
ZAYA1-8B: Mô hình AI chuyên Toán và Lập trình, chạy trên phần cứng AMD và chỉ dùng dưới 1 tỷ tham số hoạt động
Zyphra vừa ra mắt ZAYA1-8B, một mô hình AI nhỏ gọn nhưng sở hữu khả năng giải toán và lập trình ngang bằng các "gã khổng lồ" như DeepSeek-R1. Điểm đặc biệt nhất là mô hình này được huấn luyện hoàn toàn trên phần cứng AMD và chỉ sử dụng dưới 1 tỷ tham số hoạt động nhờ kiến trúc Mixture of Experts.

Zyphra vừa công bố ZAYA1-8B, một mô hình trí tuệ nhân tạo mới đang gây tiếng vang lớn trong cộng đồng công nghệ nhờ những thông số ấn tượng. Mô hình này không chỉ cạnh tranh sòng phẳng với DeepSeek-R1 trong các bài kiểm tra toán học, mà còn tiệm cận Claude Sonnet 4.5 về khả năng lập luận và Gemini 2.5 Pro về lập trình.
Điều đáng nói là ZAYA1-8B đạt được hiệu suất này với chỉ 760 triệu tham số hoạt động, một con số cực kỳ thấp so với các đối thủ, và quan trọng hơn hết, nó được huấn luyện hoàn toàn trên phần cứng của AMD thay vì NVIDIA.
Mô hình ZAYA1-8B
Bước đột phá trên phần cứng AMD
Hầu hết các mô hình AI hàng đầu hiện nay đều phụ thuộc vào hệ sinh thái phần cứng của NVIDIA (như dòng H100 hay A100). Tuy nhiên, Zyphra đã chọn một con đường khác khi huấn luyện ZAYA1-8B từ đầu đến cuối trên GPU AMD Instinct MI300X.
Quá trình này bao gồm tiền huấn luyện, huấn luyện giữa và tinh chỉnh có giám sát, tất cả đều được thực hiện trên một cụm máy gồm 1.024 nút AMD được xây dựng bởi IBM sử dụng kết nối AMD Pensando Pollara.
Chi tiết này có ý nghĩa quan trọng vì hai lý do. Thứ nhất, nó chứng minh rằng stack phần cứng của AMD hoàn toàn có thể tạo ra các kết quả cạnh tranh ở cấp độ tiên tiến. Thứ hai, nó mở ra cơ hội đa dạng hóa cơ sở hạ tầng, giúp các tổ chức không bị phụ thuộc hoàn toàn vào định giá của NVIDIA.
Hiệu quả vượt trội với kiến trúc Mixture of Experts
ZAYA1-8B là một mô hình Mixture of Experts (MoE) với tổng cộng 8,4 tỷ tham số, nhưng chỉ có 760 triệu tham số thực sự hoạt động tại thời điểm suy luận (inference).
