
Xây dựng Mô hình Xếp hạng Tín dụng Bền vững bằng Python: Hướng dẫn Tối ưu hóa Phân tích Tương quan Biến số
Bài viết này giới thiệu cách sử dụng Python để phân tích mối quan hệ giữa các biến số trong mô hình xếp hạng tín dụng, tập trung vào việc đánh giá khả năng phân biệt rủi ro (default) và giảm thiểu sự trùng lặp thông tin. Tác giả sẽ hướng dẫn các kỹ thuật thống kê như Spearman Correlation, Cramér's V và Kruskal-Wallis test, cùng với các phương pháp trực quan hóa dữ liệu để xây dựng các mô hình chính xác và bền vững hơn.
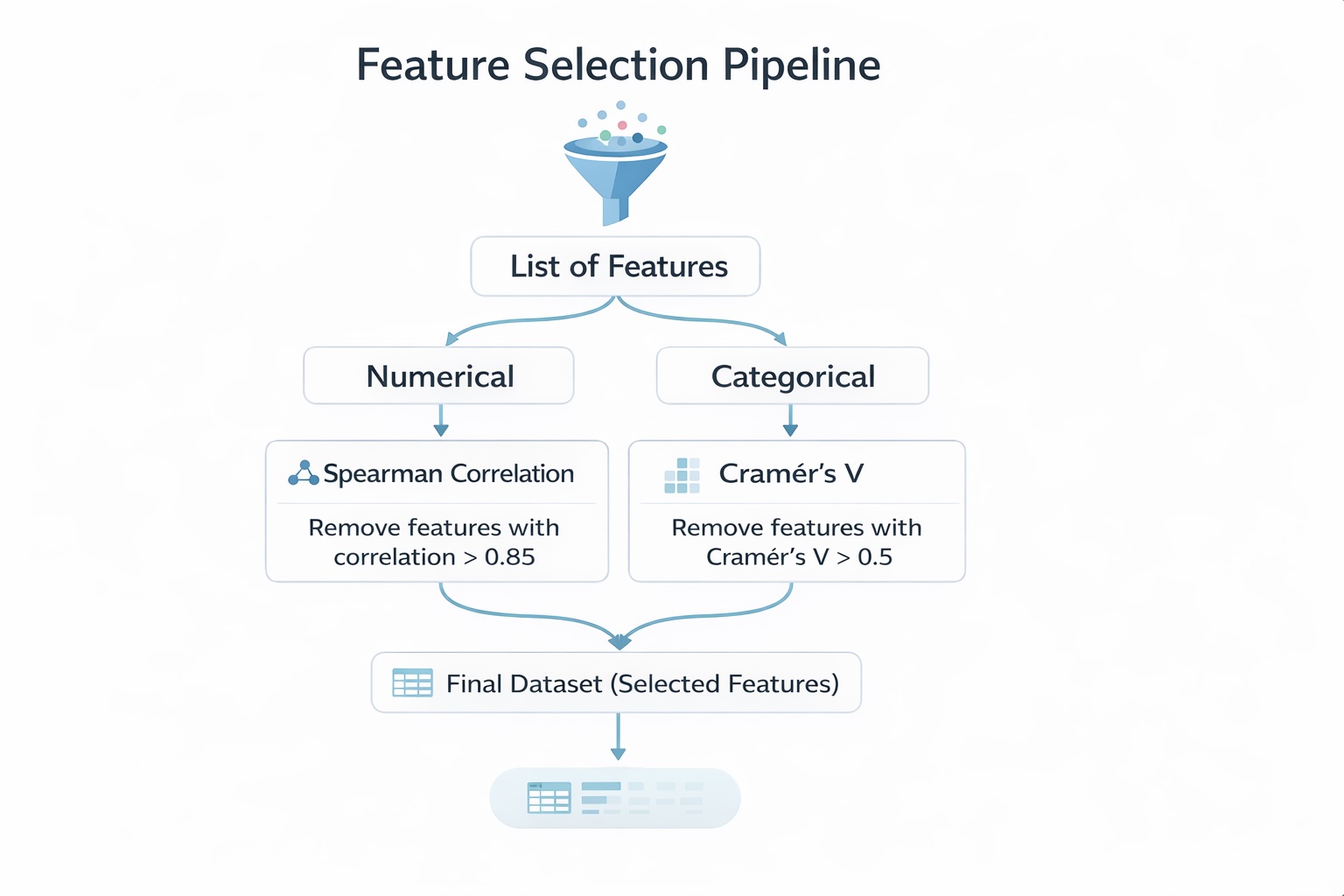
Xây dựng một mô hình xếp hạng tín dụng (Credit Scoring) mạnh mẽ đòi hỏi không chỉ kiến thức về Machine Learning mà còn sự hiểu sâu sắc về dữ liệu đầu vào. Trong bối cảnh tài chính hiện đại, việc lựa chọn đúng các đặc trưng (features) đóng vai trò then chốt trong việc dự đoán khả năng vỡ nợ (default) và đảm bảo độ chính xác của hệ thống.
