngôn ngữ. Không phải theo cách làm cho một mô hình tiên phong trở nên cần thiết. Không có suy luận (reasoning) liên quan, không có tổng hợp, không cần sự phong phú của kiến thức thế giới làm cho GPT-4 xứng đáng với giá tiền của nó.
Nó thực sự là: hiểu đọc có cấu trúc. Mô hình đọc một tài liệu và điền vào các trường. Một mô hình 7B được đào tạo tốt làm tốt việc này. Và với thiết lập đúng, cụ thể là suy luận có gieo hạt (seeded inference), nó làm điều đó giống hệt nhau mỗi lần chạy.
Tôi đã chạy bốn mô hình chống lại 50 tài liệu tôi đã chú thích thủ công:
- Phi-3-mini (3.8B): Tuân thủ hướng dẫn tốt hơn tôi mong đợi cho một mô hình 3.8B, nhưng nó bị vỡ vụn trên bất kỳ thứ gì quá khoảng 3.000 token. Tôi gần như chọn cái này trước khi tôi nhìn vào kết quả tài liệu dài hơn.
- Mistral 7B Instruct: Vững chắc ở khắp mọi nơi, không có bất ngờ thực sự theo bất kỳ hướng nào. Chiếc Toyota Camry của các mô hình cục bộ. Bạn sẽ ổn với cái này.
- Qwen2.5-7B-Instruct: Cái này thắng rõ ràng. Tính nhất quán đầu ra có cấu trúc tốt nhất trong số bốn mô hình với khoảng cách đủ rộng để không phải là một cuộc cạnh tranh sát nút.
- Llama 3.2 3B Instruct: Cái này nhanh, nhưng chất lượng trích xuất giảm đủ nhiều trên các trường hợp ngoại lệ để tôi sẽ không chạy nó trên dữ liệu sản xuất mà không có nhiều công việc xác nhận hơn trước.
Cả Qwen2.5 và Mistral đều đạt độ chính xác 90–95% trên tập chú thích, thấp hơn GPT-4 trên các tài liệu thực sự mơ hồ, đúng.
Nhưng tôi đã chạy Qwen2.5 trên cùng 20 tài liệu ba lần và quay lại diff kết quả. Không có diff. Cùng JSON, cùng giá trị, cùng thứ tự trường mỗi lần chạy.
Sau sáu tuần thất bại mà tôi không thể dự đoán, điều đó cảm giác gần như sạch sẽ đến mức không thật.
Trước và Sau
Trình trích xuất GPT-4 ở trạng thái ổn định nhất, không phải nguyên mẫu ban đầu, phiên bản sau nhiều tháng mã phòng thủ đã tích tụ xung quanh nó:
# extractor_gpt4.py
import os
import json
from openai import OpenAI
client = OpenAI(api_key=os.environ["OPENAI_API_KEY"])
SYSTEM_PROMPT = """You are a research document metadata extractor.
Given the text of a research document, extract the specified metadata fields.
Be precise. If you are unsure about a field, use your best judgment based on context."""
EXTRACTION_SCHEMA = {
"name": "extract_document_metadata",
"parameters": {
"type": "object",
"properties": {
"methodology_type": {
"type": "string",
"enum": ["experimental", "observational", "review", "simulation", "mixed"]
},
"dataset_source": {"type": "string"},
"primary_metric": {"type": "string"},
"year": {"type": "integer"},
"confidence_score": {"type": "number"}
},
"required": ["methodology_type", "dataset_source", "year"]
}
}
def extract_metadata_gpt4(document_text: str) -> dict:
response = client.chat.completions.create(
model="gpt-4-turbo",
messages=[
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": f"Extract metadata from this document:\n\n{document_text[:8000]}"}
],
functions=[EXTRACTION_SCHEMA],
function_call={"name": "extract_document_metadata"},
temperature=0,
timeout=30
)
try:
args = response.choices[0].message.function_call.arguments
return json.loads(args)
except (AttributeError, json.JSONDecodeError) as e:
raise ValueError(f"Failed to parse GPT-4 response: {e}")
Độ trễ: 3.5–5.8s mỗi tài liệu. Chi phí: ~$0.04 mỗi lần gọi. Tỷ lệ lỗi: ~6% sau tất cả các bản sửa lỗi.
