
Từ 4 Tuần Đến 45 Phút: Thiết Kế Hệ Thống Trích Xuất Thông Tin Từ Hơn 4.700 Tệp PDF
Một hệ thống kết hợp PyMuPDF và GPT-4 Vision giúp rút ngắn thời gian trích xuất giá trị revision từ hàng nghìn bản vẽ kỹ thuật PDF từ 4 tuần xuống chỉ còn 45 phút, tiết kiệm gần £8.000 chi phí lao động so với phương pháp thủ công.
Từ 4 Tuần Đến 45 Phút: Thiết Kế Hệ Thống Trích Xuất Thông Tin Từ Hơn 4.700 Tệp PDF
Một dự án trích xuất số revision (REV) từ hàng nghìn bản vẽ kỹ thuật PDF đã được hoàn thành trong vòng chưa đến một giờ, thay vì mất tới 4 tuần với phương pháp thủ công. Bằng cách kết hợp giữa PyMuPDF để xử lý văn bản lập trình và mô hình GPT-4 Vision cho những trường hợp phức tạp, hệ thống này đã tiết kiệm khoảng hơn 8.000 bảng Anh chi phí lao động đồng thời đảm bảo độ chính xác cao và hiệu năng vượt trội.
Bối cảnh và thách thức
Một nhóm kỹ sư cần trích xuất thông tin số REV của hơn 4.700 bản vẽ kỹ thuật trong quá trình di chuyển dữ liệu sang hệ thống quản lý tài sản mới. Mỗi tệp PDF chứa một giá trị REV nhỏ, nằm trong khung tiêu đề (title block), việc nhập tay từng file tốn khoảng 2 phút, tổng cộng là 160 giờ kỹ sư - tương đương chi phí hơn £8,000.
