
AI học cách nhìn thấy trong không gian 3D và thấu hiểu thế giới thực như thế nào?
Bài viết phân tích cách các mô hình ước lượng độ sâu, phân đoạn nền tảng và hợp nhất hình học đang hội tụ để tạo nên "Trí tuệ không gian". Đây là bước đột phá giúp AI chuyển từ việc hiểu các pixel 2D sang việc mô hình hóa chính xác môi trường vật lý 3D từ những bức ảnh đơn giản.

AI có thể phân loại một bức ảnh căn bếp trong tích tắc. Nó có thể phân đoạn từng vật thể trong một khung cảnh đường phố, tạo ra những hình ảnh chân thực của những căn phòng không có thật, và viết những mô tả thuyết phục về những nơi nó chưa từng đặt chân đến.
Tuy nhiên, hãy yêu cầu nó bước vào một căn phòng thực sự và cho bạn biết vật nào nằm trên kệ nào, bàn cách tường bao xa, hay trần nhà kết thúc ở đâu và cửa sổ bắt đầu từ đâu trong không gian vật lý — ảo ảnh sẽ vỡ vụn.
Những mô hình thống trị các điểm chuẩn thị giác máy tính hiện nay hoạt động trên "vùng đất phẳng" (flatland). Chúng suy luận dựa trên các điểm ảnh trên một lưới 2D. Chúng không có sự hiểu biết nguyên bản về thế giới 3D mà những điểm ảnh đó mô tả.
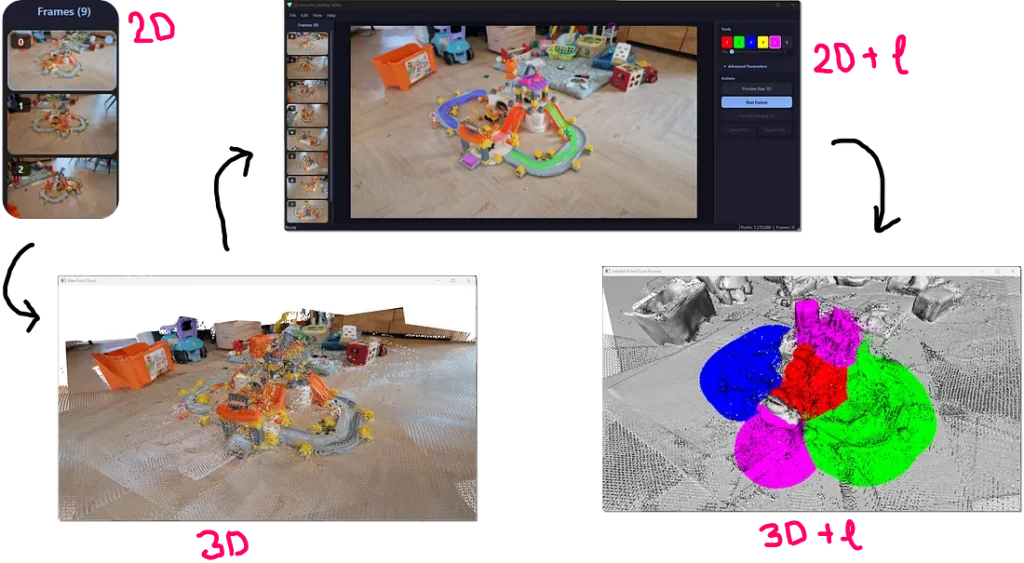 Quy trình AI không gian
Quy trình AI không gian
Khoảng cách giữa trí tuệ cấp độ điểm ảnh và sự thấu hiểu không gian không chỉ là một bất tiện nhỏ. Đó là nút thắt lớn nhất ngăn cách các hệ thống AI hiện nay với những ứng dụng thế giới thực quan trọng nhất: robot điều hướng trong kho bãi, xe tự lái tránh vật cản, và bản sao số (digital twins) phản ánh chính xác các tòa nhà thực.
Trong bài viết này, chúng ta sẽ phân tích ba lớp AI đang hội tụ ngay bây giờ để tạo nên khả năng thấu hiểu không gian từ những bức ảnh bình thường.
Nút thắt gán nhãn 3D mà ít người nói đến
Tái tạo hình học 3D từ ảnh chụp, tại thời điểm này, là một vấn đề đã được giải quyết. Các quy trình Structure-from-Motion đã khớp các điểm chính và tam giác hóa các vị trí 3D hơn hai thập kỷ qua. Sự ra đời của các mô hình ước lượng độ sâu đơn mắt (monocular depth estimation) như Depth-Anything-3 có nghĩa là giờ đây bạn có thể tạo ra các đám mây điểm 3D dày đặc từ một video điện thoại thông minh mà không cần bất kỳ phần cứng chuyên biệt nào.
Hình học đã ở đó. Điều còn thiếu là ý nghĩa. Một đám mây điểm với 800.000 điểm nhưng không có nhãn dán là một hình ảnh trực quan đẹp đẽ nhưng không thể trả lời một câu hỏi thực tế nào. Bạn không thể hỏi nó "cho tôi xem các bức tường" hay "tính diện tích sàn nhà" hay "chọn mọi thứ trong phạm vi hai mét từ bảng điện".