Để thay thế, tôi chọn Ollama. Một đồng nghiệp đã nhắc đến nó qua loa, và tài liệu trông hợp lý lúc 11 giờ tối, đó thực sự là cách nhiều quyết định hạ tầng được đưa ra. API REST đủ gần với OpenAI nên việc thay đổi mất khoảng một giờ:
# extractor_slm.py
import json
import logging
import os
import re
import requests
logger = logging.getLogger(__name__)
OLLAMA_URL = os.getenv("OLLAMA_URL", "http://localhost:11434")
MODEL = os.getenv("MODEL_NAME", "qwen2.5:7b-instruct-q4_K_M")
# Tested empirically: 7B q4 on a T4 takes ~8s on cold first token,
# then ~1.5s per doc chunk. 45s covers bad days.
_TIMEOUT = 45
_SYSTEM_PROMPT = """\
You are a metadata extractor for research documents.
Return ONLY a JSON object — no explanation, no markdown, no surrounding text.
Fields to extract:
- methodology_type (required): one of experimental | observational | review | simulation | mixed
- dataset_source (required): where the data came from
- year (required): integer
- primary_metric: main eval metric if present
- confidence_score: your confidence 0.0–1.0
Output example:
{"methodology_type": "experimental", "dataset_source": "ImageNet", "year": 2022, "primary_metric": "top-1 accuracy", "confidence_score": 0.95}
"""
def call_ollama(doc_text: str) -> dict:
payload = {
"model": MODEL,
"messages": [
{"role": "system", "content": _SYSTEM_PROMPT},
{"role": "user", "content": doc_text[:6000]},
],
"stream": False,
"options": {
"temperature": 0,
"seed": 42, # determinism — this is the whole point
},
}
try:
resp = requests.post(f"{OLLAMA_URL}/api/chat", json=payload, timeout=_TIMEOUT)
resp.raise_for_status()
except requests.exceptions.Timeout:
raise RuntimeError(f"Ollama timed out after {_TIMEOUT}s — is the model loaded?")
except requests.exceptions.ConnectionError:
raise RuntimeError(f"Can't reach Ollama at {OLLAMA_URL} — is the container running?")
raw = resp.json()["message"]["content"].strip()
cleaned = re.sub(r"^```(?:json)?\s*|\s*```$", "", raw).strip()
try:
return json.loads(cleaned)
except json.JSONDecodeError as e:
logger.error("Failed to parse model output: %s\nRaw was: %s", e, raw[:400])
raise
seed: 42 trong options là thứ thực sự mang lại tính xác định. Ollama hỗ trợ tạo có gieo hạt; cùng đầu vào, cùng hạt giống, cùng đầu ra, mỗi lần, không xấp xỉ. temperature=0 với API được lưu trữ hàm ý điều này nhưng không bao giờ đảm bảo nó vì bạn không kiểm soát thời gian chạy. Cục bộ, bạn kiểm soát.
Đưa vào GitHub Actions
Hai thứ không rõ ràng cho đến khi chúng cắn bạn. Thứ nhất: các vùng chứa dịch vụ (service containers) của GitHub Actions bị cô lập mạng khỏi trình chạy (runner). Bạn không thể docker exec vào chúng; việc kéo mô hình phải đi qua API REST. Thứ hai: lưu bộ nhớ đệm mô hình. Một lần kéo lạnh (cold pull) là 4.7GB và thêm 3–4 phút cho mỗi công việc.
# The non-obvious parts — the rest is standard Actions boilerplate
- name: Cache Ollama model
uses: actions/cache@v4
with:
path: ~/.ollama/models
key: ollama-qwen2.5-7b-q4
- name: Pull SLM model
# Can't docker exec into service containers — use the API
run: |
curl -s http://localhost:11434/api/pull \
-d '{"name": "qwen2.5:7b-instruct-q4_K_M"}' \
--max-time 300
- name: Warm up model
run: |
curl -s http://localhost:11434/api/generate \
-d '{"model": "qwen2.5:7b-instruct-q4_K_M", "prompt": "hello", "stream": false}' \
> /dev/null
- name: Run ingestion pipeline
run: python pipeline/run_ingestion.py
env:
OLLAMA_URL: "http://localhost:11434"
MODEL_NAME: "qwen2.5:7b-instruct-q4_K_M"
Lỗi viết hoa mà tôi dành quá nhiều thời gian
Qwen 2.5 thỉnh thoảng trả về "Experimental" với chữ E in hoa mặc dù có hướng dẫn rõ ràng không làm vậy. Kiểm tra kiểu Literal từ chối nó, và bạn nhận được lỗi xác nhận trên một tài liệu mà mô hình thực sự đã trích xuất đúng.
