
Trí tuệ Tài liệu Doanh nghiệp: Hướng dẫn xây dựng RAG thực chiến, từ tối giản đến quy mô lớn
Chuỗi bài viết này dành cho các kỹ sư AI muốn xây dựng hệ thống RAG (Retrieval-Augmented Generation) cho tài liệu doanh nghiệp một cách bài bản. Thay vì chỉ gọi thư viện, tác giả tập trung vào kỹ thuật nền tảng, hiểu rõ lĩnh vực kinh doanh và kiến trúc bốn bước: phân tích cú pháp, phân tích câu hỏi, truy xuất và tạo sinh.
Khoảng ba năm trước, khi AI tạo sinh (Generative AI) bùng nổ, RAG (Retrieval-Augmented Generation) nổi lên như là câu trả lời tiêu chuẩn cho bài toán: "chúng ta có tài liệu, và chúng ta muốn đặt câu hỏi". Về lý thuyết, giải pháp này nghe có vẻ kỳ diệu. Cách triển khai mà mọi người mô tả lặp đi lặp lại y hệt nhau: chia nhỏ tài liệu (chunk), đẩy các đoạn vào kho lưu trữ vector (vector store), nhúng câu hỏi (embed), truy xuất top-k bằng độ tương đồng cosine (tùy chọn rerank), và gửi kết quả cho LLM.
Các nhà cung cấp giải pháp, các công ty tư vấn và các hội thảo đều đồng thuận theo một công thức chung.
 Công thức RAG phổ biến: chunk, vector store, top-k cosine, optional rerank, LLM
Công thức RAG phổ biến: chunk, vector store, top-k cosine, optional rerank, LLM
Tuy nhiên, khi bắt đầu đưa vào triển khai thực tế, kết quả thường gây thất vọng. Người dùng không tin tưởng vào câu trả lời, các trích dẫn (citations) mơ hồ hoặc bị thiếu, và các đoạn văn được truy xuất thường lạc đề. Phản ứng thường thấy của các đội kỹ thuật là thêm nhiều công cụ hơn vào cùng một bộ công cụ: mô hình mạnh hơn, cửa sổ ngữ cảnh (context window) dài hơn, reranker tốt hơn, và nhiều MLOps hơn.
Tư duy chung luôn là: "đây là vấn đề CNTT. Cơ sở hạ tầng tốt hơn, công cụ tốt hơn, mô hình tốt hơn sẽ giải quyết được nó".
Nhưng khi tôi tự mình thực hiện trên các tài liệu doanh nghiệp thực tế với sự hỗ trợ của các chuyên gia trong lĩnh vực, tôi nhận ra trải nghiệm thực tế không đi theo hướng đó. Công việc thực sự tạo ra sự khác biệt không phải là hạ tầng, mà là kỹ thuật kết hợp với việc hiểu rõ lĩnh vực kinh doanh và một chút toán học nền tảng. Điểm mấu chốt nằm ở việc hiểu rõ tài liệu mà hệ thống cần trả lời: ai đọc chúng, chúng chứa đựng điều gì, từ vựng chuyên gia sử dụng là gì, và những câu hỏi nào lặp đi lặp lại hàng tuần.
Hầu hết các công ty không phải là Google hay các phòng thí nghiệm nghiên cứu. Họ không chạy hệ thống QA trên toàn bộ web mở. Họ có một vài loại tài liệu cốt lõi, vài chục chuyên gia lĩnh vực đã thuộc lòng nội dung, và một tập hợp các câu hỏi lặp lại cần câu trả lời có trích dẫn và quy trình kiểm toán. Kiến trúc đúng đắn cho bối cảnh này không phải là những gì các nhà cung cấp quảng cáo, mà là kiến trúc khuếch đại chuyên gia và sử dụng khả năng truy xuất rẻ tiền, có thể dự đoán ở nơi có thể.
