
Tối ưu hóa GPU: Hướng dẫn toàn diện để tăng hiệu suất huấn luyện AI
Nghiên cứu AI hiện đại đòi hỏi tài nguyên tính toán khổng lồ, khiến việc tối ưu hóa hiệu suất GPU trở nên cấp thiết hơn bao giờ hết. Bài viết này sẽ đi sâu vào kiến trúc GPU, phân tích các nút thắt cổ chai phổ biến và cung cấp các giải pháp thực tế từ cấu hình PyTorch cơ bản đến tối ưu hóa kernel nâng cao.

Trong kỷ nguyên của các mô hình AI quy mô lớn và tập dữ liệu khổng lồ, phần cứng tính toán đang bị đẩy đến giới hạn cuối cùng. Dù bạn đang huấn luyện các mô hình trên hình ảnh phức tạp, xử lý tài liệu dài hay chạy các môi trường học tăng cường (reinforcement learning) với throughput cao, việc tối đa hóa hiệu suất GPU là yếu tố sống còn. Việc thiết lập chưa được tối ưu hóa có thể biến một thí nghiệm nhanh chóng thành hàng giờ hoặc hàng ngày chờ đợi.
Khi quá trình huấn luyện hoặc suy luận (inference) diễn ra chậm chạp, phản xạ thường thấy của chúng ta là đổ lỗi cho kích thước mô hình hoặc độ phức tạp của toán học. Tuy nhiên, GPU hiện đại là những máy tính cực nhanh, nhưng chúng phụ thuộc vào CPU để phân công công việc và vị trí lưu trữ dữ liệu trên thiết bị. Thông thường, tính toán trên GPU không phải là nút thắt cổ chai. Nếu CPU của bạn gặp khó khăn trong việc tải, tiền xử lý và chuyển các lô (batch) dữ liệu qua cầu nối PCIe, GPU của bạn sẽ ngồi không, thiếu dữ liệu để xử lý.
Tin tốt là bạn không cần phải viết các CUDA kernel tùy chỉnh hay debug mã GPU cấp thấp để khắc phục điều này. Bài viết này sẽ khám phá cơ chế của các nút thắt cổ chai này và đưa ra các quyết định kỹ thuật thực tế để tối đa hóa việc sử dụng GPU.
Tổng quan về GPU
Để bắt đầu, Graphics Processing Units (GPU) trở nên phổ biến cùng với deep learning nhờ khả năng huấn luyện và chạy các mô hình với tốc độ ánh sáng qua các phép toán có thể song song hóa. Nhưng GPU thực sự làm gì?
GPU khác với CPU như thế nào?
GPU không phải lúc nào cũng vượt trội hơn CPU. CPU được thiết kế để giải quyết các vấn đề tuần tự cao với độ trễ thấp và phân nhánh phức tạp (tính chất lý tưởng để chạy hệ điều hành). Ngược lại, GPU bao gồm hàng nghìn lõi được tối ưu hóa để hoàn thành các phép toán cơ bản song song. Trong khi CPU cần xử lý hàng nghìn phép nhân ma trận tuần tự, GPU có thể chạy tất cả các phép toán này song song trong tích tắc.
Ở mức độ cao, GPU bao gồm hàng nghìn lõi xử lý nhỏ được nhóm thành Streaming Multiprocessors (SMs) được thiết kế cho tính toán song song quy mô lớn. Một vùng bộ nhớ băng thông cao, Video RAM (VRAM), bao quanh các đơn vị tính toán cùng với các bộ nhớ đệm siêu nhanh giữ dữ liệu tạm thời để truy cập nhanh. VRAM là kho lưu trữ chính nơi trọng số mô hình, gradient và các lô dữ liệu đầu vào của bạn sinh sống. CPU và GPU giao tiếp với nhau qua một cầu nối giao diện, nơi thường xuyên xảy ra các nút thắt cổ chai.
