
Tôi đã xây dựng một chiếc máy tính tí hon nằm gọn trong mô hình Transformer
Thay vì huấn luyện Transformer để học các mẫu từ dữ liệu, tác giả đã xây dựng thủ công các trọng số để thực thi một đồ thị tính toán xác định. Cách tiếp cận này coi luồng residual là bộ nhớ máy tính và sử dụng attention cùng FFN để thực hiện các lệnh, mở ra hướng đi mới kết hợp suy luận xác suất với tính toán xác định ngay trong nội tại mô hình.
Thông thường, chúng ta huấn luyện các mô hình Transformer và hy vọng rằng các mạch nhận diện mẫu hữu ích sẽ tự hình thành bên trong chúng. Nhưng nếu chúng ta đã biết trước mạch đó thì sao? Nếu thay vì học các trọng số từ dữ liệu, chúng ta xây dựng chúng một cách phân tích để mô hình thực thi trực tiếp một đồ thị tính toán thì sao?
Đó chính là ý tưởng đằng sau dự án cuối tuần của tôi. Thay vì coi Transformer là một hệ thống phải khám phá thuật toán thông qua tối ưu hóa, tôi coi nó như một cỗ máy có thể lập trình được. Một lịch trình sẽ xác định số lượng trung gian nào cần được tính toán tại mỗi bước. Các chiều ẩn được gán cho các biến giống như các thanh ghi trong một chiếc máy tính tí hon. Các cơ chế chú ý (attention heads) được kết nối để thực hiện tra cứu và định tuyến. Các đơn vị feed-forward được kết nối để triển khai các tính toán cục bộ có cổng. Các cập nhật residual sẽ ghi trạng thái máy tiếp theo trở lại vào luồng dữ liệu.
Kết quả là một mô hình Transformer chuẩn đang thực thi một chương trình xác định.
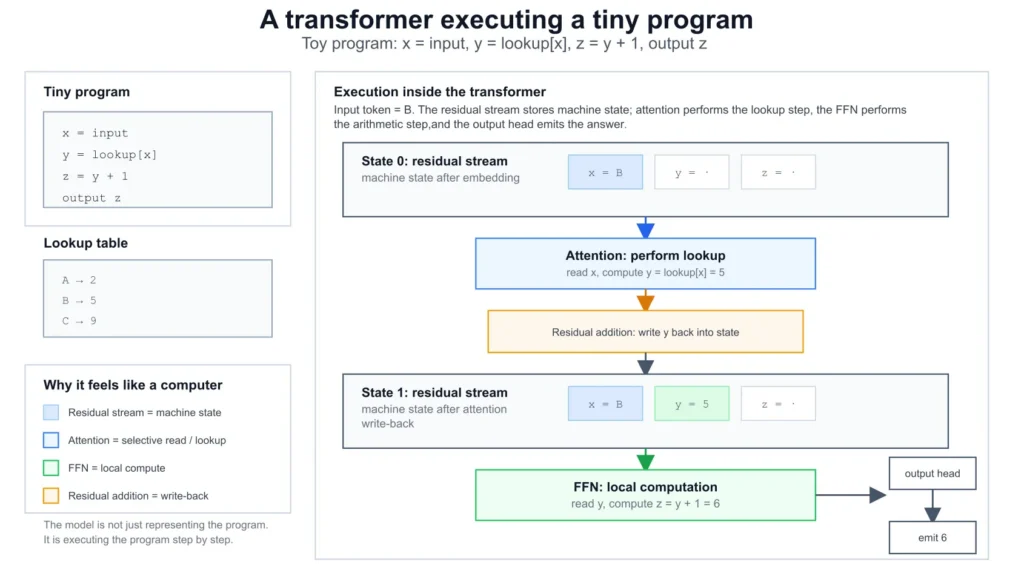 Một mô hình Transformer thực thi một chương trình nhỏ
Một mô hình Transformer thực thi một chương trình nhỏ
Trong quan điểm này, luồng residual đóng vai trò là bộ nhớ làm việc và mỗi lớp trở thành một bước của máy tính. Một số giá trị được đọc, một số được chuyển đổi, một số được truyền qua, và một số bị ghi đè khi các vị trí của chúng có thể được sử dụng lại an toàn. Mô hình Transformer bắt đầu giống như một chiếc máy tính đã được biên dịch nhỏ xíu được xây dựng từ các khối chú ý, phép chiếu tuyến tính và các cổng điều khiển.
