
Xu hướng kiến trúc LLM mới: KV Sharing, mHC và Compressed Attention giúp giảm chi phí ngữ cảnh dài
Bài viết phân tích các cải tiến kiến trúc trong các mô hình ngôn ngữ lớn (LLM) mới như Gemma 4, Laguna XS.2, ZAYA1 và DeepSeek V4. Các kỹ thuật như chia sẻ KV cache, kết nối siêu (hyper-connections) và nén attention đang giúp giảm đáng kể chi phí tính toán và bộ nhớ khi xử lý ngữ cảnh dài.

Xu hướng kiến trúc LLM mới: KV Sharing, mHC và Compressed Attention giúp giảm chi phí ngữ cảnh dài
Trong vài tuần qua, làng công nghệ đã chứng kiến sự xuất hiện của hàng loạt mô hình ngôn ngữ lớn (LLM) dạng open-weight (trọng số mở) mới. Điểm nổi bật nhất trong đợt ra mắt này không chỉ là việc tăng kích thước mô hình, mà là sự tập trung tối thượng vào hiệu quả xử lý ngữ cảnh dài. Khi các mô hình lý luận (reasoning models) và quy trình tác nhân (agent workflows) ngày càng yêu cầu xử lý nhiều token hơn trong thời gian dài hơn, kích thước bộ nhớ đệm KV (KV-cache), băng thông bộ nhớ và chi phí tính toán của cơ chế attention trở thành những nút thắt chính.