Tôi đã dành một khoảng thời gian đáng xấu hổ cho việc này vì thông báo lỗi chỉ nói "giá trị không hợp lệ", và bản năng đầu tiên của tôi là nhìn vào tài liệu, sau đó là bộ trích xuất, trước khi tôi cuối cùng nhìn vào bộ xác nhận và thấy nó.
Một bộ xác nhận normalize_methodology với mode="before" sửa nó trước khi kiểm tra kiểu chạy:
# pipeline/validation.py
from typing import Literal, Optional
from pydantic import BaseModel, Field, field_validator
class DocMetadata(BaseModel):
methodology_type: Literal["experimental", "observational", "review", "simulation", "mixed"]
dataset_source: str = Field(min_length=3)
year: int = Field(ge=1950, le=2030)
primary_metric: Optional[str] = None
confidence_score: Optional[float] = Field(default=None, ge=0.0, le=1.0)
@field_validator("dataset_source")
@classmethod
def strip_whitespace(cls, v: str) -> str:
return v.strip()
@field_validator("methodology_type", mode="before")
@classmethod
def normalize_methodology(cls, v: str) -> str:
# Qwen occasionally returns "Experimental" despite instructions
return v.lower().strip() if isinstance(v, str) else v
Tôi muốn thẳng thắn về các đánh đổi vì tôi ghét những bài viết không làm vậy.
GPT-4 thực sự tốt hơn trên các tài liệu mơ hồ, văn bản không phải tiếng Anh, bất kỳ thứ gì yêu cầu suy luận thực sự. Có một lớp tài liệu trong kho của chúng tôi, các PDF cũ hơn, báo cáo trộn nhiều ngôn ngữ, định dạng không chuẩn, nơi SLM vấp ngã và GPT-4 thì không.
Chúng tôi đánh dấu những cái đó riêng biệt và định tuyến chúng vào hàng đợi xem xét. Điều đó không liền mạch, nhưng nó trung thực. SLM làm 90% việc nó giỏi và không được yêu cầu làm phần còn lại.
Thiết lập cũng tốn nhiều công hơn là pip install openai. Cấu hình lần đầu mất một buổi chiều thực sự. Và Ollama không tự động cập nhật mô hình, vì vậy quản lý phiên bản là vấn đề của tôi bây giờ. Tôi thực sự đã hòa giải với điều đó, biết chính xác phiên bản mô hình nào đã chạy đêm qua và đêm hôm trước là toàn bộ điểm mấu chốt.
Những gì tôi nghĩ bây giờ
Sáng hôm đó pipeline lần đầu tiên chạy sạch, không có thông báo, không chạy lại, chỉ một tệp nhật ký cho thấy 312 tài liệu được xử lý trong 8.4 phút, tôi đã kiểm tra nó hai lần, sau đó chạy lại thủ công một lần nữa.
Tôi đã dành sáu tuần nửa mong đợi một cảnh báo trước khi tôi kịp uống xong cà phê. Nhìn nó vượt qua một cách im lặng cảm thấy thực sự lạ lùng.
Thất bại không phải là sử dụng GPT-4. Thất bại là đối xử với một hệ thống xác suất như một hàm xác định. temperature=0 giảm phương sai. Nó không loại bỏ nó.
Tôi đã hiểu điều này về mặt lý thuyết cả thời gian. Mất 23 lần thất bại để hiểu nó theo một cách thay đổi cách tôi xây dựng mọi thứ.
Nếu bạn đang chạy LLM trong một pipeline tự động và mọi thứ cứ bị hỏng theo những cách bạn không thể tái tạo, có thể không phải là mã của bạn hay prompt của bạn. Có thể là bản chất của thứ bạn đang phụ thuộc vào.
Một mô hình cục bộ trên phần cứng bạn kiểm soát, được gieo hạt để xác định, là một lớp công cụ thực sự khác nhau cho loại công việc này. Không tốt hơn mọi thứ nhưng tốt hơn ở việc là cùng một thứ hai lần. Và đối với một pipeline chạy không người lái mỗi đêm, đó là hầu hết những gì thực sự quan trọng.
Bài viết liên quan

Phần mềm
Apple ra mắt Siri AI: Trợ lý ảo thế hệ mới thông minh hơn và thấu hiểu bạn hơn
08 tháng 6, 2026

Phần cứng
Nvidia chính thức đưa siêu vi xử lý Grace Blackwell lên PC với dòng notebook RTX Spark
01 tháng 6, 2026
AI & ML
MFA chỉ là bước khởi đầu: Tại sao xác thực thành công vẫn không ngăn chặn được tin tặc?
21 tháng 5, 2026