Trong các mô hình dày đặc truyền thống, mọi tham số sẽ kích hoạt cho mỗi token. Ngược lại, với kiến trúc MoE, chỉ một tập hợp con các "chuyên gia" được kích hoạt cho mỗi token, giúp giảm thiểu đáng kể chi phí tính toán. ZAYA1-8B tận dụng tối đa điều này, cho phép chạy suy luận với chi phí tương đương một mô hình dưới 1 tỷ tham số nhưng vẫn khai thác được kiến thức từ 8,4 tỷ tham số tổng.
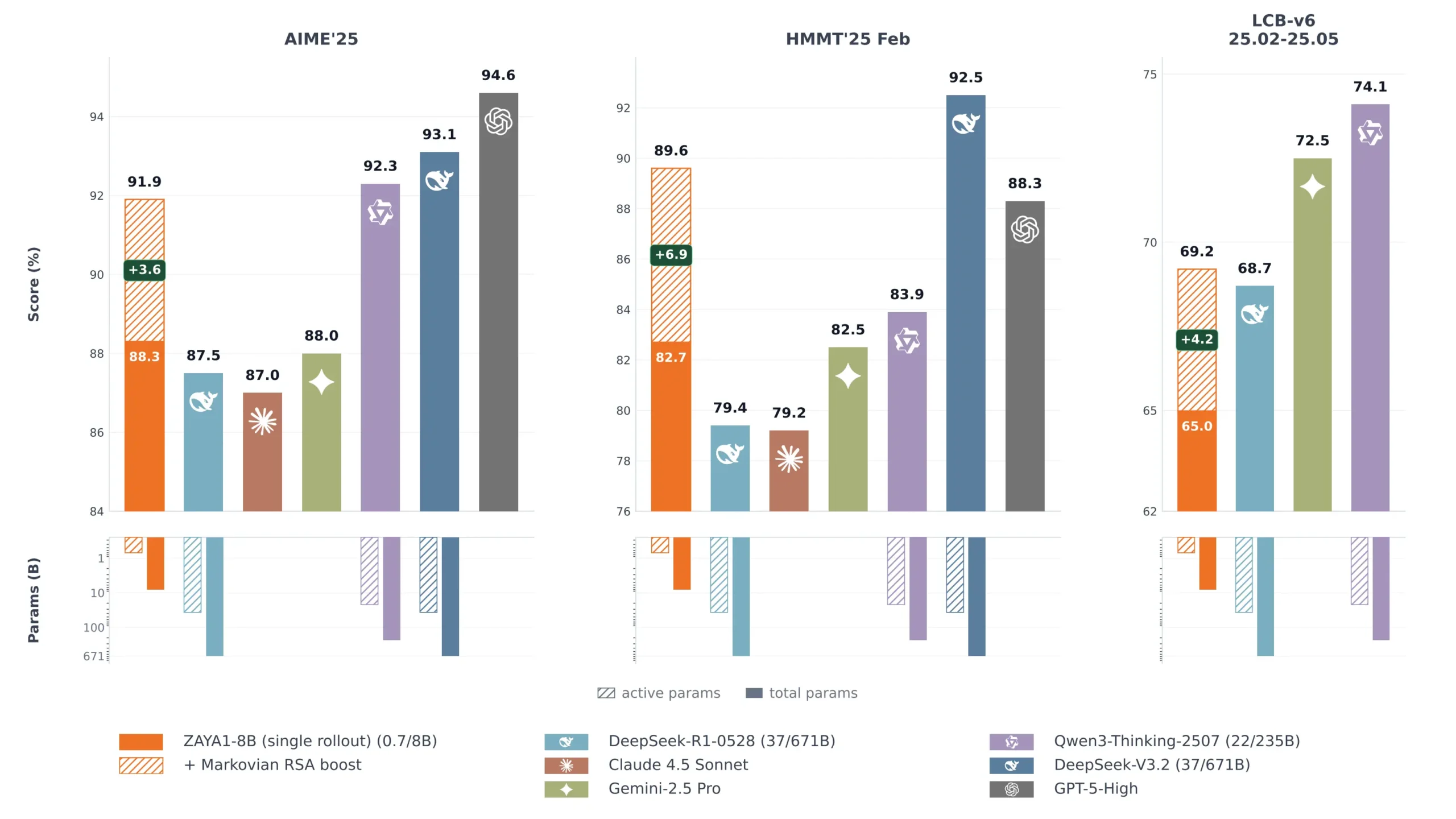 So sánh hiệu năng ZAYA1-8B
So sánh hiệu năng ZAYA1-8B
Khả năng Toán học và Lập trình
Theo báo cáo từ Zyphra, ZAYA1-8B thể hiện sức mạnh đáng kinh ngạc trên các benchmark toán học và lập trình:
- AIME 2026: Đạt 89,1 điểm, vượt qua Mistral Small 4 (119 tỷ tham số) với 86,4 điểm.
- HMMT (Tháng 2): Đạt 71,6 điểm, so với 70,6 điểm của Mistral Small 4.
- LiveCodeBench: Đạt 65,8 điểm, vượt trội so với 57,9 điểm của Mistral Small 4.
Những con số này cho thấy một mô hình chỉ có 760 triệu tham số hoạt động có thể vượt qua các đối thủ có tới 6 tỷ tham số hoạt động trong các bài toán chuyên sâu.
Zyphra cũng giới thiệu phương pháp suy luận mới gọi là Markovian RSA. Thay vì tạo ra một chuỗi lập luận dài duy nhất dễ bị mất ngữ cảnh, mô hình này lập luận theo từng khối. Mỗi khối tạo ra nhiều dấu vết song song, trích xuất phần quan trọng và sử dụng chúng làm hạt giống cho vòng tiếp theo. Điều này giúp mô hình hoạt động tốt hơn khi được cấp thêm tài nguyên tính toán để "suy nghĩ".
Những hạn chế cần lưu ý
Mặc dù xuất sắc trong toán học và lập trình, ZAYA1-8B không phải là một trợ lý toàn năng.
- Khả năng tác tử (Agentic): Điểm số BFCL-V4 (kiểm tra khả năng gọi hàm) chỉ ở mức 39,22, thấp hơn đáng kể so với Qwen3-4B-Thinking (49,7).
- Tuân thủ hướng dẫn: Kết quả IFBench ở mức 52,56, cho thấy mô hình chưa thực sự mạnh mẽ trong việc tuân thủ các hướng dẫn phức tạp đa bước.
- Chất lượng trò chuyện: Các chỉ số như EQBench và Creative Writing đều thấp hơn các mô hình tương đương.
Do đó, ZAYA1-8B được định vị rõ ràng là một chuyên gia về lập luận, toán học và mã hóa, chứ không phải là một chatbot thông dụng.
