
Tối ưu hóa RAG: Hiểu sâu về hai lớp dữ liệu quan trọng nhất trong PDF
Để xây dựng hệ thống RAG hiệu quả, việc phân tích cú pháp PDF không chỉ đơn thuần là trích xuất văn bản. Bài viết này khám phá hai lớp thông tin quan trọng: tín hiệu cấp tài liệu (metadata, nguồn gốc) và nội dung cấp trang (bố cục, bảng, hình ảnh), giúp cải thiện đáng kể độ chính xác của việc truy xuất.

Trước khi bất kỳ quá trình truy xuất (retrieval) nào diễn ra trong quy trình RAG (Retrieval-Augmented Generation), trình phân tích (parser) có một nhiệm vụ duy nhất: Đọc tài liệu giống như cách một con người sẽ làm trước khi trả lời câu hỏi về nó.
Đây là gì? Một CV, một hợp đồng bảo hiểm, một văn bản quy phạm pháp luật, hay một bài báo khoa học? Nó có bao nhiêu trang? Là tài liệu số sinh ra (born-digital) hay được quét từ bản giấy, hay là sự kết hợp của cả hai? Nó chứa đựng những gì: đoạn văn, bảng biểu, bố cục đa cột, hình ảnh nhúng? Và bằng ngôn ngữ nào?
Mỗi kiểm tra như vậy là một trường hợp thất bại tiềm tàng mà phần còn lại của quy trình xử lý không thể phục hồi. Nếu trình phân tích không hiểu rõ bản chất của tài liệu ngay từ đầu, hệ thống RAG sẽ hoạt động dựa trên sự phỏng đoán sai lầm.
Bài viết này sẽ đi sâu vào hai lớp dữ liệu của một PDF mà mọi kỹ sư xây dựng hệ thống RAG cần phải nắm vững để đảm bảo chất lượng đầu ra.
 Hai lớp thông tin của PDF
Hai lớp thông tin của PDF
Lớp 1: Tín hiệu cấp tài liệu (Document-level signals)
Một PDF cung cấp hai loại thông tin chính. Tín hiệu cấp tài liệu bao gồm: metadata (siêu dữ liệu), bookmarks (dấu trang) gốc, và các thuộc tính được khai báo. Đây là những thông tin mà trình phân tích đọc đầu tiên để định hình chiến lược xử lý.
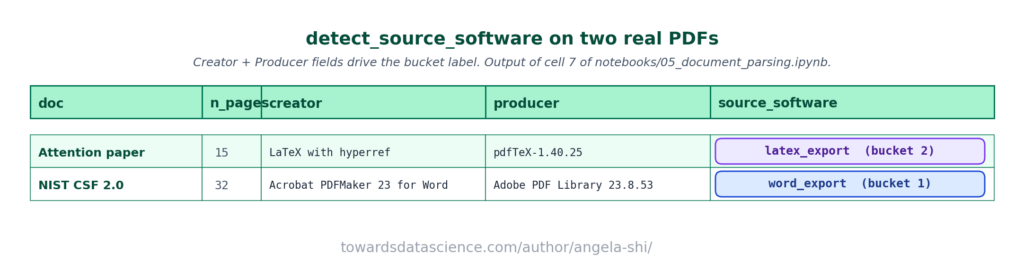
Phần mềm nguồn (Source software)
Hầu hết các PDF đều quảng cáo nguồn gốc của chúng thông qua các trường Creator và Producer. Tín hiệu duy nhất này cho chúng ta biết mức độ khó khăn của việc phân tích tiếp theo.
Các phần mềm tạo PDF thường rơi vào 5 nhóm chính, được sắp xếp từ dễ đến khó phân tích:
- Công cụ văn phòng (Dễ nhất): Microsoft Word, PowerPoint, Google Docs, v.v. Chúng bảo toàn cấu trúc logic (tiêu đề, danh sách, đoạn văn) với phông chữ vector gốc. Trích xuất văn bản trực tiếp hoạt động rất tốt.
- Bộ xử lý tài liệu: LaTeX, Pandoc, Quarto. Tính trung thực của văn bản cao nhưng có những đặc thù riêng như ngắt từ bằng dấu gạch nối, toán học được hiển thị dưới dạng đường dẫn vector hoặc hình ảnh.
- Công cụ thiết kế và xuất bản: Adobe InDesign, Illustrator. Thường có bố cục đa cột phức tạp, làm cho thứ tự đọc bị rối loạn nếu chỉ dùng các công cụ cơ bản.
- Đường ống in và nén lại: In từ trình duyệt (Chrome, Safari), Ghostscript, qpdf. Chất lượng hỗn hợp; thường mất siêu liên kết và dấu trang.
