
Từ Data Scientist đến AI Architect: Sự kết thúc của tư duy tập trung vào mô hình
Bài viết khám phá sự chuyển dịch vai trò từ Data Scientist sang AI Architect, nơi giá trị cốt lõi không còn nằm ở việc tinh chỉnh mô hình mà là ở khả năng thiết kế, kết nối và vận hành hệ thống AI toàn diện.

Có một thời điểm (không quá xa xôi) mà làm một Data Scientist đồng nghĩa với việc sống cả ngày trong các notebook Jupyter, mài mòn các siêu tham số (hyperparameters) như thể cả thế giới phụ thuộc vào nó. Và thực tế, trong nhiều trường hợp, sự thành bại của dự án quả thực nằm ở đó.
Bạn còn nhớ những đêm thức trắng chạy grid search không? Hay việc xây dựng các pipeline kỹ thuật đặc trưng (feature engineering) cảm giác như một nghệ thuật hơn là khoa học? Và niềm vui sướng khi vắt kiệt được thêm 0,7% độ chính xác từ mô hình XGBoost?
Quay trở về năm 2019, đó chính là công việc của một Data Scientist! Và điều đó hoàn toàn hợp lý. Nếu bạn muốn một mô hình mạnh, bạn phải tự xây dựng nó hoặc nỗ lực rất nhiều để làm đúng. Giá trị thực sự đến từ việc bạn tinh chỉnh, tối ưu hóa và hiểu dữ liệu tốt đến mức nào.
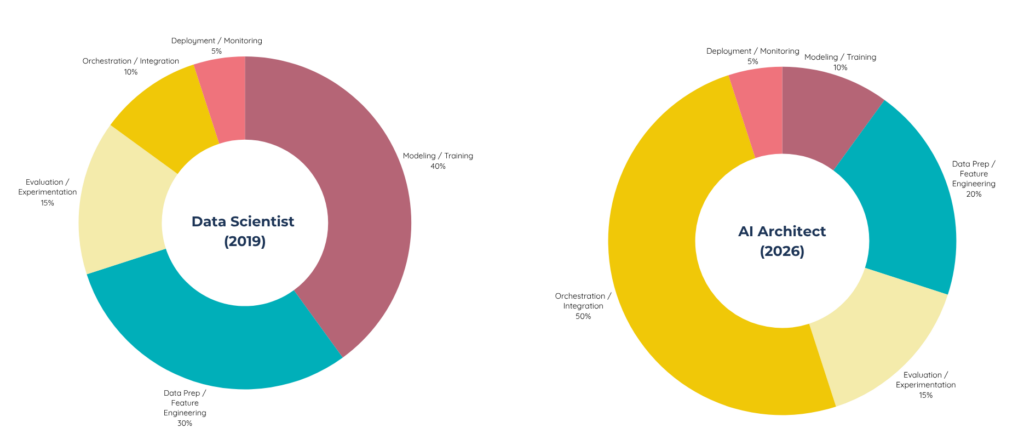 Sự thay đổi trong tư duy AI
Sự thay đổi trong tư duy AI
Nhưng hiện nay, các mô hình "tân tiến nhất" (state-of-the-art) chỉ còn là một cuộc gọi API (API call) xa. Cần một mô hình ngôn ngữ hàng đầu? Xong. Cần embeddings hoặc lý luận đa phương thức (multimodal)? Cũng xong. Những phần khó khăn nhất của việc mô hình hóa hiện nay được xử lý bởi các điểm cuối có khả năng mở rộng (scalable endpoints), vượt xa khả năng của hầu hết các đội ngũ tự xây dựng.
Vậy câu hỏi đặt ra là: Nếu mô hình đã có sẵn rồi, thì công việc thực sự đi đâu về đâu?
Giá trị không còn chỉ nằm ở mô hình nữa. Nó nằm ở cách tất cả các thành phần kết nối, giao tiếp và thích nghi với nhau. Sự thay đổi này đang định hình lại hoàn toàn vai trò của một Data Scientist.
Điều gì đã thay đổi?
1. Bỏ qua phương thức .fit()
Nếu bạn nhìn vào mã nguồn của một dự án AI hiện đại, bạn sẽ nhanh chóng nhận ra rằng không có nhiều hoạt động mô hình hóa thực sự diễn ra.
