
Xử lý theo Lô (Batch) hay Luồng (Stream)? Nan giải vĩnh cửu trong xử lý dữ liệu
Thay vì tranh luận về batch hay stream, câu hỏi thực sự nên là: Khi nào dữ liệu mới cần được xử lý? Bài viết cung cấp một khung quyết định thực tế cùng cách triển khai trên Microsoft Fabric để tối ưu hóa cả hai phương pháp này.

Nếu bạn đã dành thời gian làm việc trong lĩnh vực kỹ thuật dữ liệu (data engineering), bạn chắc chắn đã từng gặp phải cuộc tranh luận này ít nhất một lần. "Chúng ta nên xử lý dữ liệu theo lô (batch) hay theo thời gian thực (real-time)?" Và nếu bạn giống như tôi, bạn sẽ nhận thấy câu trả lời thường bắt đầu bằng câu thần chú: "Chà, điều đó tùy thuộc vào…"
Điều đó là đúng. Nó thực sự tùy thuộc. Nhưng "tùy thuộc" chỉ có ích khi bạn biết chính xác nó phụ thuộc vào điều gì. Đó chính là khoảng trống mà bài viết này muốn lấp đầy. Không phải là một so sánh lý thuyết khô khan giữa batch và stream, mà là một khung thực tế để giúp bạn quyết định phương pháp nào phù hợp với tình huống cụ thể của mình, đồng thời xem xét cách cả hai phương pháp này được triển khai trên Microsoft Fabric.
Đó không phải là cuộc chiến giữa Batch và Stream, mà là câu hỏi: "Khi nào câu trả lời mới thực sự quan trọng?"
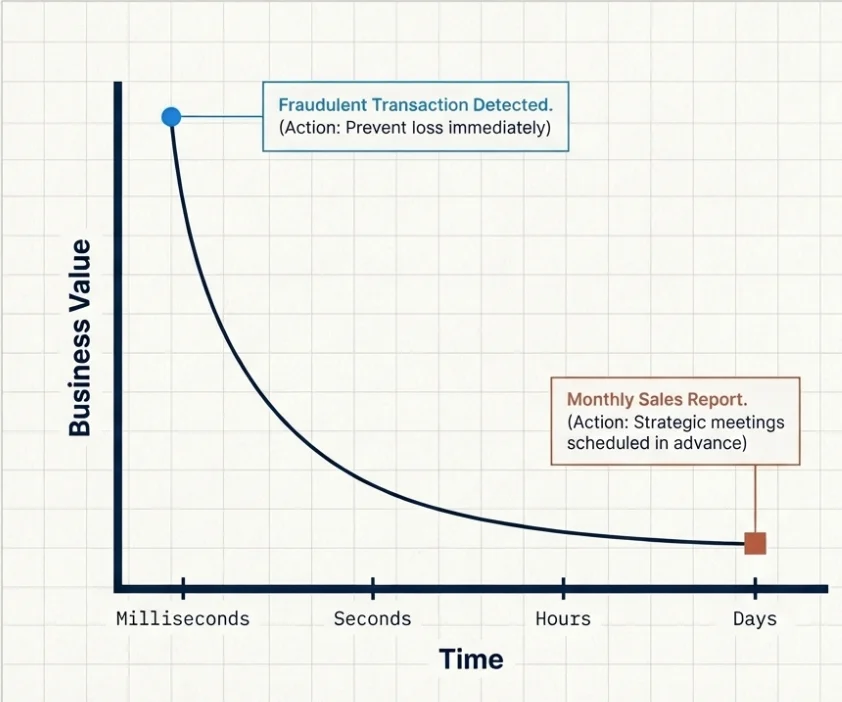 Giá trị của tính mới mẻ trong dữ liệu
Giá trị của tính mới mẻ trong dữ liệu
Hãy bỏ qua các định nghĩa khô khan và đi thẳng vào điều thực sự phân biệt hai phương pháp này: giá trị của tính mới mẻ (freshness).