Trong bài viết này, chúng ta sẽ đi sâu vào việc phân tích mối quan hệ giữa các biến số thông qua Python, nhằm giải quyết hai mục tiêu cốt lõi: đánh giá khả năng phân biệt của các biến và giảm chiều sâu dữ liệu (dimensionality reduction) để loại bỏ sự trùng lặp thông tin.
Tại sao phân tích mối quan hệ giữa biến số lại quan trọng?
Khi xây dựng mô hình, việc chỉ nhìn vào độ chính xác của mô hình (accuracy) là chưa đủ. Chúng ta cần hiểu rõ bản chất dữ liệu. Phân tích mối quan hệ giữa các biến số giúp xác định những biến nào giải thích tốt nhất hiện tượng cần nghiên cứu, ví dụ như khả năng trả nợ.
Tuy nhiên, tương quan không đồng nghĩa với nguyên nhân - kết quả. Mọi phát hiện cần được kiểm chứng bằng nghiên cứu học thuật, kinh nghiệm chuyên môn và quan trọng nhất là trực quan hóa dữ liệu.
Mục tiêu thứ hai là giảm thiểu sự trùng lặp (multicollinearity). Nếu hai biến số có mối quan hệ quá chặt chẽ (ví dụ: thu nhập và số năm làm việc), chúng mang lại cùng một thông tin. Việc giữ lại cả hai sẽ làm giảm hiệu suất mô hình. Phân tích này giúp loại bỏ các biến thừa, giúp mô hình hoạt động mượt mà và dễ giải thích hơn.
Phân tích Trực quan hóa Dữ liệu: Bước đầu tiên
Trước khi chạy các kiểm định thống kê phức tạp, hãy luôn dành thời gian trực quan hóa. Hình ảnh thường tiết lộ cấu trúc ngầm của dữ liệu tốt hơn bất kỳ con số thống kê đơn lẻ nào.
 Phân tích trực quan hóa dữ liệu tín dụng
Phân tích trực quan hóa dữ liệu tín dụng
Trong các bài toán xếp hạng tín dụng, mục tiêu là chọn ra các biến số có khả năng phân biệt tốt giữa hai nhóm: người không vỡ nợ (def=0) và người vỡ nợ (def=1).