Bạn có thể thấy một cuộc gọi đến LLM hoặc một mô hình embedding, nhưng hiếm khi đó là thách thức chính. Công việc thực sự nằm ở việc thu nạp dữ liệu (data ingestion), định tuyến (routing), lắp ráp ngữ cảnh (context assembly), lưu vào bộ nhớ đệm (caching), giám sát (monitoring) và xử lý các thử lại (retries).
Nói cách khác, việc sử dụng .fit() giờ đây là một trong những phần ít thú vị nhất của mã nguồn.
2. Thích nghi với các thành phần mới
Ngày nay, thay vì tập trung vào nội bộ của mô hình, chúng ta lắp ráp các hệ thống từ các thành phần có sẵn (ready-made components). Một stack mô hình hóa điển hình hiện nay bao gồm:
- Cơ sở dữ liệu vector (ví dụ: Pinecone, Milvus).
- Kỹ thuật prompt (Prompt engineering).
- Các lớp bộ nhớ (Memory layers).
Ngoài các cuộc gọi hàm/tác nhân (agent calls). Khi nhìn vào bức tranh toàn cảnh, chúng ta thấy rằng đây không phải là mô hình hóa truyền thống. Đây là thiết kế hệ thống (system design). Một điểm quan trọng cần chỉ ra ở đây là không có thành phần nào trong số này thực sự hữu ích khi đứng một mình. Sức mạnh của chúng đến từ cách chúng được phối hợp (orchestrated) lại với nhau.
3. Kết nối mọi thứ lại với nhau
Hiện tại, hầu hết mã nguồn khoa học dữ liệu là về việc kết nối các mảnh ghép. Nó không phải là đại số tuyến tính, tối ưu hóa hay thậm chí là thống kê.
Nó là về việc viết mã để di chuyển dữ liệu giữa các thành phần, định dạng đầu vào, phân tích cú pháp đầu ra, ghi nhật ký các tương tác và quản lý trạng thái trên các hệ thống phân tán.
Nếu bạn đo lường mã của mình, bạn sẽ thấy rằng chỉ 10 đến 20 phần trăm thời gian dành cho việc sử dụng mô hình (cuộc gọi API, suy luận), trong khi 80 đến 90 phần trăm dành cho việc điều phối — xử lý luồng dữ liệu, tích hợp và cơ sở hạ tầng.
Sự chuyển dịch từ Data Scientist sang AI Architect
Thay đổi lớn nhất về tư duy hiện nay là bạn không còn chỉ tối ưu hóa một hàm số nữa. Bây giờ, bạn đang thiết kế một hệ thống toàn diện, suy nghĩ về độ trễ (latency), chi phí, độ tin cậy và cách con người tương tác với nó.
Thay vì hỏi "Làm thế nào để cải thiện hiệu suất mô hình?", chúng ta giờ đây hỏi "Hệ thống toàn diện này hoạt động như thế nào trong các tình huống thực tế?".
Tôi biết bạn đang nghĩ gì — đây là một thách thức hoàn toàn khác! Nó gây khó chịu cho nhiều người, kể cả tôi, khi sự thay đổi này lần đầu tiên xảy ra.
Để theo kịp với stack hiện nay, chúng ta cần nhiều hơn chỉ là thống kê và học máy. Chúng ta phải thoải mái với các API (như FastAPI hoặc Flask) để phục vụ và định tuyến, đóng gói container (như Docker) để triển khai, lập trình không đồng bộ (sử dụng Asyncio) để xử lý nhiều yêu cầu, cơ sở hạ tầng đám mây để mở rộng quy mô và giám sát, và các kiến thức cơ bản về kỹ thuật dữ liệu cho các pipeline và lưu trữ.
Nếu bạn nghĩ điều này nghe giống như kỹ thuật backend (backend engineering), thì bạn đúng rồi.
Sự thay đổi này đã làm mờ ranh giới giữa nhà khoa học dữ liệu và kỹ sư. Những người thành công là những người có thể làm việc thoải mái ở cả hai lĩnh vực.
Cũ và Mới
Câu hỏi chính bây giờ là: Sự thay đổi này trông như thế nào trong mã nguồn?
Dự án Cũ (2019): Phân tích cảm xúc
Nhiều chúng ta đã từng làm việc trên các dự án như thế này. Quy trình đơn giản:
- Thu thập tập dữ liệu đã gán nhãn.
