
Tối ưu hóa RAG: Tại sao bạn cần mô hình dữ liệu quan hệ thay vì văn bản phẳng từ PDF?
Các hệ thống RAG doanh nghiệp thường thất bại khi xử lý tài liệu phức tạp do việc trích xuất văn bản phẳng làm mất cấu trúc quan trọng. Bài viết này giới thiệu phương pháp chuyển đổi PDF thành tập hợp các bảng dữ liệu quan hệ (DataFrames) liên kết để bảo toàn ngữ cảnh. Giải pháp này giúp cải thiện độ chính xác của truy xuất thông tin và giảm chi phí tính toán.

Trong thế giới phát triển các hệ thống RAG (Retrieval-Augmented Generation) cho doanh nghiệp, một trong những sai lầm phổ biến nhất là bắt đầu bằng cách gọi một hàm đơn giản: text = extract_text(pdf). Cách tiếp cận này có thể hoạt động với một vài tài liệu sạch, nhưng khi khách hàng gửi đến một hợp đồng 30 trang chứa bảng biểu phức tạp, mô hình của bạn sẽ bắt đầu gặp rắc rối.
Vấn đề không phải là mô hình ngôn ngữ (LLM) không thể đọc bảng, mà là do trình phân tích (parser) ở thượng lưu đã làm mất cấu trúc dữ liệu ngay từ đầu. Khi các ô trong bảng được nối lại thành một chuỗi văn bản dài vô nghĩa, mối liên hệ giữa nhãn và số liệu bị cắt đứt. Để giải quyết vấn đề này, chúng ta cần ngừng trích xuất văn bản phẳng và bắt đầu mô hình hóa tài liệu dưới dạng một tập hợp các bảng dữ liệu quan hệ.
 Mô hình quan hệ của tài liệu
Mô hình quan hệ của tài liệu
Từ văn bản phẳng đến mô hình quan hệ
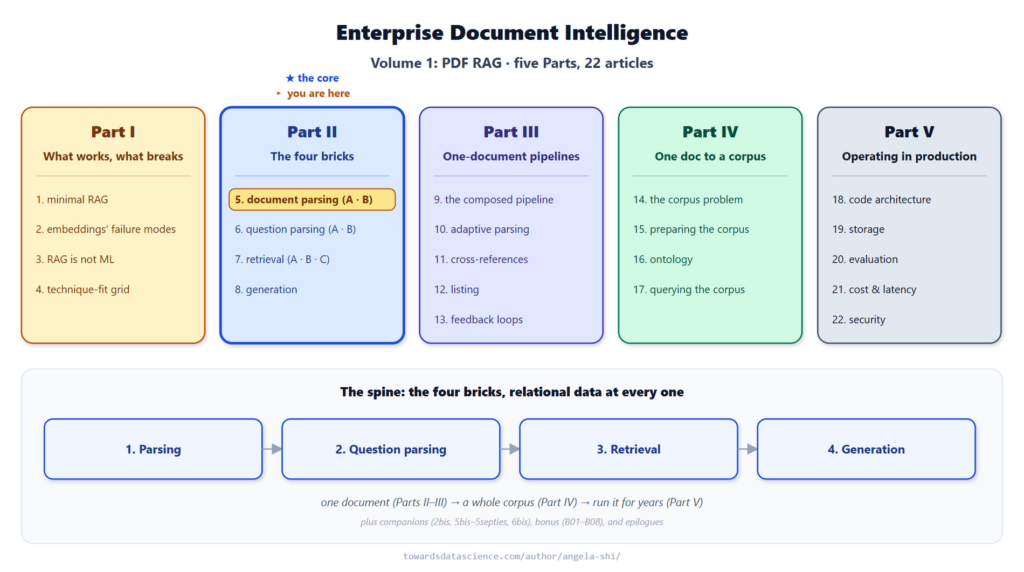
Thay vì trả về một chuỗi văn bản duy nhất, một trình phân tích PDF tốt nên trả về một từ điển gồm nhiều bảng (DataFrames), mỗi bảng tương ứng với một thực thể trong tài liệu. Cách tiếp cận này cho phép hệ thống RAG truy vấn dữ liệu có cấu trúc thay vì phải đoán mò từ một khối văn bản hỗn loạn.
Dưới đây là các bảng dữ liệu cốt lõi构成了 một mô hình hoàn chỉnh:
- toc_df (Mục lục): Chứa các phần của tài liệu như tác giả đã viết. Đây là tín hiệu ngữ nghĩa rẻ tiền nhất giúp retriever hiểu cấu trúc tài liệu.
- page_df và line_df: Phần thân của tài liệu, ghi lại từng trang và từng dòng văn bản.
- image_df: Mọi hình ảnh, biểu đồ trên mỗi trang.
- span_df: Thông tin về kiểu chữ (in đậm, in nghiêng, màu sắc, kích thước font) ở cấp độ nhỏ hơn dòng.
- object_registry: Đăng ký mọi chú thích hình ảnh, bảng biểu, phụ lục.
- cross_ref_df: Mọi tham chiếu chéo như "xem Hình 2", "xem Bảng 4".
- parsing_summary: Tóm tắt kỹ thuật, cho biết PDF là sinh số hay quét, chất lượng OCR tốt hay xấu.
Cách các bảng liên kết với nhau
Sức mạnh thực sự của mô hình này nằm ở cách các bảng liên kết với nhau. Hầu hết mọi liên kết đều giải quyết về line_df - nguồn sự thật cấp dòng.