- Phần mềm quét và ứng dụng chụp (Khó nhất): Kofax, ABBYY, Adobe Scan. Đây là hình ảnh thuần túy, không có văn bản gốc. Yêu cầu OCR bắt buộc.
Việc phát hiện chính xác nguồn gốc phần mềm giúp hệ thống định tuyến tài liệu đến chiến lược xử lý phù hợp (ví dụ: chuyển thẳng sang OCR nếu phát hiện là file quét).
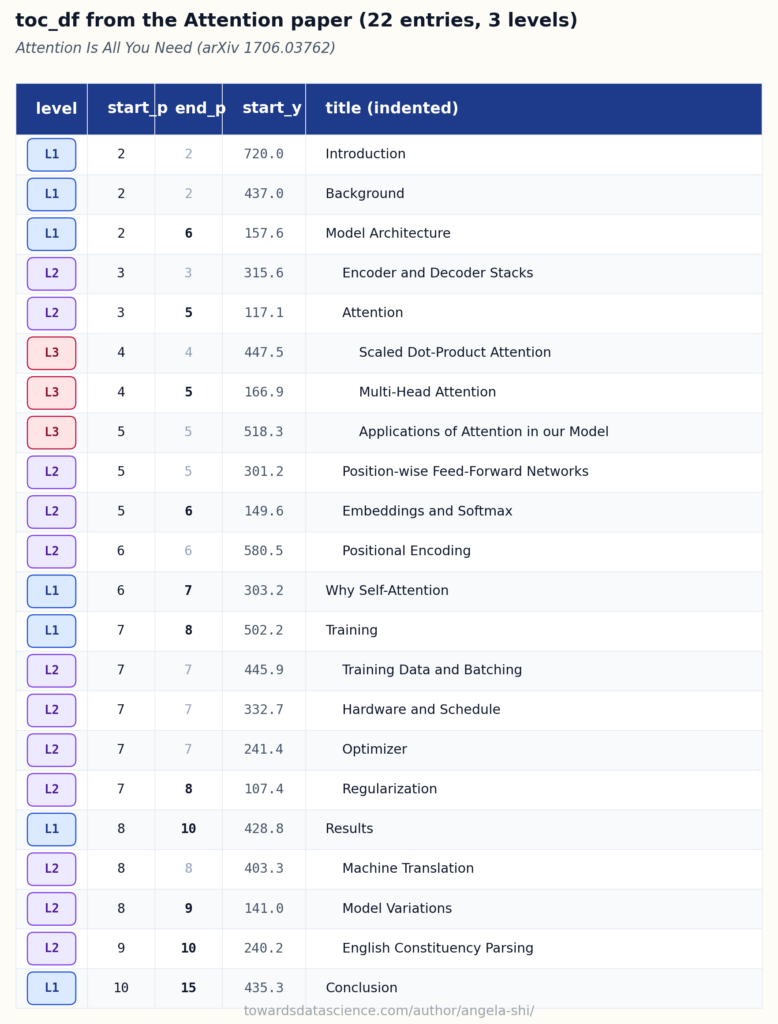
Mục lục gốc (Native Table of Contents)
PyMuPDF (một thư viện Python miễn phí) cung cấp doc.get_toc() để truy cập cấu trúc mục lục của tài liệu. Khi tài liệu có mục lục, chúng ta coi đó là cấu trúc được khai báo: tài liệu đang cho chúng ta biết cách nó tổ chức nội dung.
Nếu tài liệu không có mục lục (phổ biến ở các file quét hoặc xuất nhanh), việc tái tạo mục lục từ các tín hiệu kiểu dáng (dòng chữ in đậm lớn, mẫu số) là một bài toán riêng biệt phức tạp hơn.
Lớp 2: Nội dung cấp trang (Page-level content)
Sau khi đọc metadata, chúng ta đi qua từng trang. Nội dung là sự thật tuyệt đối (ground truth). Khi metadata và nội dung mâu thuẫn, chúng ta tin vào nội dung.
 Quy trình phân tích nội dung trang
Quy trình phân tích nội dung trang
Văn bản và chế độ hiển thị (Render mode)
Văn bản là thành phần quan trọng nhất. Một cờ quan trọng là render_mode: mã cấp PDF cho biết văn bản được viết gốc hay được đặt vô hình bởi một lớp OCR trên hình ảnh được quét.
Chế độ render 3 có nghĩa là văn bản được vẽ vô hình: một lớp mà phần mềm OCR đặt dưới hình ảnh trang để quét có thể tìm kiếm được. Phân biệt chế độ này với văn bản gốc là cách duy nhất đáng tin cậy để biết liệu một trang quét đã có lớp tìm kiếm usable hay cần phải chạy OCR lại.
