
Từ Dữ liệu Thô đến Các Nhóm Rủi ro: Hướng dẫn Phân loại trong Chấm điểm Tín dụng
Phân loại (categorization) là bước tiền xử lý quan trọng giúp mô hình chấm điểm tín dụng chính xác và ổn định hơn. Bài viết này sẽ đi sâu vào lý do tại sao cần chuyển đổi dữ liệu thô thành các nhóm rủi ro, các phương pháp phổ biến như Weight of Evidence (WoE), và cách thực hiện bằng Python để đảm bảo tính hiệu quả cho mô hình.
Từ Dữ liệu Thô đến Các Nhóm Rủi ro: Hướng dẫn Phân loại trong Chấm điểm Tín dụng
Điều gì sẽ xảy ra nếu mô hình chấm điểm tín dụng của bạn thất bại không phải vì thuật toán quá yếu, mà vì các biến số chưa được chuẩn bị theo cách mà mô hình có thể hiểu đúng?
Trong mô hình hóa rủi ro tín dụng, chúng ta thường tập trung quá nhiều vào việc lựa chọn mô hình, các chỉ số hiệu suất, lựa chọn đặc trưng (feature selection) hoặc xác thực. Tuy nhiên, trước khi ước tính bất kỳ hệ số nào, một câu hỏi khác xứng đáng được chú ý: Mỗi biến số nên được đưa vào mô hình như thế nào?
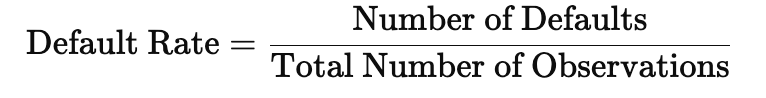 Dữ liệu và phân tích
Dữ liệu và phân tích
Một biến thô (raw variable) không phải lúc nào cũng là đại diện tốt nhất cho rủi ro. Một biến liên tục có thể có mối quan hệ phi tuyến tính với khả năng vỡ nợ. Một biến phân loại có thể chứa quá nhiều chế độ (modalities). Một số biến có thể bao gồm các giá trị ngoại lai (outliers), giá trị thiếu, phân phối không ổn định hoặc các danh mục có rất ít quan sát. Nếu những vấn đề này bị bỏ qua, mô hình có thể trở nên không ổn định, khó giải thích và kém tin cậy hơn khi đưa vào vận hành thực tế.