Mọi dữ liệu đều có một "hạn sử dụng". Không phải theo nghĩa nó sẽ hết hạn và trở nên vô dụng, mà là theo nghĩa giá trị kinh doanh của nó thay đổi theo thời gian. Một giao dịch thẻ tín dụng gian lận được phát hiện trong vòng 200 mili-giây? Vô giá – bạn vừa ngăn chặn được một khoản thiệt hại. Cùng hành vi gian lận đó được phát hiện 6 giờ sau đó trong một công việc xử lý theo lô ban đêm? Có thể hữu ích cho báo cáo, nhưng tiền đã mất rồi.
Ngược lại, một báo cáo doanh số hàng tháng được tạo từ dữ liệu của hôm nay so với dữ liệu mới chỉ 3 phút? Trong hầu hết các tổ chức, không ai nhận ra sự khác biệt (và có lẽ không ai quan tâm). Các quyết định kinh doanh dựa trên báo cáo đó được đưa ra trong các cuộc họp được lên lịch trước nhiều ngày, chứ không phải tính bằng mili-giây ngay sau khi dữ liệu về.
Vì vậy, câu hỏi đầu tiên không phải là "Batch hay Stream?". Câu hỏi đầu tiên là: Cái nào (hoặc cái gì) cần hành động dựa trên dữ liệu này nhanh như thế nào thì nó mới có ý nghĩa?
Nếu câu trả lời là "vài giây hoặc ít hơn", bạn đang ở lãnh thổ của Stream. Nếu câu trả lời là "vài giờ hoặc vài ngày", Batch có lẽ là lựa chọn tốt. Và nếu câu trả lời là "ở đâu đó ở giữa"… Chúc mừng, bạn đang ở trong "vùng xám" thú vị nhất (và phổ biến nhất), mà chúng ta sẽ khám phá ngay sau đây.
Sự đánh đổi cần cân nhắc
Bạn biết sự thật không thoải mái nhất về xử lý luồng là gì không? Trên giấy tờ, nó nghe thật tuyệt vời. Ai mà lại không muốn dữ liệu thời gian thực? Nó giống như việc được hỏi: "Bạn muốn cà phê bây giờ hay sau 6 giờ nữa?" Nhưng thực tế lại tinh tế hơn nhiều. Hãy cùng đi qua các sự đánh đổi thực sự khi bạn đưa ra quyết định này.
 So sánh các yếu tố đánh đổi
So sánh các yếu tố đánh đổi
Chi phí
Hạ tầng xử lý luồng gần như luôn tốn kém hơn xử lý theo lô cho cùng một khối lượng dữ liệu. Tại sao? Bởi vì stream yêu cầu tài nguyên phải luôn hoạt động, lắng nghe, xử lý và ghi liên tục. Batch thì khác: nó khởi động, thực hiện công việc và tắt đi. Bạn chỉ thanh toán cho tài nguyên tính toán khi công việc chạy.
Hãy tưởng tượng giống như một nhà hàng. Một bếp batch mở vào các giờ cố định – nhân viên đến, chuẩn bị, nấu ăn, dọn dẹp và về nhà. Một bếp stream mở 24/7 với nhân viên luôn trực sẵn sàng để nấu ngay khi đơn hàng đến. Ngay cả trong giờ yên tĩnh lúc 3 giờ sáng khi không ai đặt món, vẫn có người ở đó chờ đợi. Việc chờ đợi này tốn kém tiền bạc.
Độ phức tạp
Xử lý theo lô về mặt khái niệm đơn giản hơn. Bạn có một đầu vào xác định, một phép biến đổi xác định và một đầu ra xác định. Nếu có lỗi, bạn chỉ cần chạy lại công việc. Dữ liệu nằm yên trong một tệp hoặc bảng, kiên nhẫn chờ đợi.
Với Stream, mọi thứ trở nên khó khăn hơn. Bạn phải đối mặt với dữ liệu đến liên tục, có thể không theo thứ tự, có thể trùng lặp và có thể bị thiếu. Điều gì xảy ra khi một cảm biến ngắt kết nối trong 5 phút rồi đổ toàn bộ dữ liệu đệm xuống cùng lúc? Khi hai sự kiện đến sai thứ tự thì sao? Khi công cụ xử lý bị sập giữa chừng thì sao? Bạn có chạy lại từ đầu không? Từ một điểm kiểm tra (checkpoint)? Làm sao để đảm bảo xử lý chính xác "một lần" (exactly-once)?