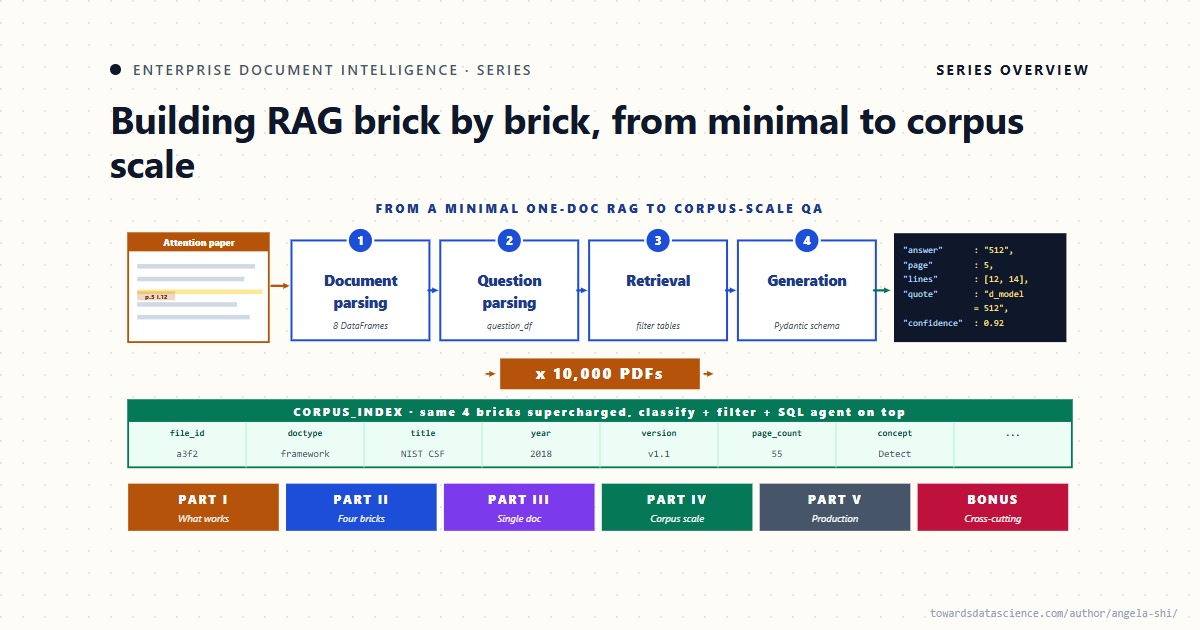
Bốn viên gạch xây dựng hệ thống
Thay vì chỉ gọi một thư viện RAG có sẵn, chuỗi bài viết này sẽ tiếp cận vấn đề theo hướng xây dựng từng "viên gạch" (brick). Chúng ta sẽ xây dựng một quy trình gồm bốn viên gạch chính: phân tích tài liệu (parsing), phân tích câu hỏi (question parsing), truy xuất (retrieval), và tạo sinh (generation), cùng với một bước tùy chọn là chú thích PDF.
 Bốn viên gạch chính của quy trình xử lý tài liệu
Bốn viên gạch chính của quy trình xử lý tài liệu
Mỗi viên gạch này đều tạo ra dữ liệu có cấu trúc quan hệ (relational structured data) chứ không phải là các chuỗi thô (raw strings). Điều này giúp quy trình có thể được kiểm tra, chạy lại và kiểm toán tại mọi điểm nối.
1. Phân tích tài liệu (Parsing)
Đây là bước nền tảng. Nếu thông tin bị mất ở bước phân tích cú pháp, không thể nào lấy lại được ở các bước sau. Một trình phân tích tốt sẽ trích xuất các dòng, bảng, hình ảnh, cột, mục lục và các tham chiếu chéo.
2. Phân tích câu hỏi (Question Parsing)
Trước khi tìm kiếm, chúng ta cần cấu trúc câu hỏi. Một câu hỏi đầu vào không cấu trúc sẽ được phân tích thành một tập hợp các bảng quan hệ, đối xứng với việc phân tích tài liệu. Điều này giúp hệ thống hiểu rõ ý định và phạm vi của câu hỏi.
3. Truy xuất (Retrieval)
Trong môi trường doanh nghiệp, truy xuất không chỉ đơn thuần là tìm kiếm độ tương đồng vector. Các chuyên gia đã biết từ khóa. Kho vector chỉ nên dùng khi truy xuất từ khóa thất bại (ví dụ: đồng nghĩa, đa nghĩa). Trên hầu hết các kho tài liệu doanh nghiệp, truy xuất dựa trên cấu trúc (mục lục, phân loại, từ khóa chuyên gia) thường hoạt động hiệu quả hơn độ tương đồng cosine.