Không có gì trong số này yêu cầu huấn luyện. Nếu bạn đã có một đồ thị tính toán và một lịch trình cho biết khi nào mỗi biến trung gian nên tồn tại, bạn có thể xây dựng trực tiếp các trọng số của mô hình. Kết quả là Transformer trở thành một động cơ thực thi mà hành vi của nó được xác định bởi thiết kế thay vì là giảm độ dốc (gradient descent).
Điều làm cho điều này đặc biệt thú vị là nó cung cấp một giải pháp thay thế cho việc sử dụng công cụ bên ngoài. Thay vì buộc mô hình phải thoát khỏi vòng lặp thực thi của chính nó mỗi khi cần tính toán chính xác, chúng ta có thể tưởng tượng việc cung cấp cho nó một chế độ xác định nội tại. Trong một chế độ, mô hình hoạt động như một hệ thống ngôn ngữ linh hoạt: tạo ra, trừu tượng hóa và lý luận. Trong chế độ khác, nó hoạt động giống như một máy tính đã được biên dịch hơn: cập nhật trạng thái, theo một đồ thị tính toán cố định và thực hiện các bước chính xác một cách đáng tin cậy.
Một chương trình nhỏ có thể biên dịch vào Transformer
Thay vì chỉ dừng lại ở mức độ ẩn dụ, hãy cùng xem một chương trình rất nhỏ chạy. Đây là chương trình đồ chơi mà tôi sẽ sử dụng trong phần còn lại của bài viết:
lookup = {
"A": 2,
"B": 5,
"C": 9,
}
x = input
y = lookup[x]
z = y + 1
output z
Chương trình này cố tình nhỏ gọn, nhưng nó chứa ba thành phần chúng ta cần: một thao tác tra cứu, một tính toán cục bộ và một đầu ra. Giả sử token đầu vào là B. Sau đó chương trình sẽ phát triển như sau:
x = B y = lookup[B] = 5 z = 5 + 1 = 6 output 6
Ý tưởng chính là chúng ta có thể biểu diễn trạng thái chương trình đang phát triển này bên trong luồng residual của Transformer. Thay vì coi vector ẩn là một biểu diễn đã học trừu tượng, chúng ta gán ý nghĩa rõ ràng cho các phần của nó:
slot 3 = x slot 4 = y slot 5 = z
Do đó, trạng thái phát triển như sau:
[x = B, y = ·, z = ·] [x = B, y = 5, z = ·] [x = B, y = 5, z = 6]
Tại thời điểm này, đầu ra đọc z và phát ra giá trị 6. Đây là mô hình tư duy trung tâm cho phần còn lại của bài viết. Luồng residual là trạng thái máy của một chương trình đang chạy nhỏ. Cơ chế chú ý, tính toán feed-forward và phép cộng residual là các phương thức mà trạng thái đó được đọc, cập nhật và ghi lại.
Một bước máy: Attention, FFN và Write-back
Khi các biến đã được gán cho các vị trí (slot), bước không tầm thường đầu tiên trong chương trình đồ chơi là:
y = lookup[x]
Theo cách này, tôi tái sử dụng cơ chế chú ý của Transformer để thực hiện thao tác tra cứu. Ở mức độ cao, attention đã có hình dạng phù hợp cho công việc này. Nó lấy trạng thái hiện tại, so sánh nó với một tập hợp các mẫu được lưu trữ, chọn cái phù hợp và trả về giá trị liên quan. Trong một mô hình ngôn ngữ, cơ chế này thường được sử dụng để truy xuất ngữ cảnh. Ở đây, tôi sử dụng nó theo nghĩa đen hơn: như một toán tử tra cứu xác định nhỏ.
Đầu chú ý được kết nối để: query đại diện cho yêu cầu tra cứu hiện tại, có nguồn từ x. keys đại diện cho các trường hợp có thể xảy ra, chẳng hạn như A, B và C. values đại diện cho các đầu ra tương ứng, chẳng hạn như 2, 5 và 9.
Khi giá trị đúng đã được chọn, nó vẫn phải trở thành một phần của trạng thái máy. Đó là lúc phép cộng residual phát huy tác dụng. Khối chú ý không thay thế trực tiếp toàn bộ luồng residual. Thay vào đó, nó tạo ra một bản cập nhật nói hiệu quả rằng "ghi 5 vào vị trí của y", và phép cộng residual cam kết bản cập nhật đó vào trạng thái.