Độ chính xác
Batch có lợi thế tự nhiên về độ chính xác vì nó hoạt động trên tập dữ liệu hoàn chỉnh. Khi công việc batch chạy lúc 2 giờ sáng, nó có quyền truy cập vào tất cả dữ liệu của ngày trước đó. Mọi bản ghi đến muộn, mọi chỉnh sửa, mọi cập nhật đều có ở đó. Công việc có thể tính toán tổng hợp, kết nối và biến đổi dựa trên bức tranh toàn cảnh.
Stream, theo định nghĩa, hoạt động trên dữ liệu chưa hoàn chỉnh. Bạn đang xử lý các bản ghi ngay khi chúng đến, điều này có nghĩa là kết quả của bạn luôn mang tính tạm thời. Con số doanh thu hàng ngày mà bạn tính toán lúc 23:59? Một vài giao dịch đến muộn có thể thay đổi nó vào lúc nửa đêm. Các chiến lược cửa sổ (windowing) và mốc nước (watermarks) giúp quản lý việc này, nhưng chúng thêm một lớp quyết định khác nữa.
Khi nào nên dùng cái gì?
Hãy xem xét một số tình huống cụ thể và lý do đằng sau từng lựa chọn.
Batch là lựa chọn tốt nhất khi…
- Dữ liệu của bạn đến theo các khoảng thời gian có thể dự đoán được. Các tệp được gửi hàng ngày từ máy chủ SFTP, xuất khẩu theo giờ từ API, tải lên CSV hàng tuần từ nhà cung cấp. Dữ liệu không nhạy cảm về thời gian.
- Bạn cần các phép biến đổi phức tạp bao gồm toàn bộ tập dữ liệu. Huấn luyện mô hình machine learning, tính toán so sánh năm qua năm, thực hiện các kết nối quy mô lớn giữa các bảng sự kiện và các kích thước thay đổi chậm (slowly changing dimensions).
- Tối ưu hóa chi phí là ưu tiên. Nếu ngân sách hạn hẹp và yêu cầu về tính mới mẻ không nghiêm ngặt (tính bằng giờ, không phải giây), batch cho phép bạn chạy tính toán cường độ cao theo nhu cầu và tắt nó đi khi xong.
- Độ chính xác của dữ liệu quan trọng hơn tốc độ. Đối soát tài chính, báo cáo quy định, vết kiểm toán… Đúng quan trọng hơn nhanh.
Stream là hướng đi khi…
- Một người (hoặc một cái gì đó) cần hành động dựa trên dữ liệu ngay lập tức. Phát hiện gian lận, giám sát bất thường, cảnh báo IoT, bảng điều khiển trực tiếp cho đội ngũ vận hành… Giá trị của dữ liệu suy giảm nhanh theo thời gian.
- Dữ liệu tự nhiên liên tục. Clickstreams, dữ liệu cảm biến, nhật ký ứng dụng và nguồn cấp dữ liệu mạng xã hội không phải là các nguồn dữ liệu "theo lô" tự nhiên. Chúng tạo ra sự kiện liên tục.
- Bạn đang xây dựng kiến trúc dựa trên sự kiện (event-driven). Các vi dịch vụ giao tiếp qua bus sự kiện, hệ thống xử lý đơn hàng, động cơ cá nhân hóa thời gian thực.
- Bạn cần phát hiện các mẫu theo thời gian. "Cảnh báo cho tôi nếu việc sử dụng CPU vượt quá 90% trong hơn 5 phút liên tục." Các vấn đề này là vấn đề của stream một cách tự nhiên.
Điều này diễn ra như thế nào trong Microsoft Fabric?