Đây chính là lúc phân loại (categorization) trở nên quan trọng.
Tại sao phân loại lại quan trọng trong chấm điểm tín dụng?
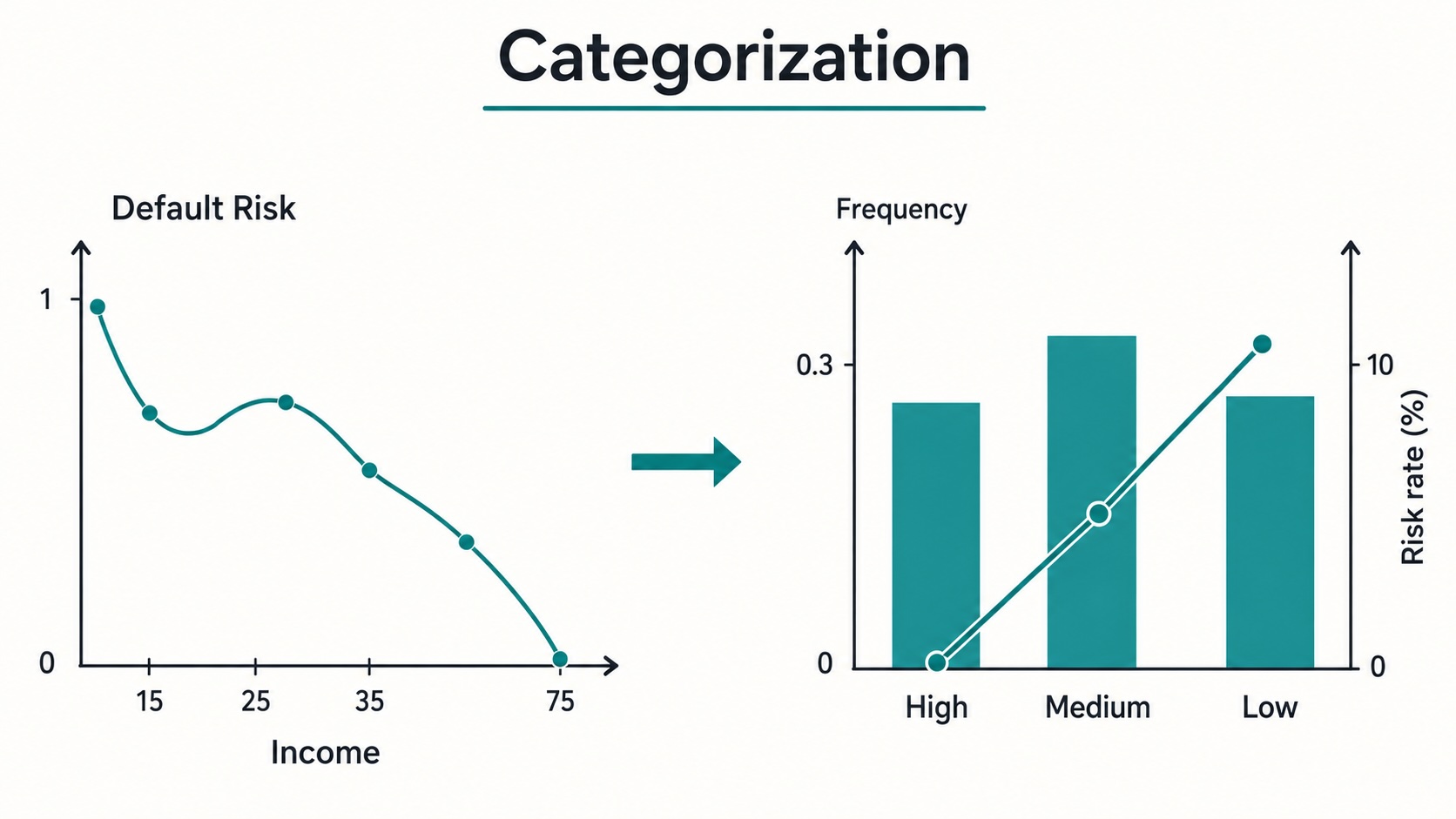
Phân loại, còn gọi là coarse classing, grouping, classing hoặc binning, bao gồm việc chuyển đổi các giá trị biến thô thành một số nhỏ hơn các nhóm có ý nghĩa. Trong chấm điểm tín dụng, các nhóm này không chỉ được tạo ra cho sự tiện lợi; chúng được tạo ra để làm rõ mối quan hệ giữa biến và rủi ro vỡ nợ, giúp mô hình ổn định và dễ sử dụng hơn.
Đặc biệt, khi mô hình cuối cùng là hồi quy logistic (logistic regression) — phương pháp vẫn được sử dụng rộng rãi nhờ tính minh bạch và dễ dàng chuyển đổi thành bảng điểm (scorecard) — thì bước này càng trở nên thiết yếu.
Dưới đây là những lý do chính để thực hiện phân loại:
1. Giảm chiều dữ liệu (Dimensionality Reduction)
Giả sử chúng ta có một biến industry_sector với 50 giá trị khác nhau. Nếu đưa trực tiếp vào hồi quy logistic, ta cần tạo 49 biến giả (dummy variables). Điều này dẫn đến việc phải ước tính quá nhiều tham số, gây ra hiện tượng overfitting và hệ số không ổn định. Bằng cách nhóm các danh mục có hành vi rủi ro tương tự lại, ta giảm số lượng tham số cần ước tính, giúp mô hình gọn nhẹ và ổn định hơn.