Tuy nhiên, đây không chỉ là bài toán AI đơn thuần mà là một vấn đề thiết kế hệ thống phức tạp với nhiều ràng buộc: đa dạng định dạng file (có file text-based, có file hình ảnh scan), yêu cầu độ chính xác cao, chi phí giới hạn, và cần kết quả đáng tin cậy cho người dùng cuối.
Đặc thù phức tạp của bản vẽ kỹ thuật PDF
Các bản vẽ kỹ thuật không phải PDF thông thường. Có bản vẽ được tạo từ CAD dưới dạng text-based PDF có thể trích xuất văn bản trực tiếp. Nhưng khoảng 20-30% là PDF dạng ảnh scan, không có lớp text, chỉ có raster image.
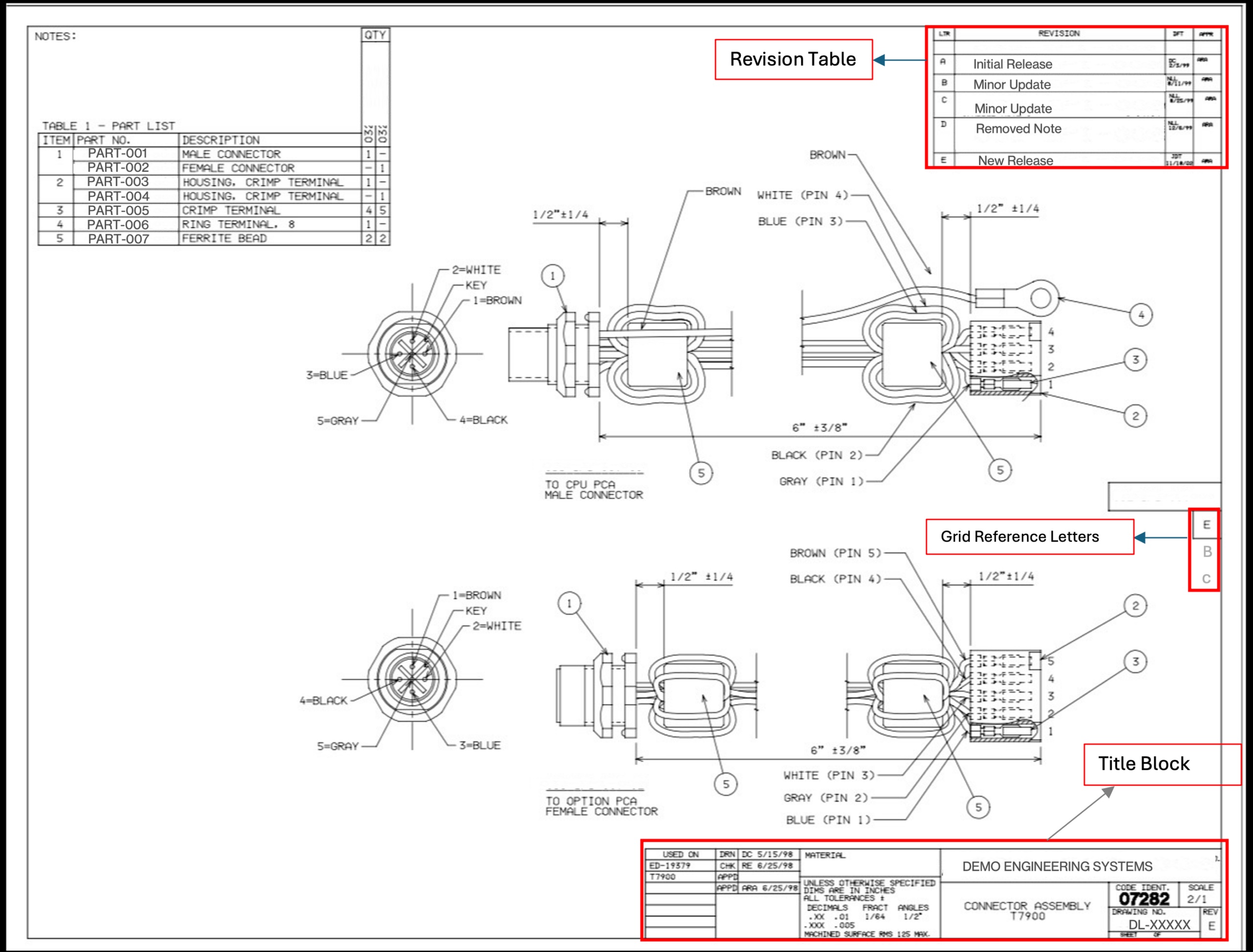
Giá trị REV trong bản vẽ có nhiều dạng khác nhau: số kèm dấu gạch nối (ví dụ 1-0, 2-0), một hay hai chữ cái (A, B, AA,...), hoặc có khi bỏ trống. Thêm nữa, các bản vẽ có thể xoay 90 hoặc 270 độ, có bảng lịch sử revision đa dòng dễ gây nhầm lẫn, hay các ký tự grid trên viền dễ bị nhầm với REV.
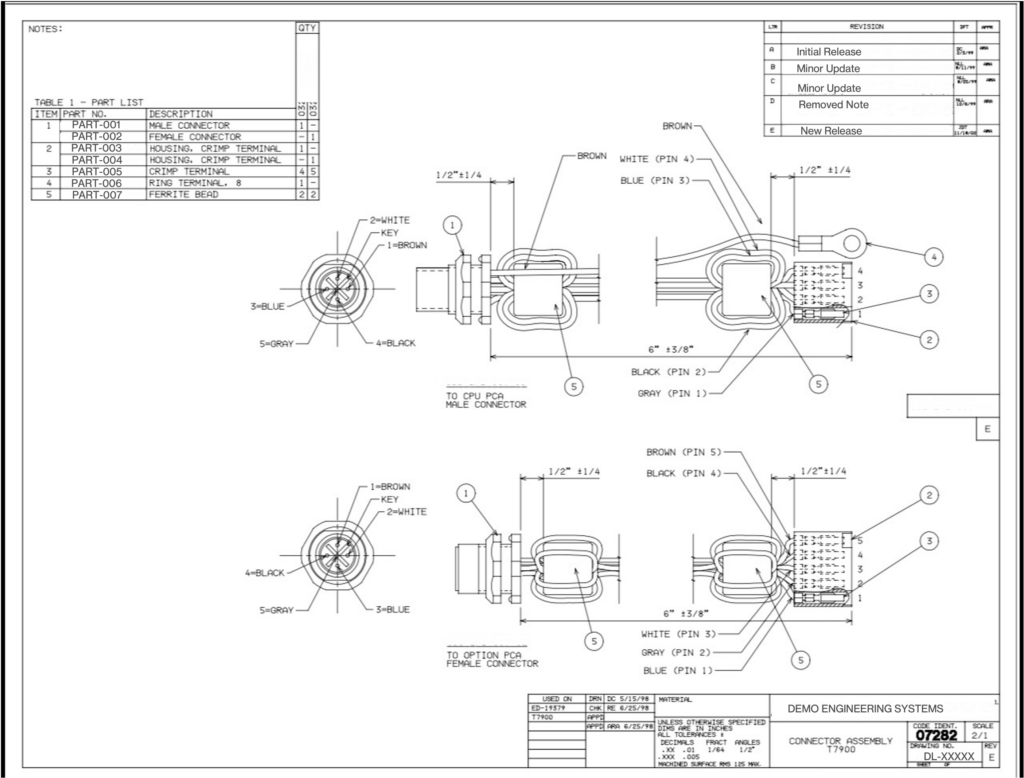 Bản vẽ kỹ thuật minh họa các vùng cần quan tâm
Bản vẽ kỹ thuật minh họa các vùng cần quan tâm
Vì sao giải pháp hoàn toàn AI không khả thi
Sử dụng toàn bộ GPT-4 Vision cho 4.700 file sẽ tốn khoảng 100 phút gọi API và chi phí lên đến 47 USD, trong khi nhiều tệp có thể trích xuất nhanh bằng vài dòng Python với PyMuPDF.