Dòng tiếp theo của chương trình thì khác:
z = y + 1
Tại thời điểm này, chúng ta không cần tra cứu. Chúng ta đã có giá trị cần thiết. Điều còn lại là áp dụng một phép biến đổi cục bộ nhỏ cho nó. Đó chính xác là vai trò của khối feed-forward (FFN).
Trong chương trình đồ chơi này, điều đó có nghĩa là đọc y = 5, tính z = 6 và phát ra một bản cập nhật nhắm vào vị trí của z. Sau khi phép cộng residual cam kết bản cập nhật đó, trạng thái trở thành:
[x = B, y = 5, z = 6]
Sự phân chia lao động là: Attention được coi tốt nhất là tra cứu và định tuyến. FFN được coi tốt nhất là tính toán cục bộ. Phép cộng residual là cơ chế ghi lại cam kết bản cập nhật vào trạng thái.
Từ biến chương trình đến quá trình biên dịch
Khi luồng residual được diễn giải là trạng thái máy, việc xây dựng bắt đầu trông giống như quá trình biên dịch hơn là thiết kế mạng nơ-ron thông thường. Lịch trình cho chúng ta biết khi nào mỗi biến nên tồn tại. Trong ví dụ đồ chơi, x tồn tại trước, sau đó y được tạo ra từ nó, và sau đó z được tạo ra từ y. Trong một tính toán lớn hơn, các biến khác nhau xuất hiện tại các thời điểm khác nhau, tồn tại một lúc và sau đó biến mất khi không còn cần thiết nữa.
Điều này dẫn đến khái niệm về "tính sống" (liveness). Một biến được coi là sống tại một điểm nhất định trong lịch trình nếu một bước sau đó vẫn cần nó. Khi không có bước nào trong tương lai phụ thuộc vào nó, biến đó chết và vị trí của nó có thể được thu hồi.