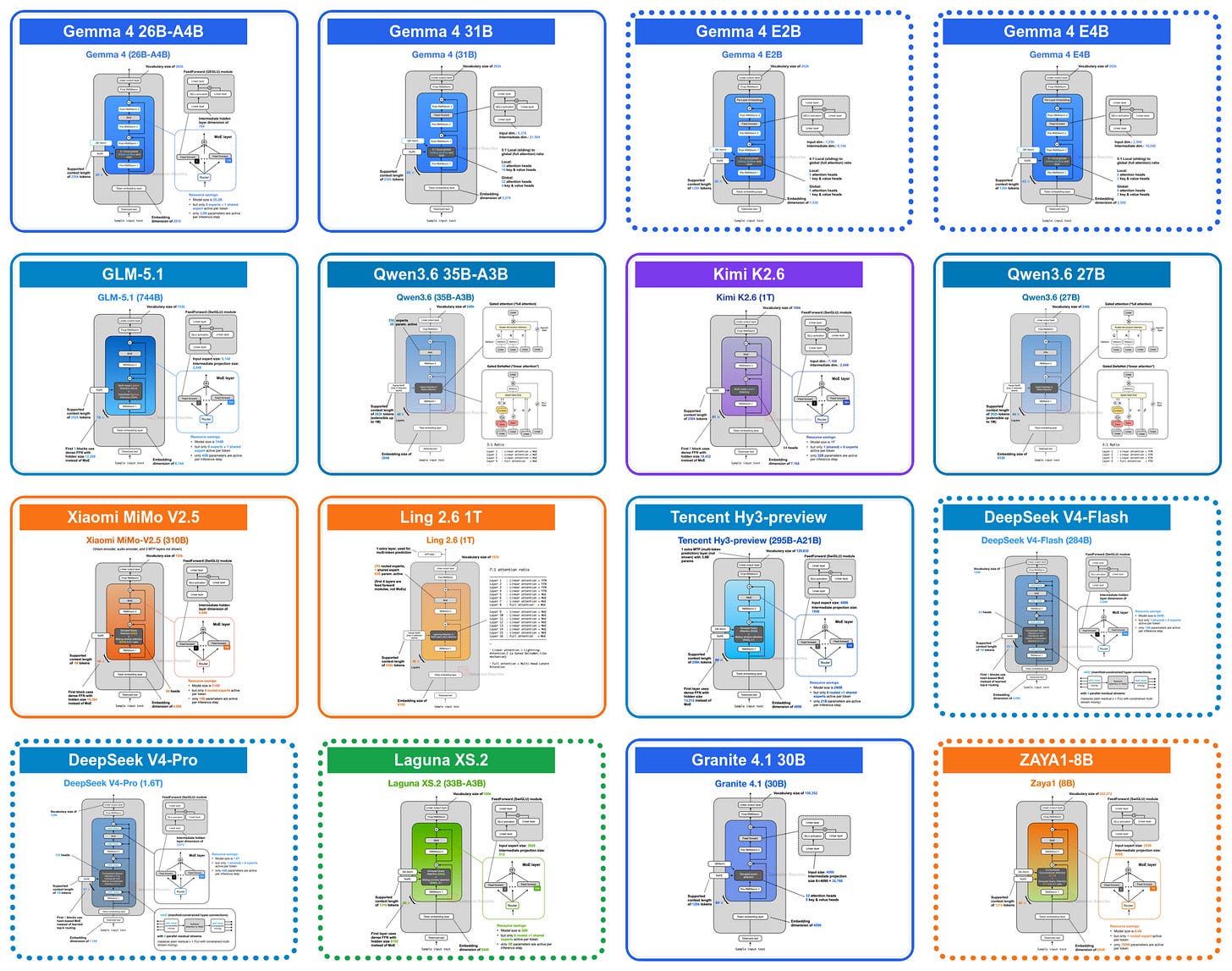 Tổng quan kiến trúc các LLM mới
Tổng quan kiến trúc các LLM mới
Hãy cùng điểm qua những thay đổi kiến trúc quan trọng nhất trong các mô hình như Gemma 4, Laguna XS.2, ZAYA1-8B và DeepSeek V4 đang giải quyết bài toán này như thế nào.
Gemma 4: Chia sẻ KV Cache và Per-Layer Embeddings
Google đã gây ấn tượng với bộ mô hình Gemma 4, đặc biệt là các biến thể E2B và E4B dành cho thiết bị di động và nhúng. Một trong những cải tiến thú vị nhất ở đây là kỹ thuật KV Sharing (chia sẻ KV) hay còn gọi là Cross-layer Attention.
Thông thường, mỗi lớp trong mạng Transformer sẽ tính toán riêng các phép chiếu Key (K) và Value (V) của riêng mình. Tuy nhiên, Gemma 4 cho phép các lớp sau này tái sử dụng trạng thái KV từ các lớp trước đó cùng loại. Ví dụ, Gemma 4 E2B có 35 lớp, nhưng chỉ 15 lớp đầu tiên tính toán KV projections; 20 lớp còn lại sẽ tái sử dụng KV từ lớp gần nhất trước đó.