- Thực hiện kỹ thuật đặc trưng (TF-IDF, n-grams).
- Đào tạo bộ phân loại (hồi quy logistic, XGBoost).
- Tinh chỉnh siêu tham số.
- Triển khai mô hình.
Sự thành công ở đây phụ thuộc vào chất lượng tập dữ liệu và mô hình của bạn.
Dự án Hiện đại (2026): Tác nhân Phản hồi Khách hàng Tự chủ
Quy trình giờ đây khác biệt. Để xây dựng một hệ thống ngày nay, bạn cần:
- Thu nạp tin nhắn của khách hàng theo thời gian thực.
- Lưu trữ embeddings trong cơ sở dữ liệu vector.
- Truy xuất ngữ cảnh lịch sử liên quan.
- Xây dựng động các prompt.
- Định tuyến đến LLM với quyền truy cập công cụ (ví dụ: cập nhật CRM, hệ thống vé).
- Duy trì bộ nhớ hội thoại.
- Giám sát đầu ra để đảm bảo chất lượng và an toàn.
Bạn có nhận thấy điều gì bị thiếu không? Gợi ý: Không có vòng lặp đào tạo (training loop).
Ví dụ này có chủ đích đơn giản, nhưng hãy lưu ý những gì chúng ta tập trung vào bây giờ. Việc truy xuất là một phần của hệ thống; mô hình chỉ là một mảnh ghép, và giá trị đến từ cách mọi thứ kết nối và hoạt động cùng nhau.
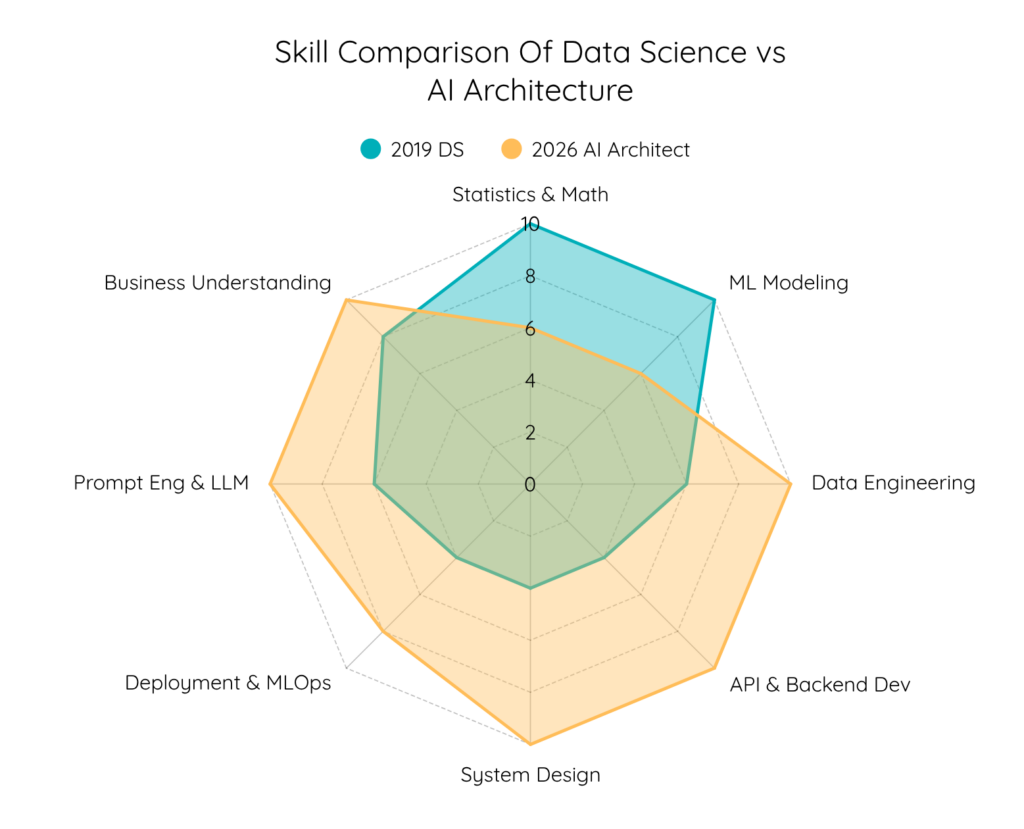 So sánh kiến trúc hệ thống
So sánh kiến trúc hệ thống
Làm thế nào để bắt đầu tư duy như một AI Architect
Bây giờ chúng ta đã biết điều gì đã thay đổi, hãy nói về những gì bạn thực sự nên làm khác biệt. Làm thế nào bạn có thể tiến lên cùng với sự thay đổi này thay vì bị tụt hậu?