Điều này rất gần với việc phân bổ thanh ghi (register allocation) trong một trình biên dịch truyền thống. Trình biên dịch lấy các biến chương trình và quyết định nơi chúng nên sống trong một nhóm vị trí lưu trữ giới hạn. Việc xây dựng này làm điều tương tự, ngoại trừ các vị trí lưu trữ là các vị trí trạng thái ẩn trong Transformer.
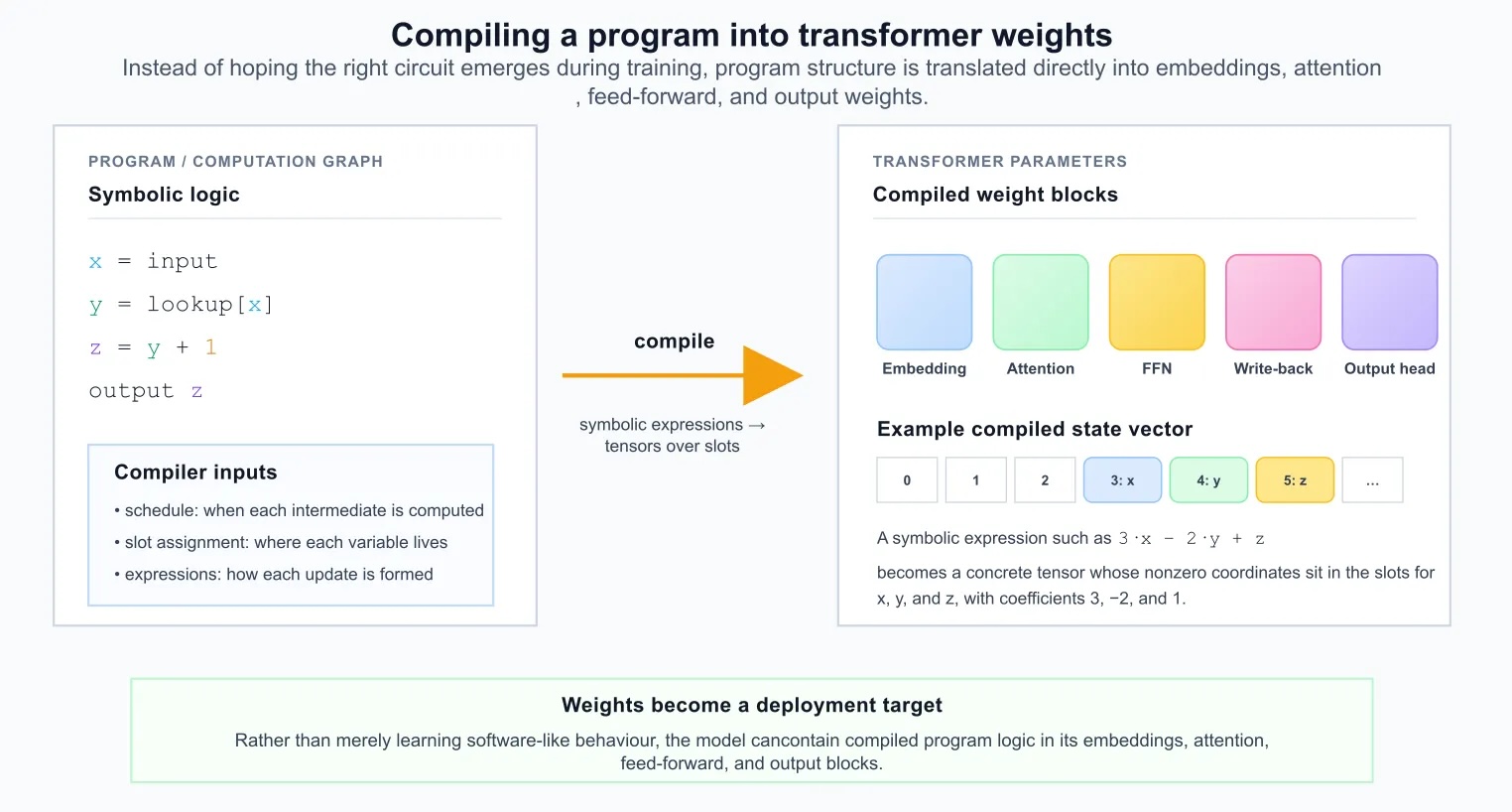
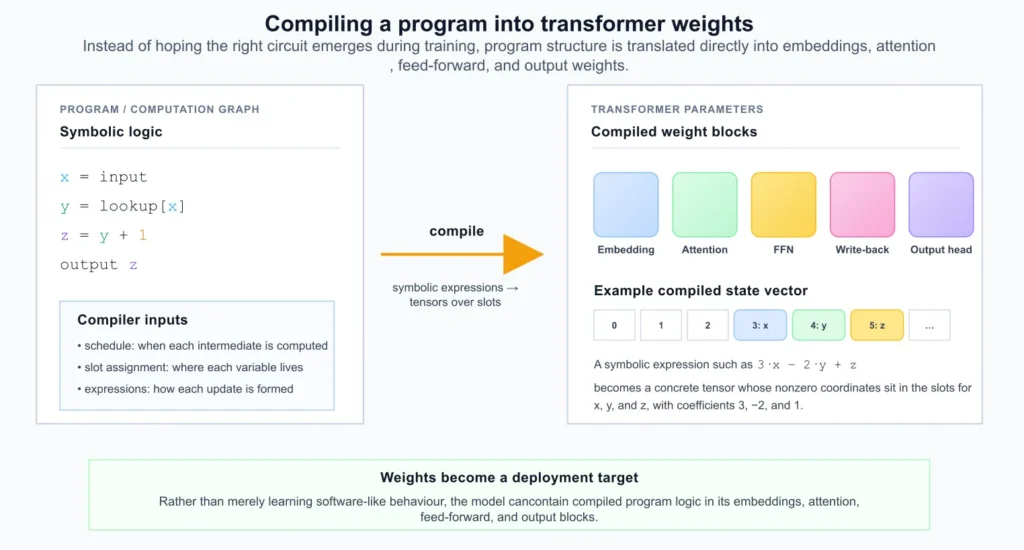 Biên dịch một chương trình thành các trọng số Transformer
Biên dịch một chương trình thành các trọng số Transformer
Một lớp Transformer chuẩn sau đó được coi là hai bước máy: một lớp nửa attention. một lớp nửa FFN.
Mỗi cái đọc luồng residual hiện tại, tính toán một bản cập nhật và ghi bản cập nhật đó trở lại thông qua phép cộng residual. Vì vậy, thay vì nghĩ rằng một lớp là một phép biến đổi mờ đục, việc coi nó là hai chuyển đổi trạng thái rõ ràng sẽ hữu ích hơn.
Từ đồ thị tính toán đến trọng số
Điểm khởi đầu là đồ thị tính toán. Mỗi đại lượng trung gian trong chương trình được biểu diễn dưới dạng một chiều biểu tượng cùng với biểu thức xác định cách nó nên được tính toán từ các đại lượng trước đó. Lịch trình sau đó quyết định phép tính nào diễn ra trong lớp nửa attention nào và phép tính nào diễn ra trong lớp nửa FFN nào.