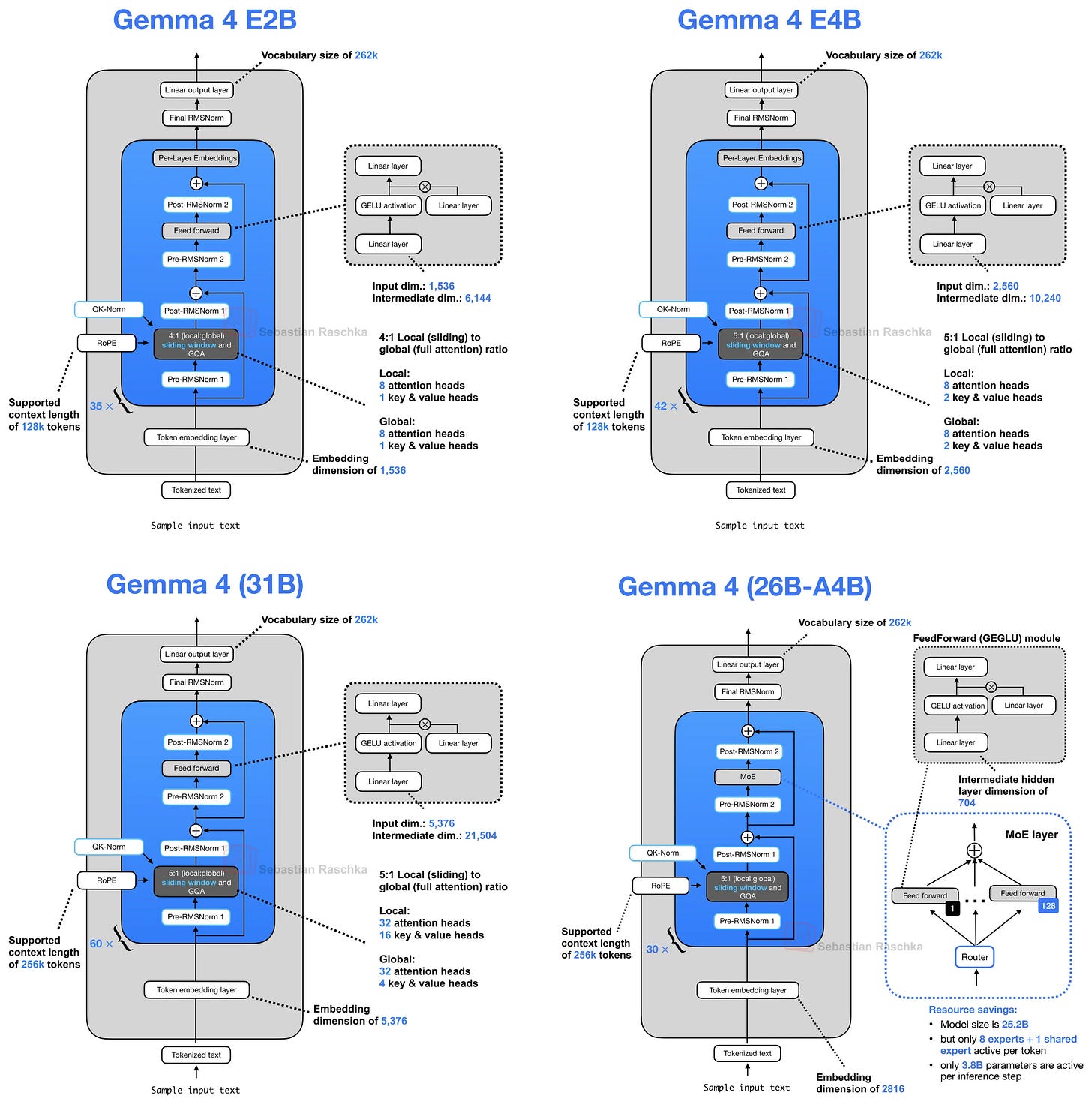 Kiến trúc Gemma 4
Kiến trúc Gemma 4
Điều này giúp tiết kiệm khoảng một nửa kích thước KV cache. Với ngữ cảnh dài 128K token, Gemma 4 E2B có thể tiết kiệm tới 2,7 GB bộ nhớ (ở định dạng bfloat16).
Bên cạnh đó, Gemma 4 còn giới thiệu Per-Layer Embeddings (PLE). Đây là một cách tiếp cận thông minh để tăng khả năng biểu diễn của mô hình mà không làm tăng chi phí tính toán của toàn bộ mạng Transformer. Thay vì mở rộng kích thước các lớp chính, Gemma 4 thêm các vector nhúng (embedding) riêng biệt cho từng lớp, giúp mô hình lưu trữ thêm thông tin cụ thể cho từng token với chi phí thấp hơn nhiều so với việc tăng thông số của mạng nơ-ron.
Laguna XS.2: Phân bổ ngân sách Attention theo từng lớp
Laguna XS.2, một mô hình mới từ Poolside, mang đến một khái niệm gọi là "Layer-wise attention budgeting". Thay vì cấp phát ngân sách tính toán như nhau cho mọi lớp, Laguna XS.2 thay đổi số lượng query heads tùy theo loại attention của lớp đó.