Câu trả lời ngắn gọn: Hãy bắt đầu xây dựng các hệ thống, không chỉ là các mô hình.
Câu trả lời dài hơn: Tập trung vào việc xây dựng các kỹ năng này:
1. Xây dựng End-to-End, không chỉ là các thành phần
Thay vì nghĩ "Tôi đã đào tạo một mô hình", hãy hướng tới "Tôi đã xây dựng một hệ thống nhận đầu vào, xử lý nó và trả về giá trị". Bây giờ nó là về bức tranh toàn cảnh, không chỉ là một nhiệm vụ duy nhất.
2. Học đủ Backend để trở nên nguy hiểm
Bạn không cần trở thành một kỹ sư backend toàn thời gian, nhưng bạn nên biết đủ để xây dựng hệ thống của mình. Tập trung vào:
- Khởi chạy một API đơn giản (FastAPI là đủ).
- Xử lý các yêu cầu không đồng bộ.
- Ghi nhật ký và xử lý lỗi.
- Triển khai cơ bản (Docker + một nền tảng đám mây).
3. Làm quen với sự mơ hồ
Các hệ thống AI hiện đại không mang tính xác định (deterministic) như các mô hình truyền thống. Điều này làm cho chúng khó làm việc hơn, bởi vì bây giờ bạn không chỉ gỡ lỗi mã (debug code); mà bạn đang gỡ lỗi hành vi (debug behavior).
Điều đó có nghĩa là lặp lại trên các prompt, thiết kế các cơ chế dự phòng (fallback mechanisms), và đánh giá đầu ra một cách định tính, không chỉ định lượng.
4. Đo lường những gì thực sự quan trọng
Độ chính xác (accuracy) không còn là chỉ số chính duy nhất nữa. Bây giờ, độ trễ, chi phí trên mỗi yêu cầu, sự hài lòng của người dùng và tỷ lệ hoàn thành nhiệm vụ quan trọng hơn.
Một hệ thống có độ chính xác 95% nhưng không thể sử dụng trong sản xuất tệ hơn một hệ thống có độ chính xác 85% nhưng đáng tin cậy.
Lời kết
Trong lĩnh vực của chúng ta, luôn có một cám dỗ để chạy theo bất cứ điều gì cảm giác "kỹ thuật" nhất, mô hình mới nhất, điểm chuẩn lớn nhất, kiến trúc hào nhoáng nhất.
Nhưng phần có giá trị nhất của công việc này luôn luôn, và sẽ luôn luôn là, yếu tố con người! Đó là việc hiểu vấn đề. Biết chúng ta đang cố gắng giải quyết gì quan trọng hơn dữ liệu hay mô hình chúng ta sử dụng.
Đặt ra các câu hỏi như "Nhu cầu ở đây là gì? Người dùng quan tâm đến điều gì? 'Tốt' thực sự có nghĩa là gì trong bối cảnh này?" sẽ tạo ra sự khác biệt lớn trong những gì bạn xây dựng.
Bạn không thể thuê ngoài hay giấu phần đó đằng sau một API. Và bạn chắc chắn không thể tự động hóa nó.
Vì vậy, đừng chỉ nhằm mục đích xây dựng động cơ của một chiếc xe. Hãy aiming để trở thành người hiểu chiếc xe nên đi đâu, và sau đó xây dựng hệ thống để đưa nó đến đó.
Bài viết liên quan
Công nghệ
Open Terminal: Ứng dụng phong cách Bloomberg giúp dân đầu tư cá nhân tiếp cận dữ liệu tài chính chuyên sâu
04 tháng 6, 2026

Phần mềm
Triển khai mảng động trong C: Không cần Struct, không lưu trữ dung lượng
13 tháng 6, 2026

Phần mềm
Giám đốc Rimini Street: "Headless ERP" và mã nguồn mở là chìa khóa thoát khỏi sự kiểm soát của nhà cung cấp
16 tháng 6, 2026