Một trong những điều tôi thực sự đánh giá cao ở Microsoft Fabric là nó không ép buộc bạn vào một mô hình xử lý duy nhất. Cả batch và stream đều là những công dân hạng nhất trong nền tảng này. Quan trọng hơn, chúng chia sẻ cùng một lớp lưu trữ (OneLake) và cùng một mô hình tiêu thụ (Capacity Units).
 Kiến trúc Microsoft Fabric
Kiến trúc Microsoft Fabric
Xử lý Batch trong Fabric
Đối với khối lượng công việc batch, Fabric cung cấp nhiều tùy chọn tùy thuộc vào bộ kỹ năng và yêu cầu của bạn:
- Data Pipelines: Xương sống điều phối. Nếu bạn đến từ Azure Data Factory, điều này sẽ quen thuộc. Bạn có thể lên lịch các pipeline chạy vào các thời điểm cụ thể hoặc kích hoạt dựa trên sự kiện.
- Fabric Notebooks: Nơi thực hiện công việc nặng nhọc. Bạn có thể viết mã PySpark, Spark SQL, Python hoặc Scala để thực hiện các phép biến đổi phức tạp trên các tập dữ liệu lớn.
- Dataflows Gen2: Một lựa chọn low-code/no-code sử dụng giao diện Power Query quen thuộc. Các cải tiến hiệu suất gần đây đã khiến chúng trở thành một lựa chọn cạnh tranh hơn về mặt chi phí/hiệu suất.
- Fabric Data Warehouse: Cung cấp trải nghiệm dựa trên T-SQL cho những người thích cách tiếp cận quan hệ.
Tất cả những cái này ghi đầu ra dưới dạng bảng Delta trong OneLake, có nghĩa là kết quả có sẵn ngay lập tức cho bất kỳ công cụ Fabric nào phía dưới.
Xử lý Stream trong Fabric
Đối với khối lượng công việc thời gian thực, Real-Time Intelligence của Fabric là nơi mọi việc diễn ra.
- Eventstreams: Lớp tiếp nhận dữ liệu luồng. Bạn có thể kết nối với các nguồn như Azure Event Hubs, Azure IoT Hub, Kafka, v.v.
- Eventhouses (được hỗ trợ bởi cơ sở dữ liệu KQL): Lưu trữ và công cụ tính toán cho dữ liệu thời gian thực. Dữ liệu đổ vào các bảng KQL và có thể truy vấn ngay lập tức bằng ngôn ngữ truy vấn Kusto (KQL).
- Real-Time Dashboards: Cho phép trực quan hóa dữ liệu luồng với khả năng tự động làm mới.
- Activator: Cho phép bạn định nghĩa các điều kiện và kích hoạt hành động dựa trên dữ liệu thời gian thực. "Nếu nhiệt độ vượt quá 80°C, hãy gửi thông báo Teams."
Điểm chính cần lưu ý ở đây: dữ liệu Real-Time Intelligence cũng sống trong OneLake. Điều này có nghĩa là dữ liệu luồng và dữ liệu batch của bạn cùng tồn tại trong cùng một lớp lưu trữ. Ranh giới giữa batch và stream bắt đầu mờ đi, và đó chính là điểm mà chúng ta muốn nhấn mạnh.
Kết luận: Cái tốt của cả hai thế giới
Các kiến trúc dữ liệu tốt nhất không phải là những kiến trúc chỉ thuần túy batch hay thuần túy streaming. Chúng là những kiến trúc sử dụng từng phương pháp ở nơi nó có ý nghĩa nhất, và có một nền tảng bên dưới làm cho cả hai con đường đều tự nhiên.