1. Biến Liên tục vs. Biến Nhị Phân (Mục tiêu)
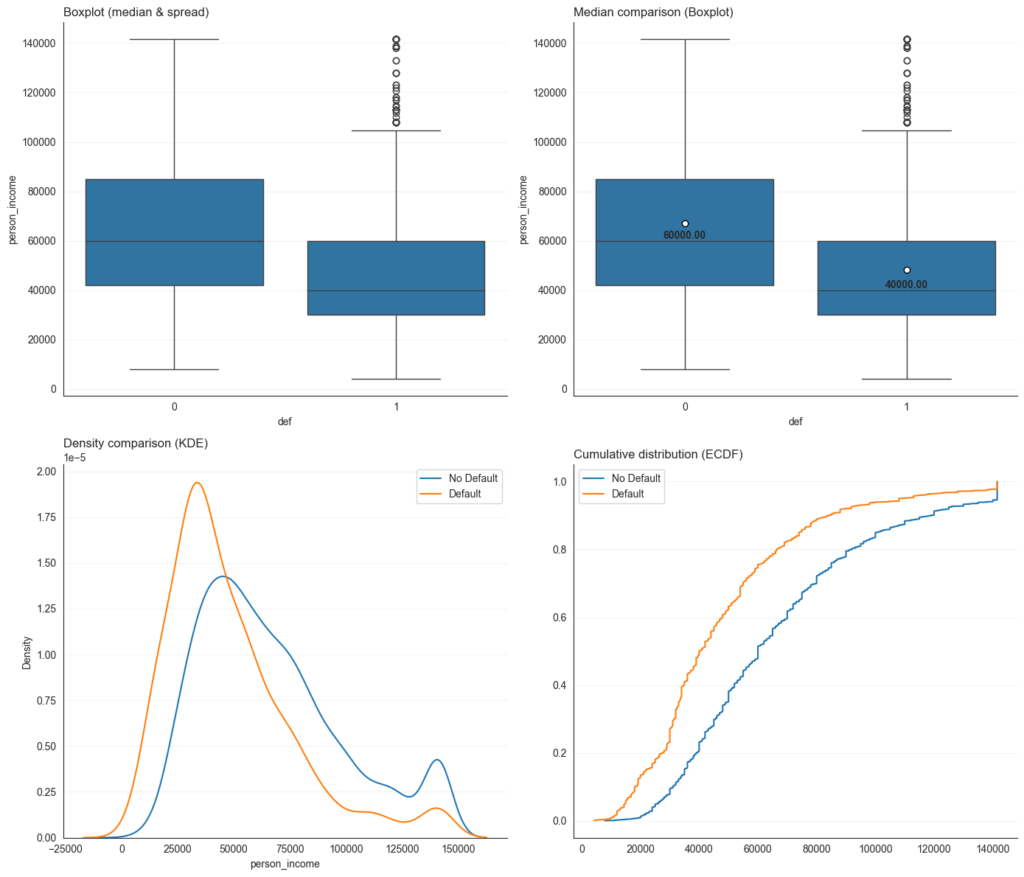
Nếu biến số là số thực (ví dụ: thu nhập), chúng ta so sánh phân phối của nó giữa hai nhóm này. Các công cụ thường dùng bao gồm:
- Boxplot: So sánh trung vị và độ phân tán.
- Biểu đồ mật độ (KDE): So sánh hình dạng phân phối.
- Hàm phân phối tích lũy (ECDF): Xem xét xu hướng chung của dữ liệu.
Nếu phân phối thu nhập giữa người trả nợ và người không trả nợ có sự khác biệt rõ rệt, biến này có khả năng dự đoán tốt.
 Biểu đồ phân tích phân phối thu nhập theo khả năng vỡ nợ
Biểu đồ phân tích phân phối thu nhập theo khả năng vỡ nợ
2. Kiểm định Thống kê: Kruskal-Wallis
Để xác định chính thức mối quan hệ này, chúng ta sử dụng kiểm định Kruskal-Wallis. Đây là một phương pháp phi tham số, có nghĩa là nó không đòi hỏi dữ liệu phải tuân theo phân phối chuẩn.
Kiểm định này trả về giá trị p-value. Nếu p-value nhỏ hơn ngưỡng (thường là 0.05), chúng ta kết luận rằng có sự khác biệt đáng kể về phân phối giữa các nhóm.
Tối ưu hóa Phân tích Tương quan
Để xây dựng mô hình bền vững, chúng ta cần phân tích mối quan hệ giữa các loại biến số khác nhau.