2. Bắt giữ các mẫu rủi ro phi tuyến tính
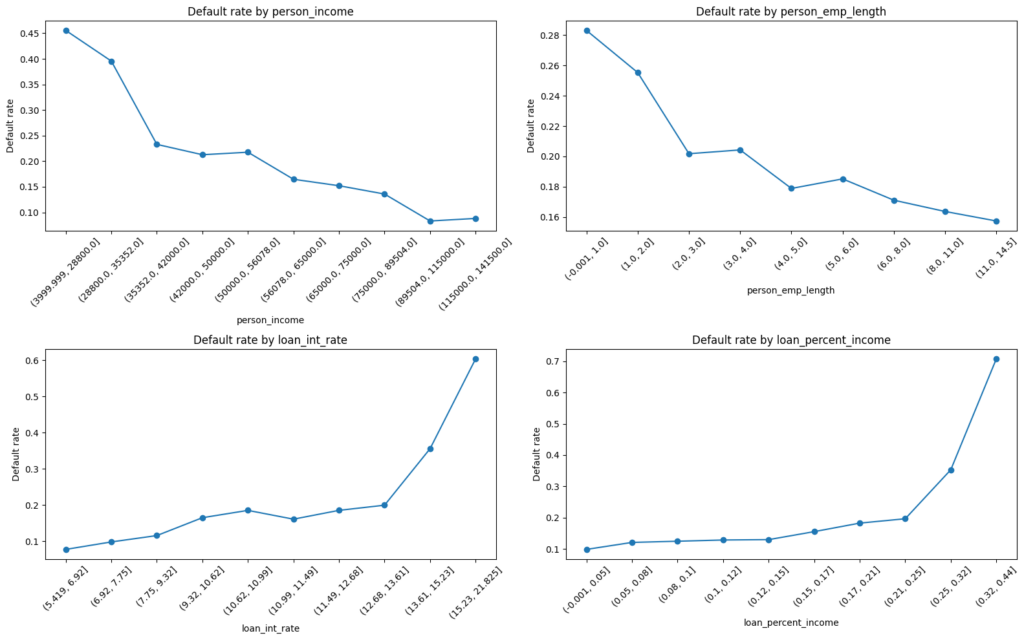
Đối với các biến liên tục như thu nhập (person_income), mối quan hệ với rủi ro vỡ nợ có thể không phải lúc nào cũng là đường thẳng. Ví dụ, rủi ro có thể giảm khi thu nhập tăng từ thấp đến trung bình, nhưng sau đó tăng lại ở mức thu nhập rất cao do các hành vi tài chính phức tạp.
Hồi quy logistic giả định mối quan hệ tuyến tính giữa biến và log-odds của vỡ nợ. Bằng cách phân loại biến liên tục thành các nhóm rủi ro, ta có thể đưa một phần tính phi tuyến tính vào mô hình tuyến tính.
3. Xử lý giá trị ngoại lai và giá trị thiếu
Các giá trị cực đoan (ví dụ: thu nhập quá cao) có thể ảnh hưởng mạnh đến ước tính hệ số. Khi phân loại, tất cả các giá trị trên một ngưỡng nhất định sẽ được gán vào cùng một nhóm, giảm thiểu ảnh hưởng của các quan sát cực đoan. Tương tự, việc tạo một nhóm riêng cho các giá trị thiếu (missing values) cho phép mô hình học được hành vi cụ thể của nhóm khách hàng này, thay vì chỉ đơn giản là xóa họ đi.
4. Cải thiện tính ổn định và khả năng giải thích
Mô hình chấm điểm tín dụng cần phải giải thích được cho các chuyên gia rủi ro và cơ quan quản lý. Nói rằng "Khách hàng có lãi suất trên 15% có rủi ro vỡ nợ cao hơn đáng kể so với nhóm dưới 10%" trực quan hơn nhiều là nói về sự thay đổi log-odds. Hơn nữa, nếu thu nhập của khách hàng thay đổi nhẹ (ví dụ từ 2990 sang 3010) nhưng vẫn nằm trong cùng một nhóm thu nhập, giá trị phân loại của họ không đổi, giúp mô hình ổn định hơn theo thời gian.
 Phân tích dữ liệu
Phân tích dữ liệu
Phân tích đơn điệu trước khi phân nhóm
Trước khi phân loại một biến liên tục, chúng ta cần hiểu mối quan hệ của nó với tỷ lệ vỡ nợ. Một biến được gọi là đơn điệu (monotonic) nếu tỷ lệ vỡ nợ di chuyển theo một hướng khi biến tăng lên.
Ví dụ:
- Thu nhập tăng -> Rủi ro giảm (Đơn điệu giảm).
- Lãi suất vay tăng -> Rủi ro tăng (Đơn điệu tăng).
Để kiểm tra điều này, chúng ta thường sử dụng Equal-Frequency Binning (phân nhóm tần suất bằng nhau) để chia biến thành các nhóm (ví dụ: decile) có số lượng quan sát xấp xỉ bằng nhau, sau đó vẽ biểu đồ tỷ lệ vỡ nợ theo nhóm. Phương pháp này giúp mỗi nhóm có đủ dữ liệu để tính toán tỷ lệ vỡ nợ đáng tin cậy hơn so với phân nhóm theo khoảng cách (equal-interval).
Các phương pháp phân loại chính
Có hai nhóm phương pháp chính: không giám sát (unsupervised) và có giám sát (supervised).
- Phương pháp không giám sát: Equal-interval binning, Equal-frequency binning. Các phương pháp này không sử dụng biến mục tiêu (target variable).