4. Tạo sinh (Generation)
Đây là bước thực thi có kiểm soát. Đầu vào có kiểu (typed input) và đầu ra cũng có kiểu (typed output) sử dụng các schema như Pydantic. Schema chính là hợp đồng; một mẫu prompt cho mỗi hình dạng câu trả lời.
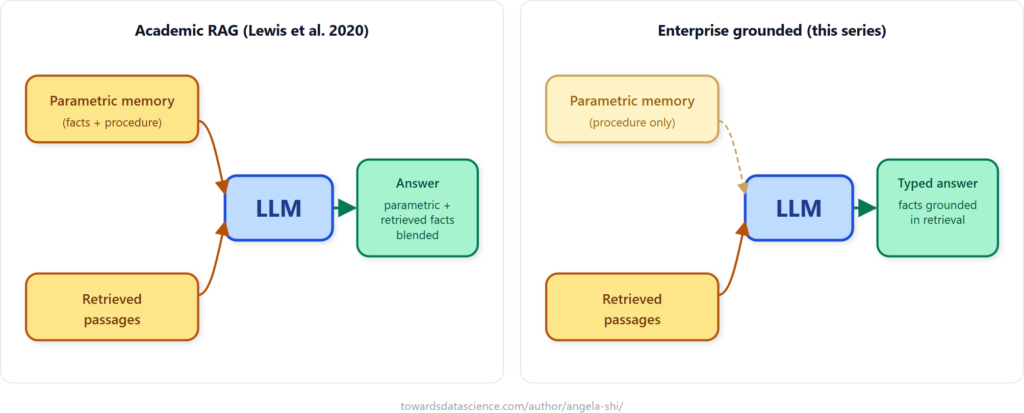
Từ "Tăng cường" sang "Neo" (Grounded)
Một sự thay đổi quan trọng trong tư duy của chuỗi bài viết này là chuyển từ "Augmented" (Tăng cường) sang "Grounded" (Neo). Trong khung năm 2020, bộ tạo sinh (generator) được phép kết hợp bộ nhớ tham số của nó với các đoạn văn được truy xuất. Tuy nhiên, trong sản xuất doanh nghiệp, mọi nhận định thực tế đều phải được hỗ trợ bởi một đoạn văn được truy xuất; bộ nhớ tham số của LLM bị loại khỏi nội dung thực tế của câu trả lời và chỉ được dùng cho các mục đích quy trình như ngữ pháp, tuân thủ schema, hoặc trích xuất verbatim.
Khi LLM viết lại một điều khoản thành một trường JSON như coverage_amount: 50000, việc viết lại này tuân theo ngữ pháp và cú pháp JSON — đó là quy trình. Nhưng khi nó điền ngày tháng không có trong văn bản được truy xuất vào trường valid_until, đó là thực tế và chúng ta phải chặn nó lại.
Chuỗi bài viết này dành cho ai?
Đây là chuỗi bài viết dành cho các kỹ sư và nhà khoa học dữ liệu đang xây dựng RAG trên các tài liệu doanh nghiệp: hợp đồng, báo cáo kỹ thuật, hồ sơ pháp lý, nơi một câu trả lời sai có thể dẫn đến tranh chấp pháp lý hoặc hoàn tiền cho khách hàng.
Chuỗi bài viết này không dành cho các nhóm không có chuyên gia nội bộ về tài liệu, hay các nhà nghiên cứu đang tìm kiếm các phương pháp mới lạ. Nó dành cho những người muốn hiểu rõ những gì đang diễn ra dưới các khung framework phổ biến để đưa ra các lựa chọn có chủ đích. Đôi khi điều đó có nghĩa là sử dụng một framework, nhưng thường xuyên hơn là viết khoảng một trăm dòng mã thuần hoạt động tốt hơn những gì framework cung cấp.
Trong các bài viết tiếp theo, chúng ta sẽ đi sâu vào từng viên gạch, bắt đầu từ một quy trình RAG tối giản chỉ khoảng 100 dòng Python, không có cơ sở dữ liệu vector, không framework và không agent, để thấy rõ cách hệ thống hoạt động và tại sao hiểu rõ tài liệu lại quan trọng hơn tất cả các công cụ hào nhoáng.