A. Hai Biến Liên tục
Sử dụng Tương quan Spearman. Khác với Pearson chỉ đo lường mối quan hệ tuyến tính, Spearman đo lường mối quan hệ đơn điệu (tăng/giảm cùng chiều). Nó cũng khá bền vững với các điểm ngoại lệ (outliers).
Nếu chỉ số tương quan Spearman lớn hơn ngưỡng (ví dụ: 0.6), hai biến này có thể mang lại cùng một thông tin. Chúng ta chỉ nên giữ lại một trong số chúng, thường là biến có mối quan hệ mạnh nhất với biến mục tiêu (default).
B. Hai Biến Phân loại (Qualitative)
Sử dụng Cramér's V. Chỉ số này đo lường mức độ phụ thuộc giữa hai biến phân loại. Giá trị 0 nghĩa là không có mối quan hệ, và 1 là mối quan hệ hoàn toàn.
Thực tế, nếu Cramér's V vượt quá ngưỡng (ví dụ: 0.5), các biến này được coi là có mối liên hệ mạnh và nên loại bỏ một trong số chúng để tránh đa cộng tuyến.
Ứng dụng Thực tế trên Dữ liệu
Giả sử chúng ta đang làm việc với bộ dữ liệu tín dụng đã được làm sạch (loại bỏ giá trị thiếu và ngoại lệ). Chúng ta sẽ áp dụng các phương pháp trên để chọn lọc các biến số tốt nhất.
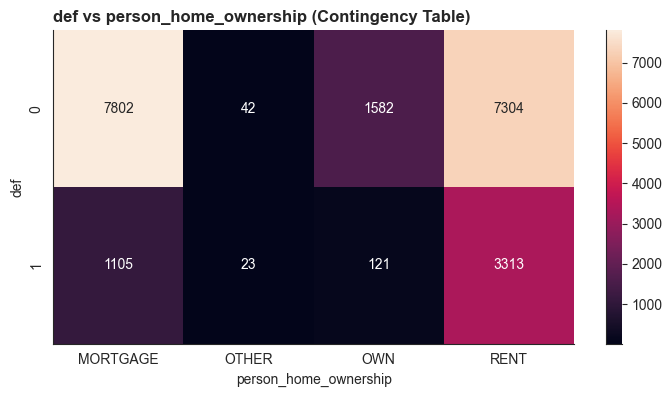
1. Tương quan giữa các biến liên tục và biến mục tiêu (Default) Chúng ta kiểm tra p-value từ kiểm định Kruskal-Wallis cho các biến như thu nhập, tuổi, độ dài lịch sử tín dụng. Kết quả cho thấy các biến này đều có khả năng phân biệt rủi ro tốt.
 Biểu đồ phân tích mối quan hệ giữa các biến số liên tục
Biểu đồ phân tích mối quan hệ giữa các biến số liên tục
2. Tương quan giữa các biến liên tục (Xóa trùng lặp) Khi phân tích ma trận tương quan Spearman, chúng ta phát hiện các cặp biến có mức độ tương quan cao (ví dụ: 85%):
- Thời gian lịch sử tín dụng (cb_person_cred_hist_length) và Tuổi (person_age): Đây là hai biến mô tả cùng một khía cạnh của khách hàng (kinh nghiệm/độ tuổi).
- Số tiền vay (loan_amnt) và Tỷ lệ vay trên thu nhập (loan_percent_income): Hai biến này thường đi đôi với nhau.
Quyết định: Chúng ta chỉ giữ lại person_age và loan_percent_income vì chúng có vẻ quan trọng hơn trong việc phân loại rủi ro so với các biến kia.
