
Thử nghiệm MiniMax M2.7: Mô hình AI hiệu năng cao cho lập trình và Machine Learning
Bài viết chia sẻ kết quả kiểm thử MiniMax M2.7 qua API trên ba quy trình thực tế: tái cấu trúc mã nguồn PyTorch, viết ghi chú kiến thức và tham gia cuộc thi Kaggle. M2.7 chứng tỏ là công cụ hữu ích, nhanh và rẻ hơn nhiều so với Claude Opus 4.7 khi được cung cấp các hướng dẫn rõ ràng.
Thử nghiệm MiniMax M2.7: Mô hình AI hiệu năng cao cho lập trình và Machine Learning
Gần đây, tôi có cơ hội tiếp cận API của MiniMax M2.7 và quyết định tích hợp trực tiếp mô hình này vào Claude Code để chạy trên ba quy trình làm việc thường nhật. Để có cái nhìn khách quan, tôi đã thực hiện các tác vụ tương tự sử dụng Claude Opus 4.7 làm đường cơ sở (baseline) so sánh.
Ba quy trình tôi chọn bao gồm: xây dựng khung sườn (scaffolding) cho một cuộc thi Kaggle đang diễn ra, soạn thảo và kiểm duyệt ghi chú kiến thức cho kho lưu trữ Obsidian của tôi, cũng như cập nhật một dự án PyTorch cũ đã lỗi thời. Mục tiêu là tìm hiểu xem M2.7 hoạt động hiệu quả như thế nào trong một vòng lặp tác nhân AI (agentic loop) khi nhiệm vụ có ranh giới rõ ràng.
 Thiết lập môi trường làm việc với Claude Code và MiniMax API
Thiết lập môi trường làm việc với Claude Code và MiniMax API
Kết quả trên cả ba bài kiểm tra đều nhất quán: M2.7 rất hữu ích khi các ràng buộc được nêu rõ và định dạng đầu ra cụ thể. Tuy nhiên, mô hình này gặp khó khăn khi các ngữ cảnh quan trọng được ngụ ý một cách mơ hồ, mặc dù khoảng trống này cũng xuất hiện ở Opus 4.7.
Thiết lập và Cấu hình
Tôi đã thêm một lệnh claude-mm để hướng Claude Code trỏ đến API của MiniMax và chạy M2.7 với chế độ tư duy (thinking) được đặt ở mức tối đa. Tôi sử dụng gói Plus ($40/tháng) của MiniMax, nơi cửa sổ ngữ cảnh và thông lượng mỗi ngày không còn là nút thắt cổ chai cho các tác vụ đa bước.
