
Xây dựng hạ tầng tối ưu cho tác nhân LLM cục bộ: Bài học từ thực tế
Bài viết chia sẻ kinh nghiệm xây dựng một tác nhân khoa học nhanh chóng và đáng tin cậy sử dụng các mô hình mã nguồn mở cục bộ, vLLM và hạ tầng ngữ cảnh dài. Tác giả đi sâu vào các tối ưu hóa phần cứng và phần mềm để giải quyết vấn đề tốc độ và quản lý bộ nhớ.
Chạy một mô hình ngôn ngữ (LLM) cục bộ nghe có vẻ khá đơn giản: tải trọng số (weights), khởi động máy chủ và gửi yêu cầu. Cách tiếp cận này hoạt động tốt với các chatbot thông thường, nhưng chưa chắc đã hiệu quả đối với một tác nhân (agent).
Trong trường hợp của tôi, tôi đang xây dựng một tác nhân để tự động hóa phân tích RNA-seq tế bào đơn lẻ. Ý tưởng là khi có dữ liệu thô, tác nhân sẽ tự chạy toàn bộ quy trình, quyết định công cụ nào sẽ gọi, đọc kết quả và thực hiện phân tích từng bước một.
Bạn có thể hỏi: Tại sao không sử dụng Claude Code với các kỹ năng phân tích có sẵn? Câu trả lời ngắn gọn là đối với các quy trình khoa học, điều đó là chưa đủ. Các kỹ năng đó về bản chất là các câu lệnh (prompt) và có thể bị ghi đè hoặc bỏ qua. Quan trọng hơn, công việc khoa học yêu cầu tính có thể tái tạo và khả năng truy xuất nguồn gốc: biết chính xác tham số nào được sử dụng, tế bào nào được lọc, độ phân cụm nào tạo ra kết quả nào, v.v. Hồ sơ đó cần được cấu trúc và lưu trữ bền vững, không phải tái tạo lại từ cuộc hội thoại.
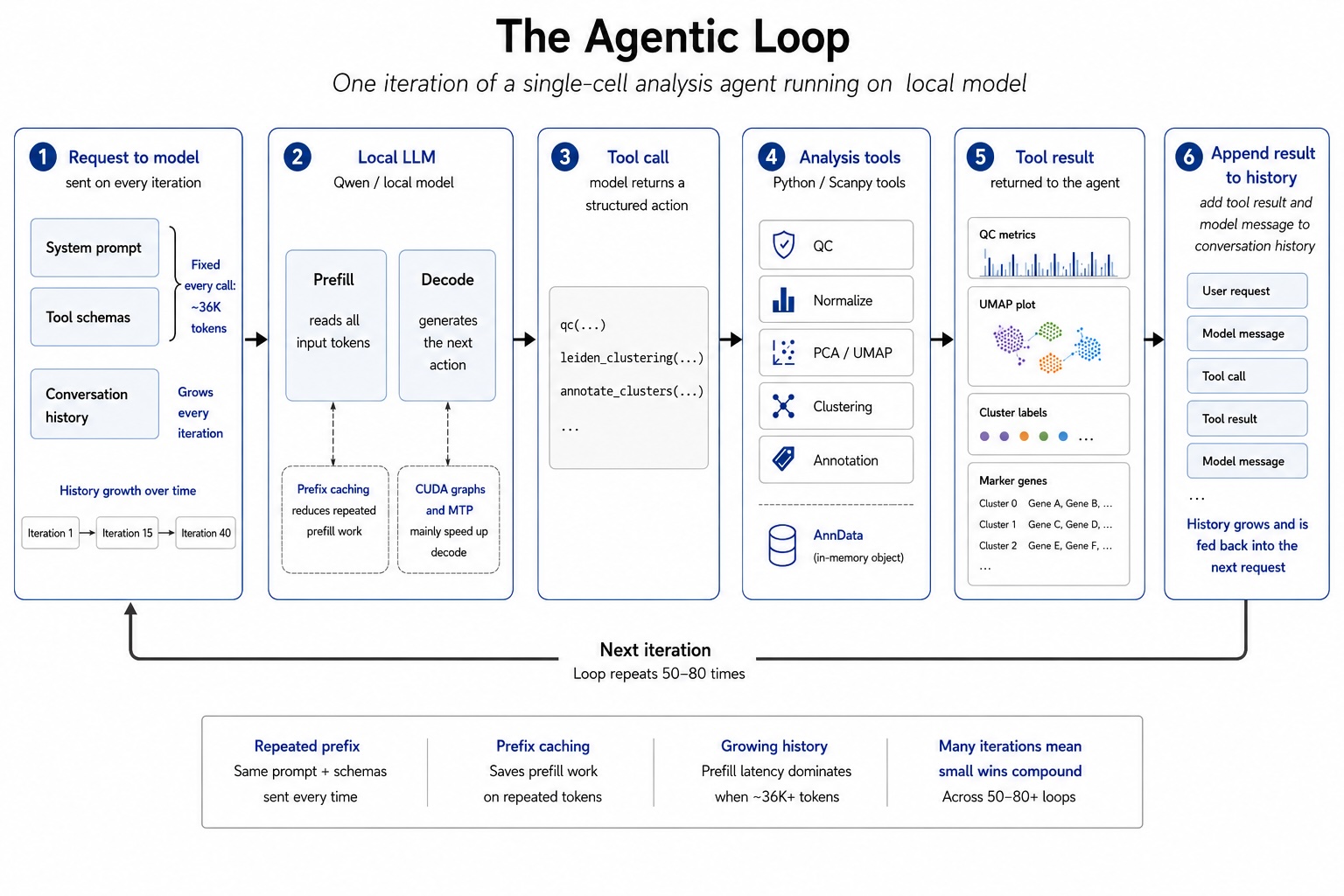
 Vòng lặp của tác nhân