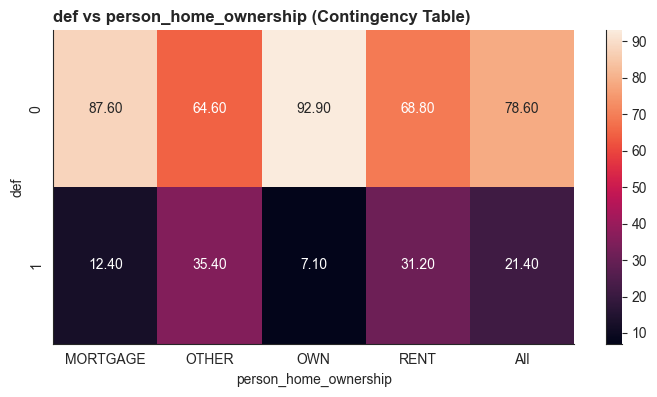
3. Tương quan giữa các biến phân loại
Sử dụng Cramér's V giữa các biến phân loại như loan_grade (hạng tín dụng) và cb_person_default_on_file (lịch sử vỡ nợ trước đó). Nếu chỉ số vượt quá ngưỡng 60%, chúng ta loại bỏ một biến.
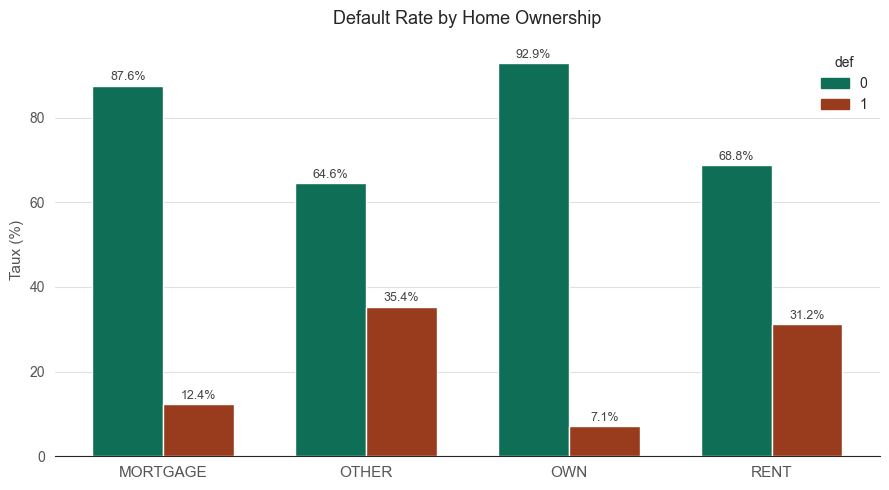 Phân tích mối quan hệ giữa các biến phân loại
Phân tích mối quan hệ giữa các biến phân loại
Kết luận
Quy trình xây dựng mô hình xếp hạng tín dụng không chỉ là một quá trình mã hóa. Nó đòi hỏi sự cân bằng giữa các kỹ thuật thống kê và tư duy chuyên môn.
Bằng cách sử dụng các công cụ trực quan hóa và kiểm định thống kê (Kruskal-Wallis, Spearman, Cramér's V), chúng ta có thể:
- Đánh giá chính xác khả năng dự đoán của từng biến số.
- Loại bỏ sự trùng lặp, giúp mô hình hoạt động hiệu quả hơn và tránh vấn đề đa cộng tuyến.
Ở bài viết tiếp theo, chúng ta sẽ tìm hiểu về các phương pháp lựa chọn đặc trưng (feature selection) mạnh mẽ hơn để tối ưu hóa thêm cho mô hình.
Bài viết liên quan

Phần cứng
Gemma 4 áp dụng Multi-Token Prediction, tăng tốc độ suy luận lên tới 3 lần
25 tháng 5, 2026

Công nghệ
Các tác nhân AI đã khiến thế giới công nghệ chao đảo: Câu chuyện đằng sau cuộc cách mạng Claude Code và OpenClaw
26 tháng 5, 2026

Phần cứng
Nvidia chính thức đưa siêu vi xử lý Grace Blackwell lên PC với dòng notebook RTX Spark
01 tháng 6, 2026