Mô hình này sử dụng kết hợp giữa 30 lớp Sliding-window attention (chú ý cửa sổ trượt) và 10 lớp Global attention (chú ý toàn cục). Các lớp sliding-window nhận được nhiều query heads hơn (8 heads cho mỗi KV head) để xử lý thông tin chi tiết cục bộ, trong khi các lớp global tốn kém hơn lại nhận ít query heads hơn (6 heads cho mỗi KV head). Cách tiếp cận này giúp tối ưu hóa việc sử dụng tài nguyên tính toán, tập trung sức mạnh vào nơi cần thiết nhất.
ZAYA1-8B: Compressed Convolutional Attention (CCA)
ZAYA1-8B từ Zyphra lại đi theo một hướng đi khác với cơ chế Compressed Convolutional Attention (CCA). Khác với Multi-head Latent Attention (MLA) của DeepSeek chủ yếu nén KV cache để lưu trữ, CCA thực hiện phép toán attention trực tiếp trong không gian tiềm ẩn (latent space) đã được nén.
Điều thú vị là CCA kết hợp thêm một bước "trộn tích chập" (convolutional mixing) lên các biểu diễn Q và K đã nén. Việc nén giúp giảm chi phí tính toán và bộ nhớ, nhưng có thể làm giảm khả năng biểu diễn. Phép tích chập này bù đắp bằng cách cung cấp thêm ngữ cảnh cục bộ cho các vector Q và K trước khi chúng tính toán điểm attention. Theo các thử nghiệm, CCA cho thấy hiệu suất tốt hơn MLA trong các cài đặt nén tương đương.
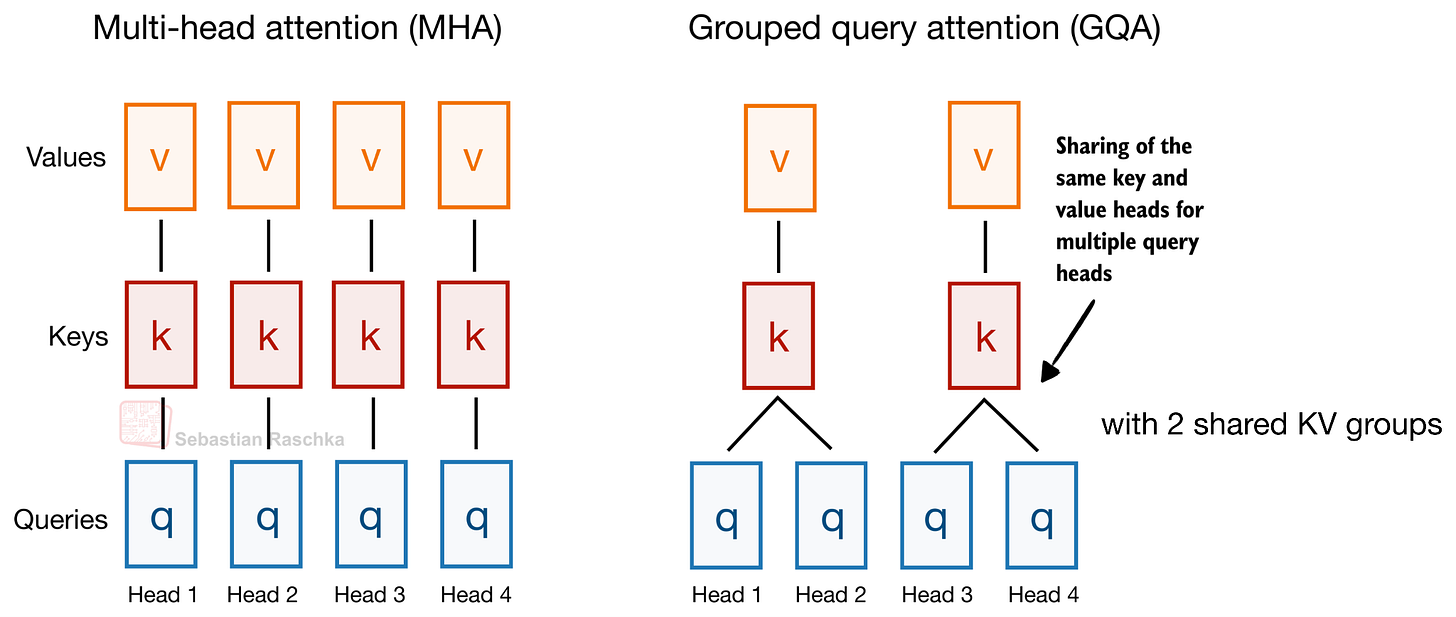
DeepSeek V4: mHC và Compressed Attention
DeepSeek V4 là cái tên nổi bật nhất với hai cải tiến lớn: Manifold-Constrained Hyper-Connections (mHC) và cơ chế attention nén CSA/HCA.