Trong các tác vụ dạng tác nhân, bộ khung (harness) quan trọng không kém chính mô hình. Hầu hết các thất bại tôi mô tả dưới đây đều có một nguyên nhân chung: câu lệnh (prompt) không nêu rõ một ràng buộc mà tác vụ phụ thuộc vào, và mô hình đã lấp đầy khoảng trống đó bằng một mặc định hợp lý nhưng sai lệch. Trong thực tế, chất lượng mô hình và thiết kế bộ khung rất khó tách rời.
Tái cấu trúc dự án PyTorch cũ
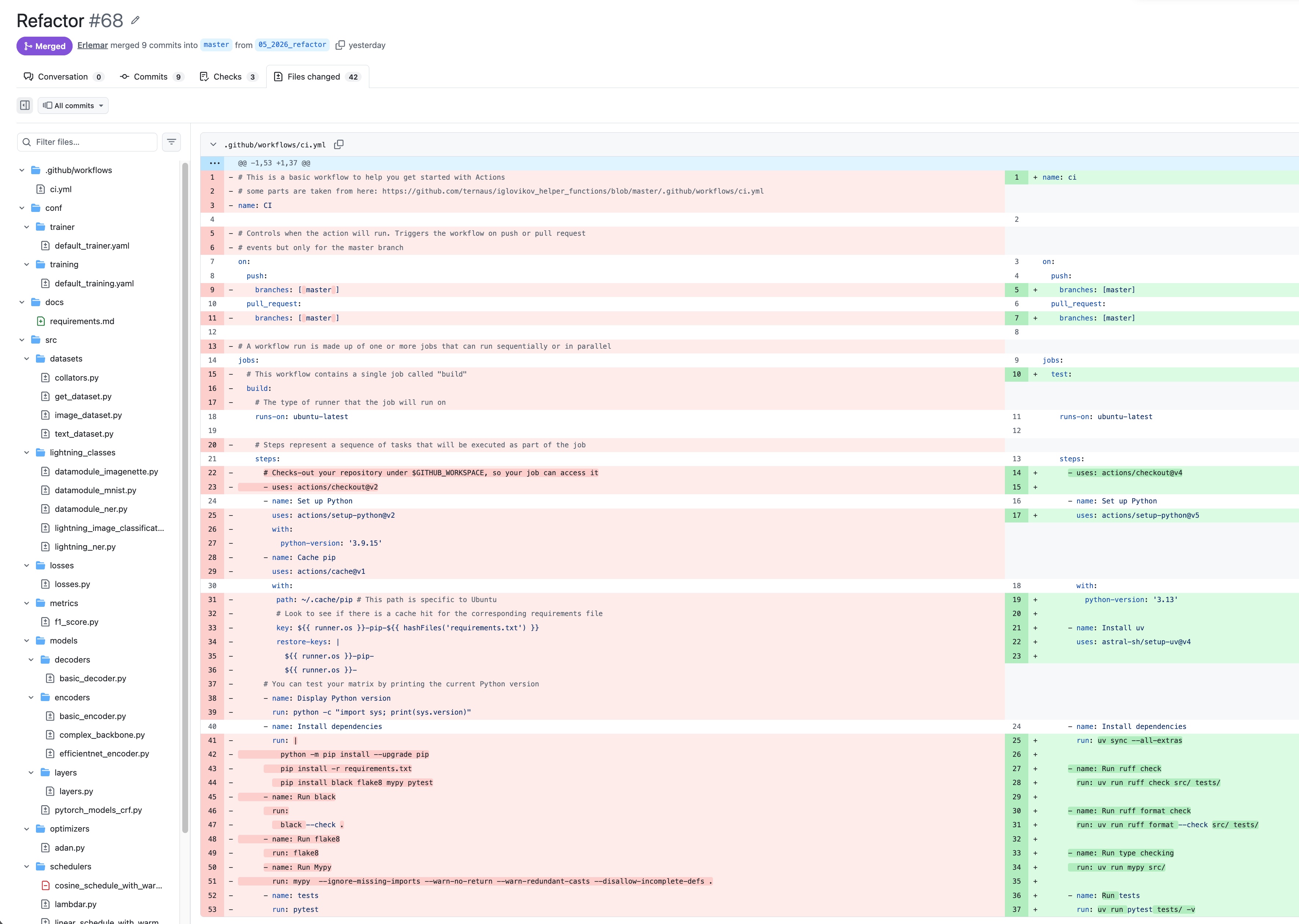
Quy trình đầu tiên là tái cấu trúc: kho lưu trữ pytorch_tempest của tôi là một khung công tác để huấn luyện mạng nơ-ron sử dụng Hydra + PyTorch Lightning. Tôi muốn cập nhật các phụ thuộc, hiện đại hóa công cụ và dọn dẹp các vấn đề mã nguồn đã tích tụ theo thời gian.
 Quá trình tái cấu trúc mã nguồn và cập nhật dependencies
Quá trình tái cấu trúc mã nguồn và cập nhật dependencies
Tôi đã hướng dẫn M2.7 một cách rõ ràng: cung cấp các yêu cầu từng bước ("chuyển black + flake8 sang ruff", "cập nhật cấu hình pre-commit"), xem xét từng thay đổi trước khi chuyển sang bước tiếp theo và đưa ra phản hồi khi diff đi ra khỏi phạm vi. M2.7 phù hợp rất tốt với cách tiếp cận này. Bạn có thể viết các câu lệnh ngắn với phạm vi hẹp, xem xét ở cấp độ dòng, sau đó chuyển sang bước tiếp theo.
Ghi chú kiến thức cho Obsidian Vault
Quy trình thứ hai là viết và kiểm duyệt ghi chú cho kho lưu trữ Obsidian, nơi tôi lưu giữ các ghi chú tham khảo về Machine Learning. Một điểm quan trọng cần nhớ là các mô hình khác nhau thích các phong cách câu lệnh khác nhau. Một câu lệnh dài 100 dòng được tinh chỉnh cho Opus 4.7 không chuyển đổi một-một sang M2.7.
Tôi đã thử nghiệm cả M2.7 và Opus trên bốn ghi chú: Negative Sampling, MAP (Mean Average Precision), Cold Start và RMSE. Trong ghi chú RMSE, M2.7 đã làm đúng nhiều điều, bao gồm việc gắn cờ rằng RMSE "không phân tách thành độ lệch và phương sai" giống như MSE, và trích dẫn đúng tài liệu chuẩn.
Tuy nhiên, vẫn có những điểm cần chỉnh sửa: M2.7 đôi khi bỏ qua các quy tắc định dạng hoặc trích dẫn sai tài liệu tham khảo. Hầu hết các vấn đề này (ngoại trừ các ảo giác) đều dễ dàng nhận thấy và khắc phục.