Vòng lặp của tác nhân
Tác nhân mà chúng tôi xây dựng chạy trên phần cứng HPC (High Performance Computing) sử dụng các mô hình mã nguồn mở gần đây. Các bản phát hành mới như Qwen3.6–27B và Gemma 4–31B thực sự hữu ích cho các khối lượng công việc dựa trên công cụ có cấu trúc. Khi bạn tự lưu trữ mô hình, các vấn đề về hiệu suất sẽ trở thành vấn đề của bạn.
Lần đầu tiên tôi chạy mô hình, nó hoạt động trong một phạm vi hẹp. Mô hình gọi công cụ, công cụ chạy và phân tích tiến triển. Nhưng nó chưa thực sự sử dụng được. Một phân tích đơn giản có thể yêu cầu 50–80 lần gọi công cụ trong một vòng lặp. Mỗi lần gọi mang theo một "hành lý" cố định: hệ thống câu lệnh, lược đồ công cụ và lịch sử hội thoại đang tăng lên. Đối với tác nhân này, chỉ riêng hệ thống câu lệnh và lược đồ công cụ đã chiếm khoảng 36k token. Mỗi lần lặp mất từ 10 đến 15 giây và một phiên dài sẽ最终 bị lỗi tràn ngữ cảnh.
Bài viết này sẽ tập trung vào việc giải quyết hai vấn đề chính: làm cho suy luận (inference) nhanh hơn thông qua tối ưu hóa vLLM và giữ cho các phiên dài hoạt động thông qua quản lý ngữ cảnh tốt hơn.
Phần 1: Tăng tốc độ suy luận
Trước khi đi sâu vào từng tối ưu hóa, hãy hiểu điều gì thực sự xảy ra trong mỗi lần lặp của vòng lặp tác nhân. Đoạn mã cố định (tiền tố) bao gồm hệ thống câu lệnh và lược đồ công cụ, khoảng 36k token và được gửi trong mỗi lần gọi. Lịch sử hội thoại tăng lên sau mỗi lần lặp. Cả hai yếu tố này đều ảnh hưởng đến hiệu suất.