Khi lịch trình đó được cố định, mỗi biến sống được gán cho một vị trí trạng thái ẩn. Một số vị trí được cố định từ đầu, một số được phân bổ khi các biến mới sinh ra và một số được sử dụng lại sau khi các biến cũ chết.
Bước còn lại là biến cấu trúc đó thành các trọng số Transformer. Cơ chế cốt lõi là chuyển đổi các biểu thức biểu tượng trên các biến chương trình thành các vector trên các vị trí. Ví dụ, một biểu thức biểu tượng là 3·x - 2·y + z và giả sử rằng x, y và z đã được gán cho các vị trí 3, 4 và 5 tương ứng. Khi đó, biểu thức trở thành một vector có giá trị bằng 0 ở khắp mọi nơi ngoại trừ tại ba vị trí đó, trong đó các mục nhập của nó là 3, -2 và 1.
Về cơ bản, trình biên dịch đã thay thế tên biến bằng địa chỉ vị trí. Biểu thức biểu tượng đã trở thành một phép đọc tuyến tính cụ thể trên trạng thái máy hiện tại.
Mở rộng thực thi chương trình cho các chuỗi dài
Câu hỏi còn lại là điều gì sẽ xảy ra khi ý tưởng này được đẩy xa hơn, cụ thể là cách thực hiện tra cứu nặng có thể được thực hiện đủ hiệu quả để hỗ trợ các chuỗi xác định dài hơn.
Trong các cấu trúc trên, attention thường hoạt động trong chế độ tra cứu gần như cứng nhắc. Về mặt khái niệm, một đầu chú ý tạo ra một truy vấn q, so sánh nó với các khóa ứng viên k₁, k₂, ..., kₙ, tính điểm số và trả về giá trị được gắn cho khóa có điểm cao nhất. Quan sát hữu ích là tra cứu này có thể được diễn giải lại theo hình học.
Truy vấn q xác định một hướng, mỗi khóa là một điểm và khóa được chọn là điểm có tích vô hướng với q lớn nhất — nói cách khác, điểm xa nhất theo hướng đó. Nếu các khóa sống trong hai chiều, đó chính xác là vấn đề tìm kiếm bao lồi (convex-hull search).
Đây là nơi lợi thế tính toán xuất hiện. Một tra cứu attention tuyến tính kiểm tra mọi khóa ứng viên. Trong quan điểm bao lồi, các điểm nội tại có thể bị loại bỏ vì chúng không bao giờ có thể là bộ tối đa hóa theo bất kỳ hướng truy vấn nào. Điều đó có nghĩa là chúng ta có thể duy trì một cấu trúc dữ liệu bao lồi trên các khóa 2D được lưu trữ và trả lời mỗi tra cứu bằng cách tìm kiếm cấu trúc đó, thay vì quét toàn bộ tập hợp các khóa quá khứ.
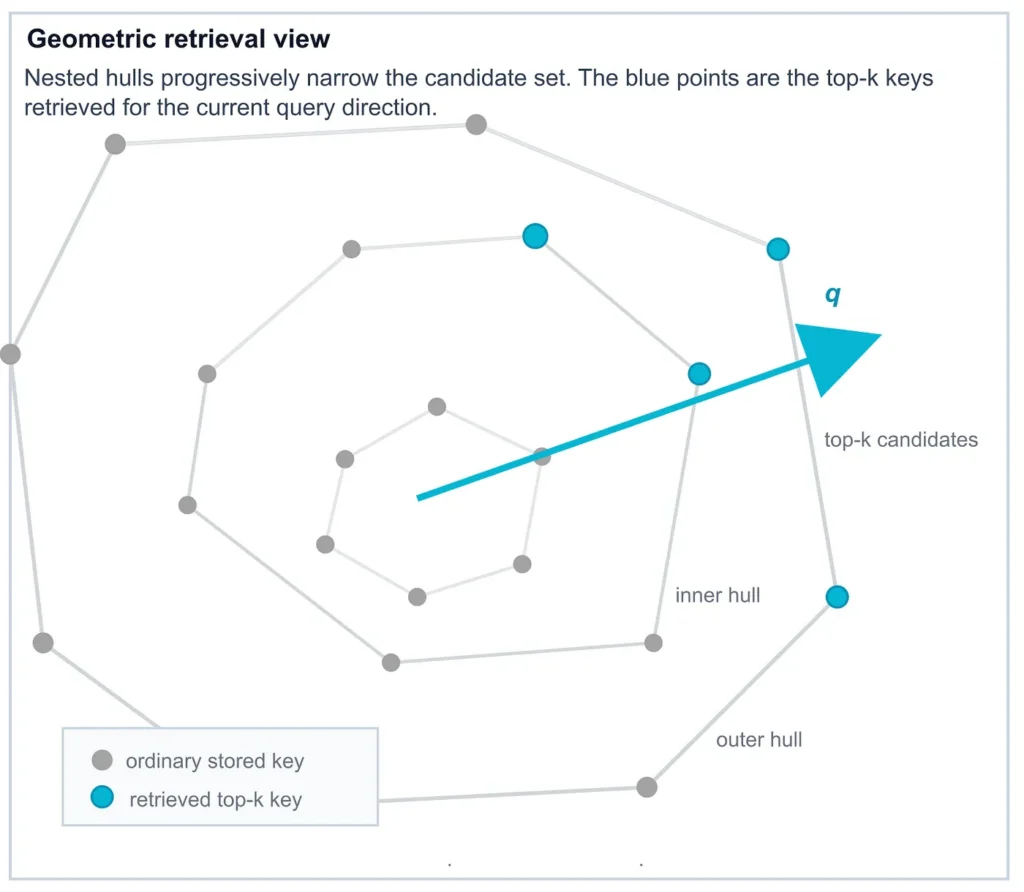 Cơ chế tra cứu k-sparse softmax sử dụng bao lồi lồng nhau
Cơ chế tra cứu k-sparse softmax sử dụng bao lồi lồng nhau