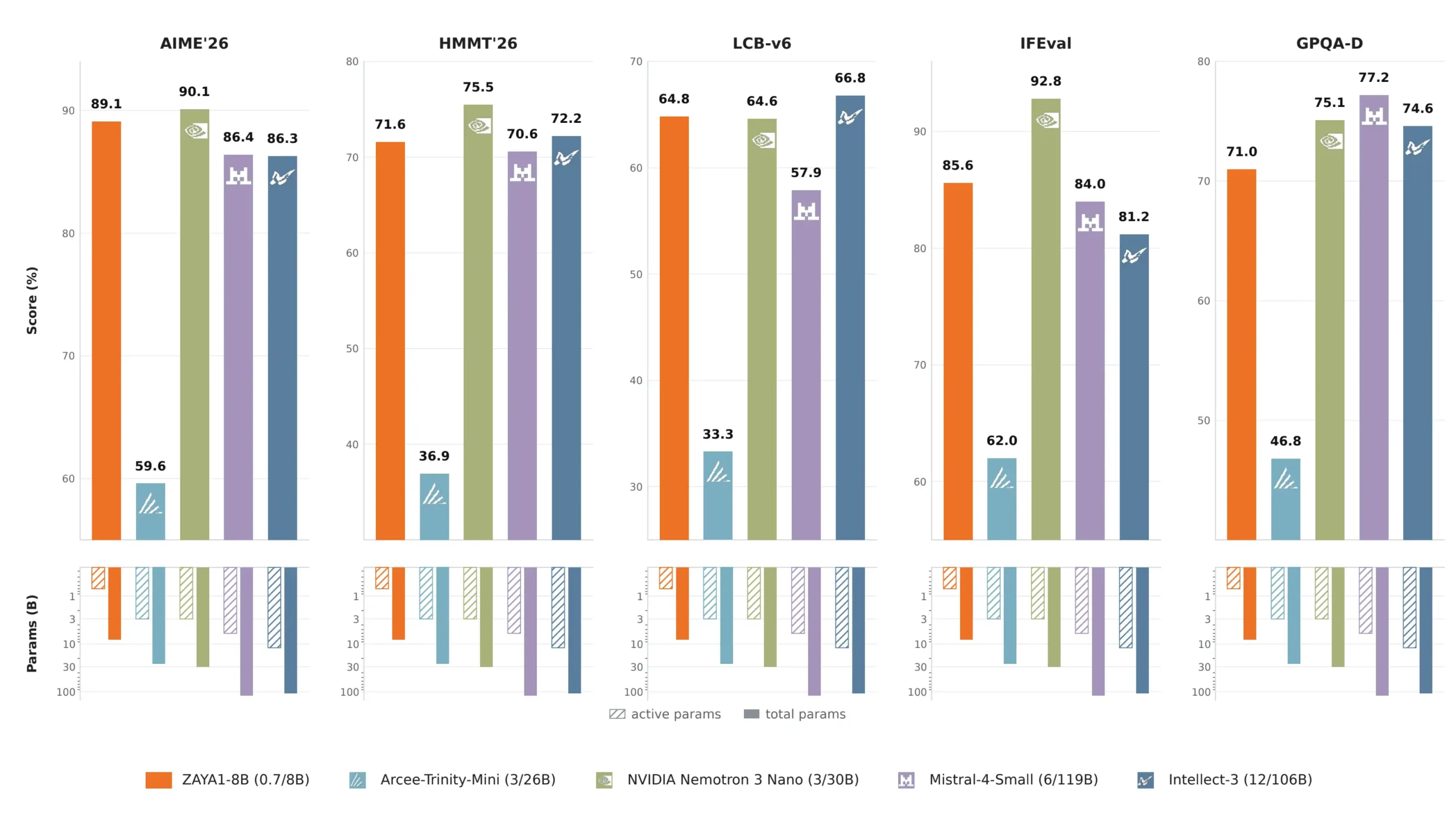 So sánh với các mô hình mã nguồn mở khác
So sánh với các mô hình mã nguồn mở khác
Cách trải nghiệm ZAYA1-8B
Hiện tại, người dùng có thể trải nghiệm ZAYA1-8B thông qua Zyphra Cloud dưới dạng endpoint serverless. Đối với những người muốn triển khai cục bộ, các trọng số (weights) của mô hình đã được công bố trên Hugging Face với giấy phép Apache 2.0.
Tuy nhiên, cần lưu ý rằng để chạy ZAYA1-8B cục bộ, bạn cần sử dụng bản fork vLLM riêng của Zyphra thay vì bản cài đặt vLLM tiêu chuẩn.
Nếu bạn đang làm việc trong lĩnh vực khoa học, giải quyết các bài toán toán học phức tạp hoặc lập trình, ZAYA1-8B là một lựa chọn nhỏ gọn và hiệu quả đáng để cân nhắc. Nhưng nếu bạn cần một mô hình đa năng cho các tác vụ tác tử hoặc trò chuyện hàng ngày, các giải pháp khác có thể phù hợp hơn.
Bài viết liên quan

Phần cứng
Schlage ra mắt khóa thông minh Sense Pro hỗ trợ mở khóa không chạm UWB và Matter over Thread
16 tháng 6, 2026

Phần cứng
Lỗ hổng kernel macOS đầu tiên bị khai thác thành công trên chip Apple M5
14 tháng 5, 2026

Phần cứng
Người Mỹ không biết cách chống lại AI, nên họ chuyển sang tấn công trung tâm dữ liệu
02 tháng 6, 2026