1.1 CUDA Graphs: Giảm hàng trăm lệnh xuống còn một
Để hiểu điều này, cần biết điều gì xảy ra bên trong GPU khi tạo ra một token. Quá trình giải mã bao gồm việc thực hiện một chuỗi các kernel GPU: attention, feed-forward, normalization, v.v. Việc khởi chạy mỗi kernel đều có chi phí phối hợp nhỏ trên CPU. Với mô hình 27 tỷ tham số, điều này có nghĩa là hàng trăm lệnh gửi đi cho mỗi token.
CUDA Graphs loại bỏ chi phí này. vLLM chạy một lượt khởi động để ghi lại tất cả các lệnh gửi cho bước giải mã thành một đối tượng có thể phát lại duy nhất. Sau đó, việc tạo mỗi token chỉ là một lệnh duy nhất thay vì hàng trăm lệnh. Kết quả là độ trễ giảm khoảng 20–25% chỉ từ thay đổi này.
1.2 Tối ưu hóa bộ nhớ
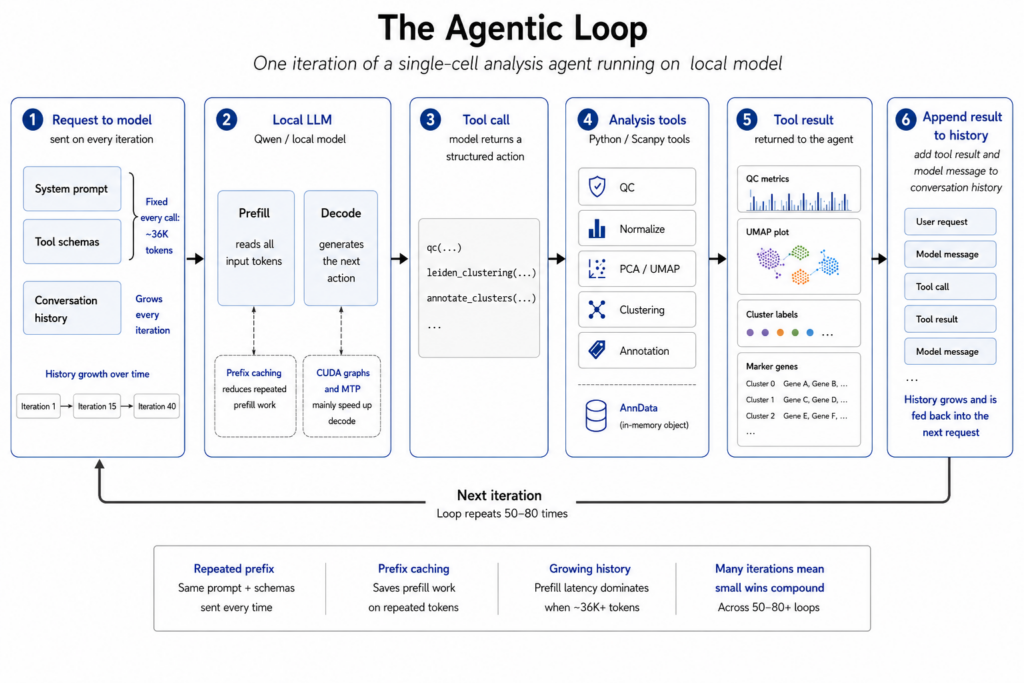
Mỗi trọng số trong mạng nơ-ron là một số, và định dạng lưu trữ ảnh hưởng đến bộ nhớ và tốc độ. Định dạng tiêu chuẩn là BF16 (16-bit). Đối với Qwen3.6–27B, điều này chiếm khoảng 56GB chỉ để tải mô hình.