Cùng một công thức hình học cũng tồn tại trong các chiều cao hơn. Tuy nhiên, trong trường hợp xấu nhất, một phần lớn các khóa được lưu trữ có thể nằm trên chính bao lồi đó, do đó lợi thế "biên giới nhỏ" biến mất. Đó là lý do tại sao ý tưởng này thú vị cho các kích thước đầu rất nhỏ, đặc biệt là 2D, nhưng không phải là một giải pháp thực tế để attention tuyến tính con cho các Transformer chuẩn có đầu lớn.
Một mô hình thiết kế AI mới: Tích hợp biểu diễn đã học với thuật toán xác định
Việc biên dịch các chương trình thành các trọng số Transformer chỉ ra một tương lai đầy hứa hẹn cho các hệ thống AI: các kiến trúc có thể kết hợp suy luận xác suất với tính toán xác định bên trong cùng một mô hình, thay vì liên tục giao công việc chính xác cho các công cụ bên ngoài. Các thành phần xác suất phù hợp với sự trừu tượng hóa, nhận diện mẫu và lý luận dưới sự không chắc chắn. Các thành phần xác định phù hợp với việc cập nhật trạng thái chính xác, thực thi chính xác và các chuỗi tính toán dài đáng tin cậy. Các hệ thống thực cần cả hai.
Lời hứa sâu sắc hơn là việc thực thi xác định không nhất thiết phải nằm ngoài mô hình. Nếu các hoạt động gốc của Transformer như attention và các khối feed-forward có thể được tổ chức thành một nền tảng thực thi có thể lập trình, thì các phần của một trình thông dịch hoặc một chương trình chuyên biệt có thể được biên dịch trực tiếp vào các trọng số. Mô hình không còn chỉ gọi công cụ thông minh hơn; nó bắt đầu nội bộ hóa một phần tính toán đó.
Điều đó chỉ ra một loại máy tính thống nhất hơn: một loại có thể lý luận linh hoạt khi sự không chắc chắn là không thể tránh khỏi và chuyển sang thực thi chính xác khi độ chính xác quan trọng. Đối với các lĩnh vực rủi ro cao mà cả độ tin cậy và hiệu suất đều quan trọng — tài chính, y tế, bảo hiểm và chuỗi cung ứng trong số đó — điều đó cảm thấy như một mô hình thiết kế AI mới nổi quan trọng.
Bài viết liên quan

Công nghệ
Các tác nhân AI đã khiến thế giới công nghệ chao đảo: Câu chuyện đằng sau cuộc cách mạng Claude Code và OpenClaw
26 tháng 5, 2026

Công nghệ
Alienware 15 mới: Dell đang làm loãng thương hiệu cao cấp vì khủng hoảng RAM?
14 tháng 5, 2026

Công nghệ
Pinterest áp dụng "vân tay nội dung" để loại bỏ URL trùng lặp trên hàng triệu tên miền
08 tháng 6, 2026