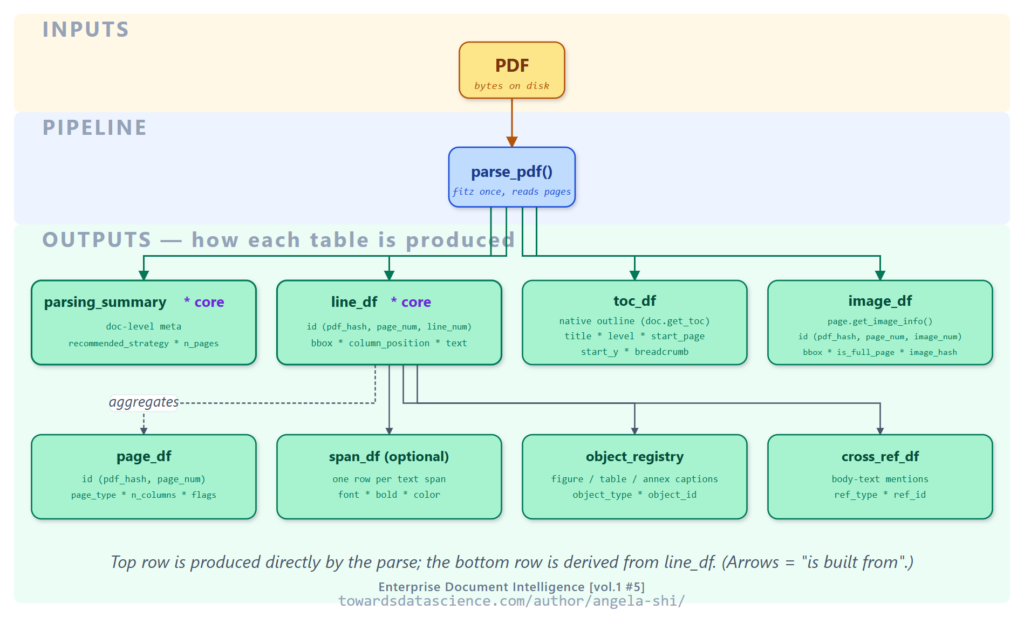
Ví dụ, khi người dùng hỏi "Tóm tắt mục 3.5", hệ thống không cần tìm kiếm từ khóa hay tính toán vector nhúng. Nó chỉ cần tra cứu start_page và end_page trong toc_df, sau đó lọc các dòng tương ứng trong line_df. Hoặc khi hỏi "Tổng tiền là bao nhiêu?" trong một hóa đơn, nếu trình phân tích đã xác định vị trí cột (trái/phải), câu trả lời chỉ là một câu lệnh truy vấn đơn giản vào các dòng ở cột phải.
 Ví dụ về hóa đơn với các cột được phân tích
Ví dụ về hóa đơn với các cột được phân tích
Ứng dụng thực tế trên các tài liệu khác nhau
Để chứng minh tính hiệu quả, phương pháp này đã được thử nghiệm trên hai tài liệu hoàn toàn khác nhau: một bài báo nghiên cứu LaTeX (Attention paper) và Khung an ninh mạng NIST 2.0. Kết quả cho thấy cùng một hàm parse_pdf có thể trả về cấu trúc dữ liệu đồng nhất cho cả hai, bất kể sự khác biệt về bố cục.
Đặc biệt, với các hóa đơn hoặc tài liệu có nhiều cột, việc xác định column_position là cực kỳ quan trọng. Thay vì xử lý hình ảnh (vision pass) phức tạp, hệ thống có thể tách biệt mô tả (cột trái) và số tiền (cột phải) ngay từ giai đoạn phân tích ban đầu.
Lưu trữ và tái sử dụng
Phân tích tài liệu (parsing) là bước tốn kém nhất trong quy trình RAG. Với các tài liệu quét cần OCR, thời gian xử lý có thể lên tới vài phút. Do đó, chiến lược "Lưu một lần, tải lại mãi mãi" là bắt buộc.
Mỗi PDF được phân tích sẽ lưu các bảng quan hệ của nó vào một thư mục mirror dưới dạng file Excel (.xlsx) hoặc JSON. Các bước tiếp theo như truy xuất, tạo câu trả lời (generation) hay chú thích sẽ chỉ đọc dữ liệu từ các bảng này mà không bao giờ chạm lại file PDF gốc. Điều này biến độ trễ 30 giây mỗi câu hỏi thành chi phí cố định một lần cho toàn bộ kho tài liệu.
Kết luận
Một trình phân tích RAG tốt không chỉ trích xuất văn bản; nó chuyển đổi một PDF phi cấu trúc thành một mô hình dữ liệu quan hệ. Bằng cách duy trì cấu trúc, ngữ cảnh và các mối liên kết giữa các phần tử, chúng ta cung cấp cho mô hình ngôn ngữ một nền tảng vững chắc để hoạt động. Chi phí kỹ thuật đầu tư cho bước phân tích này sẽ được hoàn trả thông qua tốc độ và độ chính xác vượt trội của toàn bộ hệ thống RAG sau này.
Bài viết liên quan

Phần mềm
Tấn công Cache Poisoning biến các gói npm TanStack thành mối đe dọa nguy hiểm
12 tháng 5, 2026

Phần mềm
Epic Games giới thiệu Lore: Hệ thống kiểm soát phiên bản mã nguồn mở thế hệ mới
17 tháng 6, 2026

Phần mềm
Shii haa: Ứng dụng biến micro điện thoại thành cảm biến phát hiện nhịp thở
02 tháng 6, 2026