- Phương pháp có giám sát: Sử dụng biến vỡ nợ để tạo các nhóm dựa trên rủi ro. Trong chấm điểm tín dụng, các phương pháp này thường được ưa chuộng hơn.
Nhóm dựa trên Chi-square (Chi-Square-Based Grouping)
Phương pháp này bắt đầu với nhiều nhóm nhỏ, sau đó so sánh các nhóm liền kề. Nếu hai nhóm liền kề có hành vi vỡ nợ tương tự (dựa trên kiểm định Chi-square), chúng sẽ được gộp lại. Quá trình này lặp lại cho đến khi còn lại các lớp ổn định ít hơn.
Nhóm dựa trên Weight of Evidence (WoE)
Đây là phương pháp phổ biến nhất trong chấm điểm tín dụng. WoE đo lường phân bố tương đối của các sự kiện (vỡ nợ) và không sự kiện (không vỡ nợ) trong mỗi danh mục.
Công thức WoE:
WoE = ln(% Events / % Non-Events)
- WoE dương: Tỷ lệ vỡ nợ cao hơn trung bình.
- WoE âm: Tỷ lệ vỡ nợ thấp hơn trung bình.
- WoE gần 0: Rủi ro tương đương mức trung bình của tổng thể.
Phương pháp WoE-based grouping bao gồm việc gộp các nhóm liền kề có giá trị WoE tương tự nhau. Mục tiêu là tạo ra các nhóm ổn định với thứ tự rủi ro rõ ràng. Điều này đặc biệt hữu ích cho hồi quy logistic vì các biến đã chuyển đổi WoE được căn chỉnh tốt với cấu trúc log-odds của mô hình.
Triển khai với Python và kiểm tra tính ổn định
Để triển khai, chúng ta thường sử dụng các thư viện như pandas và matplotlib. Quy trình bao gồm:
- Tính toán WoE: Chia biến liên tục thành các nhóm (bins) và tính toán WoE cho từng nhóm.
- Phân tích: Xem xét bảng tóm tắt số lượng quan sát và tỷ lệ vỡ nợ cho từng nhóm.
- Kiểm tra ổn định: Phân tích sự tiến hóa của tỷ lệ vỡ nợ theo từng nhóm theo thời gian.
Một phân loại tốt phải thỏa mãn ba điều kiện:
- Có ý nghĩa về mặt thống kê.
- Phù hợp với trực giác kinh doanh về rủi ro tín dụng.
- Ổn định theo thời gian (trên tập train, test và out-of-time).
 Lập trình và mô hình hóa
Lập trình và mô hình hóa
Ví dụ, khi áp dụng cho biến person_income (thu nhập cá nhân), chúng ta có thể chia thành 3 nhóm. Kết quả thường cho thấy những người có thu nhập thấp có WoE dương (rủi ro cao), trong khi những người có thu nhập cao có WoE âm (rủi ro thấp). Điều này hoàn toàn phù hợp với trực giác: thu nhập cao hơn thường đi kèm với khả năng trả nợ tốt hơn.
Tuy nhiên, chỉ nhìn vào kết quả trên tập huấn luyện là chưa đủ. Chúng ta cần vẽ biểu đồ kết hợp giữa biểu đồ cột (tần suất dân số) và biểu đồ đường (tỷ lệ rủi ro) để đảm bảo mỗi nhóm có đủ số lượng quan sát và mẫu rủi ro nhất quán.
Kết luận
Phân loại là bước then chốt trong phát triển mô hình chấm điểm tín dụng. Nó áp dụng cho cả biến phân loại và biến liên tục, giúp xử lý các vấn đề về phi tuyến tính, giá trị ngoại lai, giá trị thiếu và cải thiện tính ổn định của mô hình.
Trong thực tế, phân loại không nên được coi là một bước tiền xử lý máy móc. Một phân loại tốt phải thỏa mãn các yêu cầu về thống kê, kinh doanh và sự ổn định. Đặc biệt khi sử dụng hồi quy logistic, việc phân loại dựa trên WoE giúp chuyển đổi các biến thô thành các lớp rủi ro ổn định, sẵn sàng cho việc xây dựng một bảng điểm tin cậy.
Mô hình chấm điểm tín dụng chỉ tốt bằng dữ liệu đầu vào của nó. Nếu các biến số bị ồn, không ổn định hoặc phân loại kém, ngay cả một thuật toán tốt cũng có thể tạo ra một mô hình yếu. Nhưng khi các biến số được phân loại cẩn thận, mô hình sẽ trở nên mạnh mẽ, dễ giải thích và dễ giám sát hơn trong môi trường sản xuất thực tế.