Ý tưởng cốt lõi là áp dụng API AI chỉ khi phương pháp quy tắc (rule-based) không xử lý nổi. Cách này tối ưu cả chi phí, thời gian và độ chính xác.
Kiến trúc pipeline trích xuất hybrid
Hệ thống gồm 2 giai đoạn:
-
Giai đoạn 1: Dùng PyMuPDF để trích xuất text theo quy tắc (zero-cost). Tập trung vào góc dưới bên phải trang, nơi chứa khung tiêu đề. Tìm kiếm gần các anchor từ như "REV", "DWG NO", "SHEET", "SCALE". Áp dụng hàm điểm để lọc ra kết quả phù hợp nhất.
-
Giai đoạn 2: Với những file không trích xuất được (thường là dạng hình ảnh hoặc phức tạp), chuyển trang đầu thành ảnh PNG ở độ phân giải 150 DPI, gửi cho GPT-4 Vision thông qua Azure OpenAI để nhận diện.
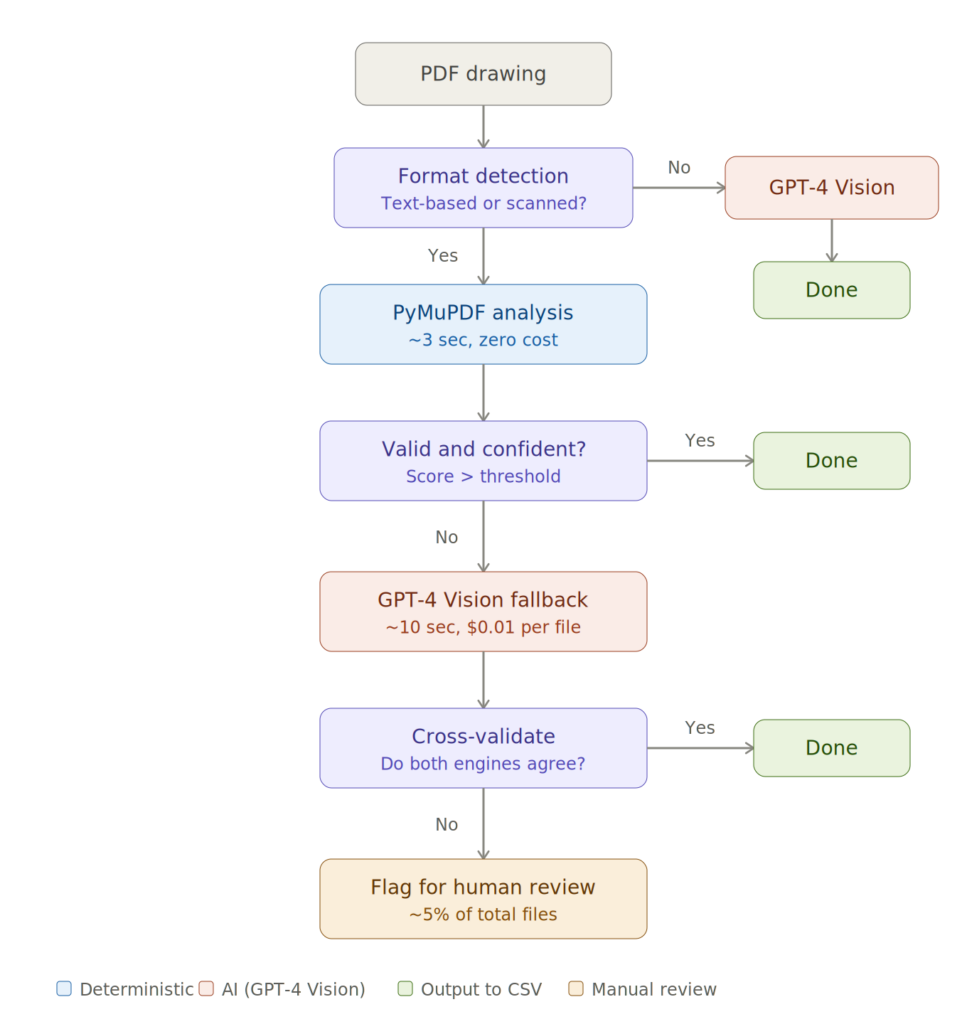 Sơ đồ kiến trúc pipeline hai giai đoạn
Sơ đồ kiến trúc pipeline hai giai đoạn
Các vấn đề thực tế và cách xử lý
-
Xác định xoay trang: Metadata xoay PDF không đồng nhất. Nếu PyMuPDF không đọc được đủ đoạn text từ trang chưa xoay, hệ thống tự động xoay trước khi gửi cho AI.