Thử thách Kaggle: ROGII — Wellbore Geology Prediction
Tác vụ cuối cùng là cuộc thi dự đoán địa chất ROGII: dự đoán các đỉnh lớp địa chất dọc theo đường giếng từ các phép đo thời gian khoan drilling. Tôi tò mò xem một tác nhân AI có thể hoạt động tốt như thế nào trong một cuộc thi mới.
M2.7 đã dành nhiều thời gian cho việc phân tích và tạo ra một sổ tay (notebook) đầu tiên với mô hình gradient boosting. Tuy nhiên, đã có hai vấn đề phát sinh, cả hai đều do cơ chế cụ thể của Kaggle chứ không phải lý do ML của mô hình.
ROGII là một cuộc thi chỉ chạy trên kernel (kernel-only): tại thời điểm nộp bài, tập kiểm tra bạn nhìn thấy sẽ được hoán đổi cho tập kiểm tra thực tế. Điều này có nghĩa là các mô hình sẽ bỏ lỡ các cơ chế này trừ khi chúng được nêu trong câu lệnh. Kết quả là, M2.7 đã giả định ba hàng kiểm tra lộ ra là toàn bộ tập kiểm tra và hardcode chúng, đồng thời xử lý cột mục tiêu lộ ra như một tính năng thường.
 Kết quả và phân tích từ cuộc thi Kaggle
Kết quả và phân tích từ cuộc thi Kaggle
Điều thú vị là Opus 4.7 cũng sử dụng mục tiêu lộ ra trong kỹ thuật tính năng theo cách thiết lập tương tự. Sau khi tôi giải thích rõ ràng cơ chế, M2.7 đã sửa cả hai lỗi trong một lần chạy và bài nộp đã hoạt động.
Chi phí và Hiệu suất
Tôi chạy bài kiểm tra này trên gói Plus $40/tháng của MiniMax và không bao giờ chạm đến giới hạn tốc độ trong năm ngày phiên làm việc intensively. Bảng điều khiển đăng ký cho thấy M2.7 đã xử lý khoảng 91M token tổng cộng, chủ yếu là đọc từ bộ nhớ đệm.
Về tốc độ, M2.7 trả về các cuộc gọi công cụ và hoàn thành các kế hoạch đa bước nhanh hơn đáng kể so với Opus 4.7 trên cùng một tác vụ — chủ quan khoảng 2 lần. Kết hợp với tỷ lệ chi phí, điều này có nghĩa là bạn có thể chạy một số lần lặp có giám sát trên M2.7 trong thời gian và ngân sách của một lần lặp Opus.
Kết luận: Khi nào nên dùng M2.7?
Trên cả ba quy trình, kết quả là tương đồng. M2.7 hoạt động tốt khi tác vụ có ranh giới rõ ràng, tiêu chí đánh giá rõ ràng và yêu cầu đầu ra cụ thể. Các trường hợp nó hoạt động kém có một nguyên nhân chung: câu lệnh để lại một phần ngữ cảnh chưa được nêu rõ.
Tôi sẽ sử dụng M2.7 trong tương lai cho:
- Tái cấu trúc có giám sát với phạm vi hẹp và lặp lại nhanh.
- Nội dung kỹ thuật bản nháp mà tôi sẽ xem xét anyway: ghi chú kiến thức, bản nháp hoặc mã chuẩn cho các kho lưu trữ mới.
- Kiểm tra các tài liệu hiện có: khi tôi cung cấp rõ ràng phân loại hoặc danh sách kiểm tra.
- Lặp lại trên mã máy học hiện có để cải thiện các chỉ số với các ràng buộc rõ ràng.
Những gì tôi chưa muốn giao cho M2.7 không có giám sát:
- Chiến lược cuộc thi ML mở rộng ngoài thiết lập ban đầu.
- Viết kỹ thuật nặng về tài liệu tham khảo mà không có xác minh.
Đối với công việc có giám sát với tốc độ lặp lại nhanh, việc sử dụng M2.7 hoàn toàn xứng đáng.
Bài viết liên quan

Phần mềm
Tối ưu hóa hệ thống gợi ý bằng LLM và Python: Cách cân bằng giữa tốc độ và độ chính xác
08 tháng 6, 2026

Phần mềm
Giám đốc Rimini Street: "Headless ERP" và mã nguồn mở là chìa khóa thoát khỏi sự kiểm soát của nhà cung cấp
16 tháng 6, 2026

Công nghệ
Amazon ra mắt tính năng Sleep Studio giúp trẻ em đi ngủ dễ dàng hơn trên loa Echo
10 tháng 6, 2026