Cầu nối PCIe
Như đã đề cập, dữ liệu di chuyển từ CPU sang GPU qua một cầu nối giao tiếp gọi là Peripheral Component Interconnect Express (PCIe). Dữ liệu bắt nguồn từ ổ đĩa của bạn, tải vào RAM CPU, sau đó vượt qua bus PCIe để đến VRAM của GPU. Mỗi khi bạn gửi một tensor PyTorch đến thiết bị bằng .to('cuda'), bạn đang gọi một chuyển qua cầu nối này. Nếu CPU liên tục gửi các tensor nhỏ lẻ thay vì các khối lớn liền mạch, nó sẽ nhanh chóng làm tắc nghẽn cầu nối với độ trễ và chi phí xử lý.
Đo lường hiệu suất GPU
Trước khi tối ưu hóa, chúng ta cần hiểu các chỉ số cần theo dõi. Khi sử dụng nvidia-smi, chúng ta thường phân tích hai phần trăm chính: Memory Usage và Volatile GPU-Util.
- Memory Usage (VRAM): Đây là bộ nhớ vật lý của GPU. VRAM có thể ở mức 100% dung lượng trong khi GPU không làm gì cả. Việc sử dụng VRAM cao chỉ có nghĩa là bạn đã tải thành công trọng số mô hình, gradient và một lô dữ liệu lên bộ nhớ vật lý của GPU.
- Volatile GPU-Util (Compute Utilization): Đây là chỉ số quan trọng. Nó đo phần trăm thời gian trong quá trình lấy mẫu trước đó (thường là 1 giây) mà các nhân tính toán của GPU đang thực thi lệnh tích cực. Mục tiêu là liên tục tối đa hóa phần trăm này!
 Ví dụ về đầu ra của lệnh nvidia-smi
Ví dụ về đầu ra của lệnh nvidia-smi
Nút thắt cổ chai CPU-GPU
GPU có hàng nghìn lõi sẵn sàng song song hóa các phép toán, nhưng nó cần CPU phân công nhiệm vụ. Khi huấn luyện mô hình, GPU không thể đọc trực tiếp từ SSD. CPU phải tải và giải mã dữ liệu thô, áp dụng tăng cường dữ liệu (augmentation), đóng gói (batch) và chuyển giao nó. Nếu CPU mất 50 mili giây để chuẩn bị một lô, trong khi GPU chỉ mất 10 mili giây để tính toán các lượt truyền tiến và lùi (forward và backward passes), GPU sẽ ngồi không trong 40 mili giây.
Vấn đề này được hình thức hóa trong Mô hình Roofline. Khi cường độ số học thấp (bạn tải lượng dữ liệu khổng lồ nhưng làm rất ít toán học), bạn sẽ gặp trần "Memory-Bound" (Bị giới hạn bởi bộ nhớ). Khi cường độ số học cao, bạn đạt được trần "Compute-Bound" (Bị giới hạn bởi tính toán).
Chỉ số dễ nhận thấy nhất của một đường ống GPU chưa được tối ưu hóa là biểu đồ sử dụng GPU dạng răng cưa. Đây là nơi sử dụng GPU ngồi không ở 0%, tăng vọt lên 100% trong chốc lát, sau đó lại trở về 0%, báo cáo vấn đề nút thắt cổ chai từ CPU sang GPU.