-
Ngăn ngừa sai sót do 'prompt hallucination': Lệnh mẫu trong prompt có thể khiến GPT-4 lặp lại giá trị sai lệch. Giải pháp là đa dạng hoá các ví dụ hợp lệ và cảnh báo rõ ràng không được lấy giá trị từ bảng lịch sử revision hay phần grid chữ cái cạnh trang.
Kết quả thực tế và đánh đổi
Trên mẫu 400 file đối chiếu, pipeline hybrid đạt độ chính xác 96%, chỉ thấp hơn 2% so với GPT-4 Vision chạy toàn bộ 100% file (98%), nhưng tiết kiệm được nửa giờ xử lý và chi phí giảm từ $47 xuống $10-15. Tỷ lệ cần kiểm tra thủ công cũng chỉ 5%.
Đối với nhiều ứng dụng trong doanh nghiệp, đây là mức cân bằng hợp lý giữa chi phí, tốc độ và độ chính xác.
Bài học cho người làm AI engineering
-
Bắt đầu với giải pháp rẻ nhất có hiệu quả. Không nên vội vàng áp dụng AI cho mọi việc khi các phương pháp quy tắc mạnh mẽ vẫn rất có ích.
-
Kiểm thử dữ liệu đại diện đủ đa dạng. Những vấn đề như xoay trang hay nhầm lẫn do bố cục phức tạp rất khó phát hiện nếu chỉ test trên bộ mẫu nhỏ.
-
Prompt engineering cũng là một dạng phát triển phần mềm. Phải kiểm soát, version hóa và tinh chỉnh trợ giúp cho mô hình hoạt động chính xác.
-
Đo lường kết quả theo nhu cầu người dùng cuối. Đôi khi độ chính xác tuyệt đối không phải yếu tố quyết định mà là sự cân bằng chi phí – thời gian – chất lượng.
Kết luận
Chỉ với khoảng 600 dòng Python, hệ thống trích xuất kết hợp kỹ thuật quy tắc và AI đã giúp tổ chức tiết kiệm bốn tuần thời gian kỹ sư, chi phí khoảng vài chục đô API và được triển khai rộng rãi trong vận hành doanh nghiệp.
Thí nghiệm với các model AI mới hơn cũng cho thấy họ không cải thiện đáng kể bài toán này, vì vấn đề nằm ở tiền xử lý dữ liệu và bố cục tài liệu rõ ràng, không phải ở năng lực suy luận mô hình.
Đây là minh chứng cho việc ứng dụng AI hiệu quả không chỉ dựa vào sức mạnh mô hình mà còn phụ thuộc vào cách chúng ta kết hợp chúng một cách khôn ngoan trong hệ thống tổng thể.
Bài viết được tóm lược và biên tập từ kinh nghiệm của Obinna, Kỹ sư AI/Data Senior tại Leeds, Anh Quốc, chuyên về document intelligence và hệ thống AI sản xuất.
Bài viết liên quan

Công nghệ
Các tác nhân AI đã khiến thế giới công nghệ chao đảo: Câu chuyện đằng sau cuộc cách mạng Claude Code và OpenClaw
26 tháng 5, 2026

Công nghệ
Alienware 15 mới: Dell đang làm loãng thương hiệu cao cấp vì khủng hoảng RAM?
14 tháng 5, 2026

Công nghệ
Pinterest áp dụng "vân tay nội dung" để loại bỏ URL trùng lặp trên hàng triệu tên miền
08 tháng 6, 2026