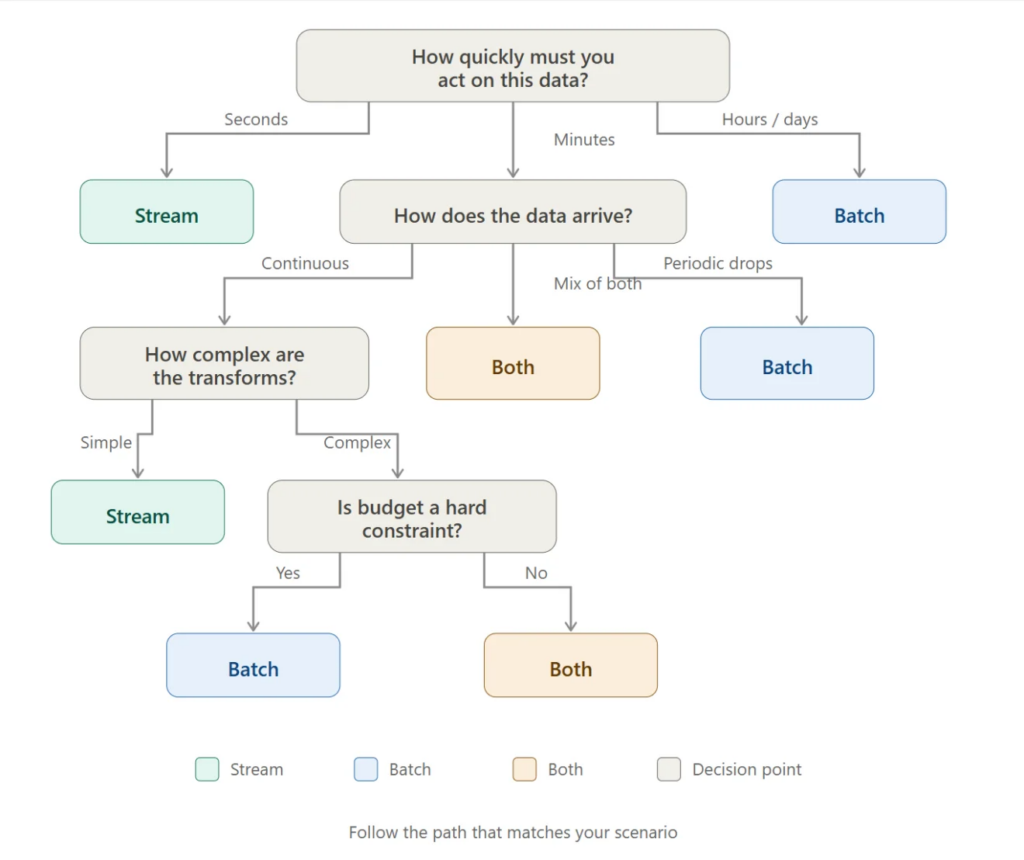
Để tóm lại, đây là một bộ câu hỏi đơn giản bạn có thể tự đặt ra cho từng trường hợp sử dụng:
- Nhanh như thế nào thì ai đó cần hành động dựa trên dữ liệu này? (Nếu vài giây -> stream. Nếu vài giờ/ngày -> batch).
- Dữ liệu đến như thế nào? (Sự kiện liên tục -> stream. Các tệp theo chu kỳ -> batch).
- Phép biến đổi phức tạp đến mức nào? (Các kết nối lớn, huấn luyện ML -> batch).
- Ngân sách của bạn là bao nhiêu? (Tính toán luôn bật cho stream vs tính toán theo yêu cầu cho batch).
- Tính hoàn chỉnh của dữ liệu quan trọng như thế nào? (Cần bức tranh toàn cảnh trước khi quyết định -> batch).
Microsoft Fabric thể hiện rằng bạn không buộc phải chọn một paradigm duy nhất cho toàn bộ nền tảng dữ liệu của mình. Hãy sử dụng công cụ phù hợp cho từng trường hợp sử dụng.
Bài viết liên quan

Phần mềm
Tối ưu hóa hệ thống gợi ý bằng LLM và Python: Cách cân bằng giữa tốc độ và độ chính xác
08 tháng 6, 2026

Phần mềm
Giám đốc Rimini Street: "Headless ERP" và mã nguồn mở là chìa khóa thoát khỏi sự kiểm soát của nhà cung cấp
16 tháng 6, 2026

Công nghệ
Amazon ra mắt tính năng Sleep Studio giúp trẻ em đi ngủ dễ dàng hơn trên loa Echo
10 tháng 6, 2026