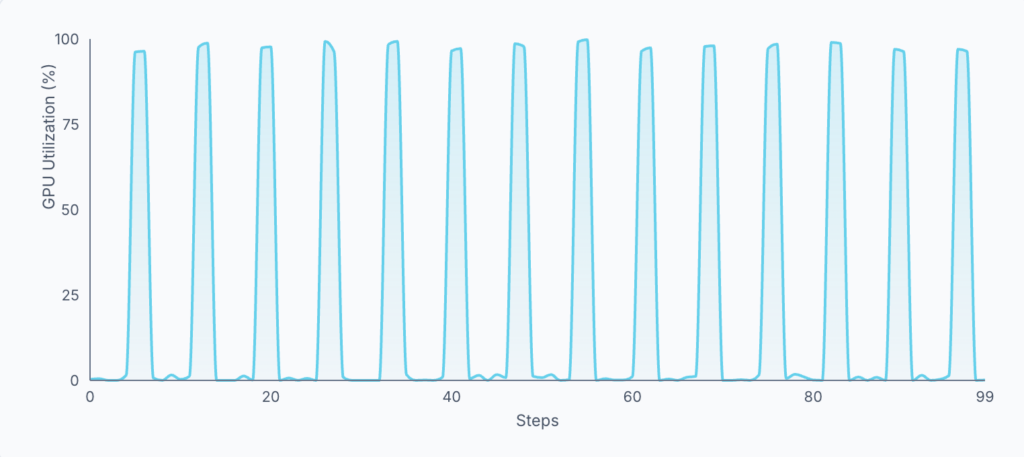 Biểu đồ sử dụng GPU dạng răng cưa thường thấy trong các đường ống ML chưa được tối ưu hóa
Biểu đồ sử dụng GPU dạng răng cưa thường thấy trong các đường ống ML chưa được tối ưu hóa
Tối ưu hóa quy trình dữ liệu
num_workers (Song song hóa CPU)
Sửa đổi có tác động lớn nhất là song song hóa việc chuẩn bị dữ liệu. Bằng cách tăng num_workers, bạn bảo PyTorch tạo ra các tiến trình con chuyên dụng để lấy và chuẩn bị các lô trong nền trong khi GPU tính toán. Tuy nhiên, nhiều worker không phải lúc nào cũng đồng nghĩa với tốc độ nhanh hơn. Một nguyên tắc tốt là bắt đầu với num_workers=4 và phân tích từ đó.
pin_memory=True (Chuyển dữ liệu tối ưu)
Thông thường, tensor không đi thẳng vào GPU khi bạn chuyển chúng. Nó được đọc từ đĩa vào RAM hệ thống và được CPU sao chép vào một vùng RAM đặc biệt (không phân trang) trước khi vượt qua bus PCIe. Thiết lập pin_memory=True tạo ra làn đường nhanh cho dữ liệu, cho phép GPU sử dụng Direct Memory Access (DMA) để kéo dữ liệu trực tiếp qua cầu nối mà không cần CPU làm trung gian.
prefetch_factor (Xếp hàng dữ liệu)
Tham số prefetch_factor quy định số lượng lô mà mỗi worker nên chuẩn bị và giữ trong hàng đợi trên CPU trước. Nếu đĩa đột ngột treo trong nửa giây do một tệp bị lỗi, GPU sẽ không bị đói dữ liệu — nó chỉ cần lấy từ hàng đợi prefetch trong khi worker theo kịp.
Bằng cách điều chỉnh các tham số này, bạn có thể làm mượt biểu đồ sử dụng dạng răng cưa thành một đường cong sử dụng liên tục, cao.
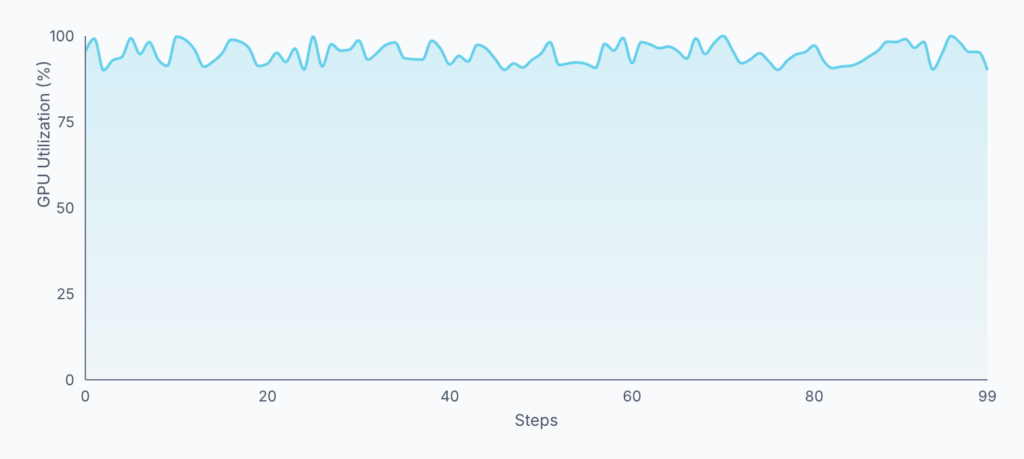 Biểu đồ sử dụng liên tục sau khi thực hiện các tối ưu hóa
Biểu đồ sử dụng liên tục sau khi thực hiện các tối ưu hóa
Tối ưu hóa tính toán và bộ nhớ trên GPU
Kích thước lô (Batch Size)
Để thoát khỏi trần "Memory-Bound" và đạt hiệu suất tối đa của GPU, bạn cần cường độ số học cao. Cách dễ nhất để tăng cường độ này là tăng kích thước lô. Việc tải một ma trận lớn duy nhất và tính toán cùng lúc hiệu quả hơn nhiều so với việc tải nhiều ma trận nhỏ tuần tự. Để có hiệu suất tối đa, hãy chọn các bội số của 32 hoặc 64 cho kích thước lô.