FP8 lưu mỗi trọng số trong một byte thay vì hai byte. Cùng một mô hình giờ chỉ chiếm khoảng 31GB. Bộ nhớ tiết kiệm được có thể dùng cho KV cache (bộ nhớ đệm ngữ cảnh). Tuy nhiên, việc sử dụng FP8 cho tính toán yêu cầu các đơn vị FP8 chuyên dụng, chỉ có trên thế hệ Hopper (H100). A100 không hỗ trợ điều này.
 So sánh A100 và H100
So sánh A100 và H100
Một điểm thú vị là KV cache trên mỗi token. Gemma 4–31B sử dụng khoảng 1,1MB KV cache cho mỗi token, trong khi Qwen3.6–27B chỉ khoảng 256KB. Điều này có nghĩa là với cùng một lượng GPU, Qwen có thể xử lý ngữ cảnh dài hơn nhiều.
Ngoài ra, việc chạy mô hình trên nhiều GPU với Tensor Parallelism chia nhỏ ma trận trọng số, giải phóng thêm không gian cho KV cache trên mỗi GPU.
 Tensor Parallelism
Tensor Parallelism
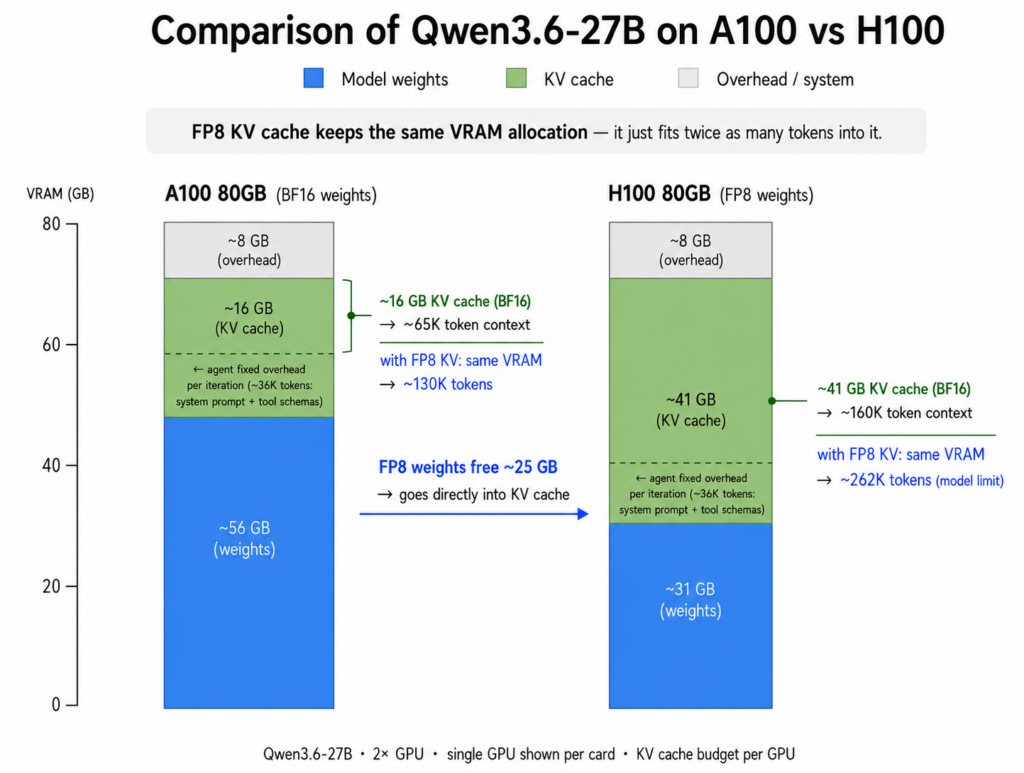
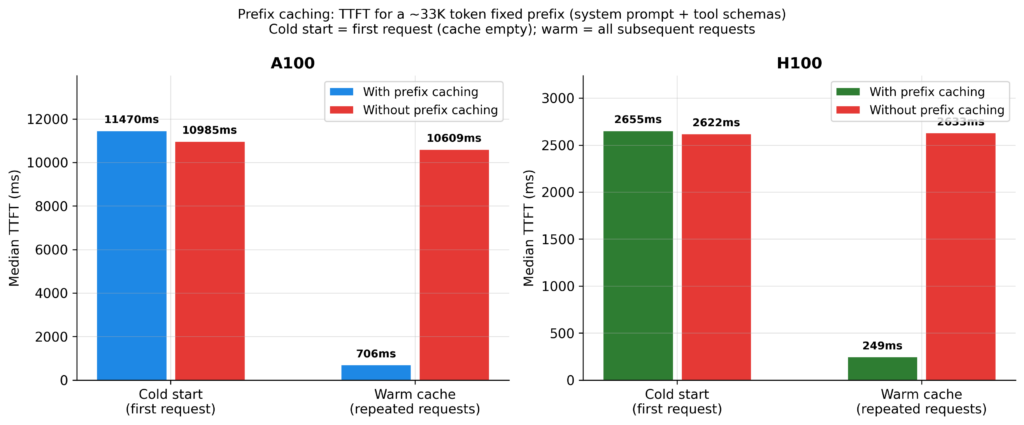
1.3 Prefix Caching
Nhớ tiền tố cố định 36K token đã đề cập? Prefix caching giải quyết vấn đề này bằng cách lưu trữ các vector khóa và giá trị cho bất kỳ chuỗi token nào mà mô hình đã xử lý. Nếu yêu cầu tiếp theo bắt đầu bằng cùng một tiền tố, các vector đó được lấy trực tiếp từ bộ nhớ đệm thay vì tính toán lại.
Đối với vòng lặp tác nhân, điều này đặc biệt có giá trị vì phần cố định lớn và phần mới thêm vào mỗi lần lặp tương đối nhỏ. Khi phiên tiến triển, tỷ lệ hit cache thực sự được cải thiện.