Manifold-Constrained Hyper-Connections (mHC)
mHC là sự hiện đại hóa của các kết nối dư thừa (residual connections) trong khối Transformer. Thay vì chỉ có một luồng dư thừa duy nhất, mHC sử dụng nhiều luồng song song và các phép ánh xạ đã học để trộn thông tin giữa chúng.
Điểm đặc biệt là các phép ánh xạ này bị ràng buộc bởi các ma trận "doubly stochastic" (các phần tử không âm và tổng mỗi hàng/cột bằng 1). Điều này giúp việc trộn thông tin ổn định hơn, tránh việc khuếch đại hoặc thu hẹp tín hiệu một cách khó kiểm soát khi mô hình trở nên sâu hơn. Kết quả là khả năng biểu diễn của luồng dư thừa được tăng cường mà không làm tăng quá nhiều chi phí tính toán.
Compressed Sparse Attention (CSA) và Heavily Compressed Attention (HCA)
Để xử lý ngữ cảnh siêu dài (lên tới 1 triệu token), DeepSeek V4 sử dụng kết hợp CSA và HCA. Khác với MLA chỉ nén biểu diễn của từng token, CSA và HCA nén theo chiều chuỗi (sequence dimension).
- CSA: Nén nhẹ nhàng hơn và sử dụng cơ chế chọn lọc thưa (sparse selection) kiểu DeepSeek Sparse Attention.
- HCA: Nén mạnh mẽ hơn rất nhiều (ví dụ: 128 token thành 1 entry nén) và sử dụng dense attention trên các entry này.
Cả hai đều giữ lại một nhánh sliding-window cho các token gần nhất không bị nén. Nhờ đó, DeepSeek V4-Pro chỉ sử dụng 27% FLOPs suy luận và 10% kích thước KV cache so với DeepSeek V3.2 ở độ dài ngữ cảnh 1 triệu token.
 Kiến trúc DeepSeek V4-Pro
Kiến trúc DeepSeek V4-Pro
Kết luận
Nhìn chung, xu hướng kiến trúc LLM năm nay đang chuyển dịch từ việc chỉ tăng kích thước mô hình sang việc tinh chỉnh khối Transformer một cách mục tiêu để tối ưu hóa hiệu quả cho ngữ cảnh dài. Từ việc chia sẻ KV cache, phân bổ ngân sách attention theo lớp, đến việc thực hiện attention trong không gian nén hay mở rộng luồng dư thừa, tất cả đều nhằm mục đích giảm chi phí vận hành mà vẫn giữ được hiệu suất mô hình.
Tuy nhiên, sự phức tạp của các kiến trúc này cũng đang tăng lên nhanh chóng. Việc triển khai một khối Transformer cơ bản từng rất đơn giản, nhưng giờ đây với hàng loạt các biến thể attention và kết nối mới, việc hiểu và mã hóa chúng trở nên thách thức hơn bao giờ hết. Điều này cho thấy sự trưởng thành của ngành công nghệ AI, nơi việc tối ưu hóa chi phí đang trở nên quan trọng ngang hàng với việc cải thiện chất lượng mô hình.