Độ chính xác hỗn hợp (Mixed Precision)
Theo mặc định, PyTorch khởi tạo tất cả trọng số và dữ liệu ở FP32 (32-bit). Đối với hầu hết các tác vụ deep learning, điều này là thừa thãi. Giải pháp là lượng tử hóa mô hình, chuyển tensor xuống FP16 hoặc BF16 (16-bit). Việc này giúp giảm một nửa nút thắt bộ nhớ và mở khóa phần cứng Tensor Cores trên GPU NVIDIA hiện đại. Bạn có thể sử dụng torch.autocast để tự động xử lý việc này.
Tích lũy Gradient (Gradient Accumulation)
Khi huấn luyện, thay vì cố ép một kích thước lô lớn vào VRAM và gây lỗi, hãy sử dụng một "micro-batch" nhỏ hơn. Bằng cách tích lũy gradient qua nhiều lượt truyền tiến liên tiếp, bạn tạo ra một "kích thước lô hiệu quả" mà không làm tăng dấu chân bộ nhớ VRAM.
Hiệu quả Kernel
Mỗi khi bạn thực hiện một phép toán trong PyTorch, bạn đang khởi chạy một "kernel" trên GPU. GPU phải đọc dữ liệu từ VRAM, tính toán, viết kết quả trung gian trở lại VRAM, và lặp lại quy trình. Đây là "Chi phí Kernel" (Kernel Overhead). PyTorch 2.0+ xử lý vấn đề này ngầm định với torch.compile(). PyTorch phân tích toàn bộ đồ thị tính toán và sử dụng Triton của OpenAI để tự động viết các kernel tối ưu hóa, hợp nhất (fused) giúp giảm thời gian làm việc tròn trip của bộ nhớ.
Đối với các nhu cầu chuyên sâu hơn, thư viện kernels của Hugging Face cho phép bạn tìm nạp các nhị phân đã được biên dịch trước, tối ưu hóa phần cứng trực tiếp từ Hub với một lệnh gọi hàm Python duy nhất.
Kết luận
Tối ưu hóa đường ống GPU của bạn сводится đến hai nguyên tắc cốt lõi: giữ cho GPU luôn được nạp dữ liệu và đảm bảo mọi phép toán đều đáng giá khi dữ liệu đến.
Về phía quy trình dữ liệu, việc tinh chỉnh DataLoader bằng cách tăng num_workers, bật pin_memory và đặt prefetch_factor mang lại việc sử dụng GPU liên tục hơn. Về phía tính toán, việc tối đa hóa kích thước lô (hoặc sử dụng tích lũy gradient), chuyển sang độ chính xác hỗn hợp (FP16/BF16 hoặc TF32) và hợp nhất các phép toán thông qua torch.compile() hoặc thư viện kernels của Hugging Face giúp giảm đáng kể lưu lượng truy cập VRAM và chi phí kernel.