 Prefix Caching
Prefix Caching
Trong các thử nghiệm, trên A100, thời gian đến token đầu tiên (TTFT) từ trạng thái lạnh là 11.470ms, nhưng giảm xuống còn 706ms khi có cache ấm. Trên H100, con số này giảm từ 2.655ms xuống còn 249ms.
1.4 Speculative Decoding (Giải mã suy đoán)
Giải mã vốn có tính tuần tự. Speculative decoding giải quyết vấn đề này bằng cách sử dụng một mô hình nháp nhỏ chạy trước mô hình chính. Mô hình nháp đề xuất k token tiếp theo nhanh chóng. Mô hình chính sau đó xác minh tất cả k token được đề xuất trong một lần chuyển tiếp song song.
Biến số chính là tỷ lệ chấp nhận (acceptance rate). Nếu các đề xuất sai, hiệu suất sẽ giảm. Chúng tôi đã sử dụng Multi-Token Prediction head (MTP) tích hợp sẵn trong Qwen3.6–27B. Với tỷ lệ chấp nhận trung bình ~89%, MTP đã tăng tốc độ giải mã đáng kể.
Phần 2: Giữ cho các phiên dài hoạt động
Khi sử dụng mô hình đám mây, quản lý ngữ cảnh dễ bị bỏ qua. Nhưng với mô hình cục bộ, cửa sổ ngữ cảnh trở thành ngân sách phần cứng. Một phân tích tế bào đơn lẻ có thể chạy 50 đến 80 lần lặp, làm đầy ngữ cảnh và gây lỗi.
Quản lý ngữ cảnh nghe có vẻ đơn giản: theo dõi độ đầy và cắt bớt khi cần. Tuy nhiên, các triển khai ngây thơ thường thất bại.