Hình ảnh và độ phủ trang
Hình ảnh đứng thứ hai vì chúng thường chứa văn bản hoặc thông tin thị giác quan trọng. Một bẫy phổ biến là page.get_images() trả về kích thước nội tại của hình ảnh, không phải diện tích hiển thị trên trang.
Để tính độ phủ thực sự, chúng ta sử dụng page.get_image_info(). Nếu một hình ảnh chiếm ≥ 95% diện tích trang, xác suất cao đó là một trang được quét. Ngưỡng 95% là kinh nghiệm thực nghiệm, cho phép dung sai cho các lề nhỏ mà máy quét thêm vào.
Bảng vector và Cột
Bảng không nên được chia nhỏ (chunk) như văn bản chạy. PyMuPDF phát hiện các bảng vector (được xây dựng từ các đường kẽ kết hợp với văn bản gốc) thông qua page.find_tables().
Đối với các bảng được quét dưới dạng hình ảnh, cần các công cụ thị giác (như Camelot, Docling) để phát hiện.
Phát hiện cột cũng rất quan trọng. Bố cục hai cột sẽ phá vỡ thứ tự đọc ngây thơ: một bài báo khoa học được phân tích mà không nhận biết cột sẽ trả về dòng 1 của cột trái, sau đó là dòng 1 của cột phải... tạo ra các đoạn văn vô nghĩa.
Thay vì cố gắng khôi phục thứ tự đọc hoàn hảo, giải pháp thực tế là gán nhãn từng dòng dựa trên vị trí ngang của nó: single (một cột), left/right (hai cột), hoặc multi (ba cột trở lên).
Vùng ngữ nghĩa: Tóm tắt bằng LLM
Các tín hiệu cấu trúc ở trên là những gì một trình phân tích xác định có thể tạo ra trong vài giây mà không cần gọi mô hình. Tuy nhiên, chúng không cho biết tài liệu đó nói về điều gì.
Đây là lúc một tóm tắt văn bản ngắn do LLM viết ra đóng vai trò then chốt. Một cuộc gọi LLM tại thời điểm phân tích, được cung cấp một hoặc hai trang đầu tiên, yêu cầu trả về ba đến bốn câu nêu loại tài liệu, chủ đề chính và các trường dữ liệu nó chứa.
Ví dụ, với một CV một trang của "Sarah Mitchell", kết quả có thể như sau:
"CV một trang của Sarah Mitchell, một Data Analyst tại London với khoảng bốn năm kinh nghiệm. Liệt kê các vị trí tại Northwind Retail và Brightwave Insurance, bằng Cử nhân Thống kê từ Leeds, và các kỹ năng về Python, SQL, BigQuery và Power BI. Các phần CV tiêu chuẩn: Tóm tắt, Kinh nghiệm, Giáo dục, Kỹ năng."
Thông tin này được lưu vào parsing_summary và được đưa vào system prompt của trình phân tích câu hỏi. Khi người dùng hỏi "Tên cô ấy là gì?", trình phân tích không cần tìm kiếm từ khóa "name" trong văn bản (vì tên có thể nằm trong logo hình ảnh), mà đã biết từ trước tài liệu này nói về Sarah Mitchell.
 Ví dụ phân tích CV
Ví dụ phân tích CV
Kết luận
Một PDF thực chất là hai tài liệu xếp chồng lên nhau: các tín hiệu được khai báo (metadata, mục lục, phần mềm nguồn) và nội dung cấp trang (văn bản so với quét, hình ảnh, bảng, cột). Trình phân tích đọc chúng theo thứ tự đó và tin vào nội dung trang khi hai thứ này mâu thuẫn.
Mỗi tín hiệu được lưu tại thời điểm phân tích trở thành một cột dữ liệu mà phần còn lại của quy trình pipeline có thể truy vấn. Sự khác biệt giữa một trình phân tích chỉ trả về một chuỗi văn bản phẳng và một trình phân tích trả về dữ liệu có cấu trúc nằm ngay ở đây: ở những tín hiệu mà nó quan tâm ghi lại.
Bài viết tiếp theo sẽ đi sâu vào cách chuyển đổi các tín hiệu này thành các DataFrame quan hệ mà hệ thống RAG tiêu thụ từ đầu đến cuối.
Bài viết liên quan

Công nghệ
Google thay đổi hoàn toàn thanh tìm kiếm: Bước nhảy vọt với Gemini 3.5 Flash và Tác nhân AI
19 tháng 5, 2026

Phần mềm
Tấn công Cache Poisoning biến các gói npm TanStack thành mối đe dọa nguy hiểm
12 tháng 5, 2026

Phần mềm
Epic Games giới thiệu Lore: Hệ thống kiểm soát phiên bản mã nguồn mở thế hệ mới
17 tháng 6, 2026