Vấn đề với việc tóm tắt (Compaction)
Anthropic mô tả các chiến lược như nén, ghi chú có cấu trúc. Đối với trợ lý chung, nén hoạt động tốt. Nhưng đối với quy trình khoa học, việc tóm tắt văn bản sẽ làm mất chính xác thông tin cần thiết. "Phân tích đã cụm dữ liệu và chạy kiểm soát chất lượng" là một bản tóm tắt hợp lệ, nhưng nó loại bỏ các ngưỡng QC, độ phân cụm, số lượng tế bào giữ lại, v.v. Một tác nhân khoa học cần hồ sơ chính xác, không chỉ là ý chính.
Giải pháp: Trạng thái thế giới (World State)
Cách tiếp cận tốt hơn là ngừng coi lịch sử hội thoại là hồ sơ những gì đã xảy ra. Đối với quy trình khoa học, chúng ta đã có một hồ sơ đáng tin cậy hơn: nhật ký có cấu trúc của mọi bước tác nhân thực hiện, với các tham số và kết quả chính xác. Chúng tôi gọi đây là World State.
World State là một đối tượng Python theo dõi phân tích khi nó tiến triển. Mỗi lần gọi công cụ hoàn thành sẽ ghi một mục có cấu trúc vào đó. Đối tượng này được tuần tự hóa vào hệ thống câu lệnh trong mỗi lần lặp. Nó chiếm dưới 1.000 token, chứa các tham số chính xác và sống trong hệ thống câu lệnh không bao giờ bị cắt bớt.
Khi các kết quả công cụ cũ bị xóa khỏi lịch sử tin nhắn, hồ sơ phân tích vẫn còn nguyên vẹn. Điều này thay đổi cách bạn nghĩ về việc cắt bớt: bạn có thể cắt bớt lịch sử một cách tích cực vì hồ sơ nằm ở nơi khác.
 Quản lý ngữ cảnh và World State
Quản lý ngữ cảnh và World State
Các sửa đổi khác
Chúng tôi cũng thực hiện các sửa đổi để tính toán ngân sách ngữ cảnh chính xác hơn:
- Kế toán chi phí cố định: Trừ hệ thống câu lệnh, lược đồ công cụ và ngân sách hoàn thành trước khi tính toán lịch sử khả dụng.
- Đếm token tự hiệu chỉnh: Sử dụng phản hồi của API để điều chỉnh ước tính của chúng tôi sau mỗi lần gọi.
- Cắt bớt chiến lược: Khi gần đạt ngân sách, tác nhân loại bỏ các kết quả công cụ lớn nhất trước thay vì cắt đồng đều.
Kết luận
Chạy LLM cục bộ cho khối lượng công việc thực tế phơi bày các vấn đề dễ bị bỏ qua khi sử dụng API đám mây. Các tối ưu hóa trong Phần 1 (CUDA Graphs, Prefix Caching, FP8, MTP) kết hợp để đưa tác nhân từ 10–15 giây mỗi lần lặp xuống còn khoảng 1–3 giây.
Các thay đổi quản lý ngữ cảnh trong Phần 2 giải quyết vấn đề khác: tính chính xác. Một tác nhân khoa học chạy lâu cần nhớ chính xác những gì nó đã làm, không chỉ tiếp tục cuộc trò chuyện. Bài học lớn nhất ở đây là một tác nhân hữu ích không chỉ là một LLM với công cụ. Nó là một vòng lặp với hạ tầng bao quanh nó. Mô hình quyết định việc cần làm tiếp theo, nhưng hệ thống xung quanh quyết định xem vòng lặp đó có đủ nhanh, đủ ổn định và đủ đáng tin cậy để hoàn thành công việc hay không.
Bài viết liên quan

Công nghệ
Sự trở lại của Xbox: Chiến lược mới, thay đổi nhân sự và tương lai Project Helix
07 tháng 5, 2026

Công nghệ
Samsung Galaxy Book6 Ultra: Bản sao MacBook Pro đắt đỏ nhưng đầy khiếm khuyết
07 tháng 5, 2026

Phần cứng
Schlage ra mắt khóa thông minh Sense Pro hỗ trợ mở khóa không chạm UWB và Matter over Thread
16 tháng 6, 2026