Những truy vấn đó yêu cầu mọi điểm phải mang một nhãn ngữ nghĩa, và việc sản xuất các nhãn đó ở quy mô lớn vẫn cực kỳ tốn kém.
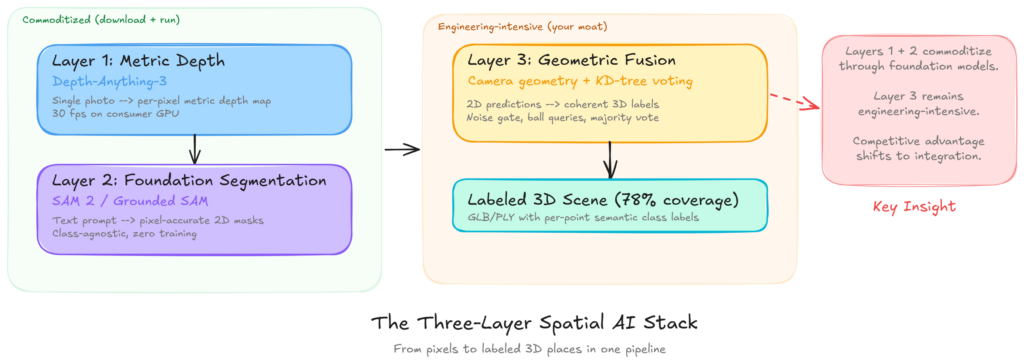
Ba lớp của Trí tuệ Không gian (Spatial AI) đang hội tụ thành một stack gán nhãn 3D duy nhất.
Ba lớp của Spatial AI đang hội tụ
Điều thú vị đã xảy ra giữa năm 2023 và 2025. Ba hướng nghiên cứu độc lập đã trưởng thành đến mức có thể xếp chồng lên nhau thành một quy trình duy nhất. Sự kết hợp này mạnh mẽ hơn bất kỳ cái nào riêng lẻ.
Lớp 1: Ước lượng độ sâu đo lường từ một bức ảnh đơn
Các mô hình như Depth-Anything và các phiên bản sau của nó (DA-V2, DA-3) lấy một bức ảnh đơn và dự đoán bản đồ độ sâu cho từng điểm ảnh.
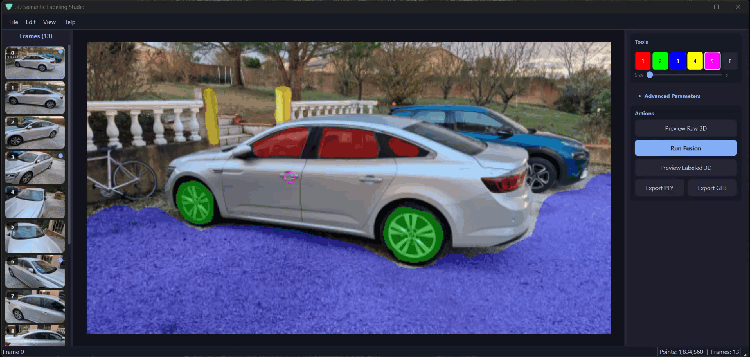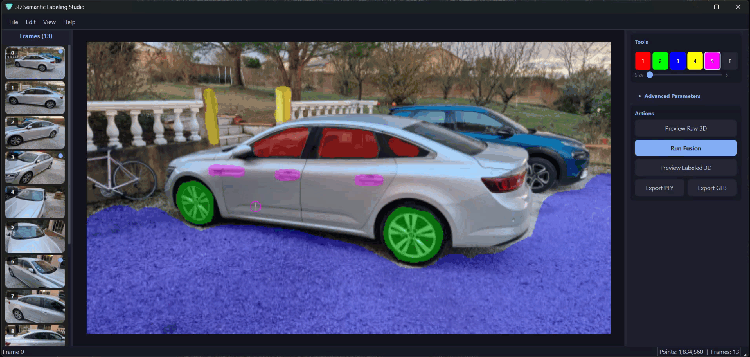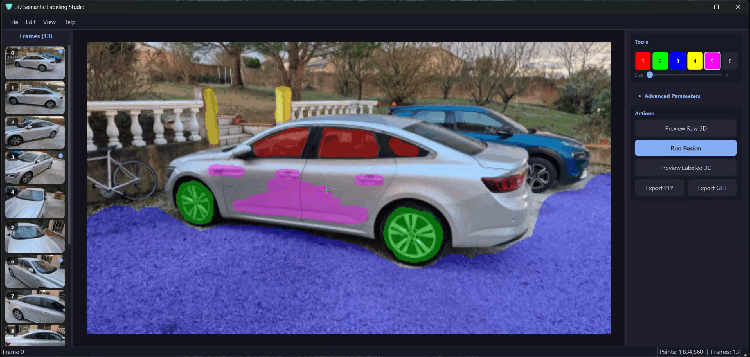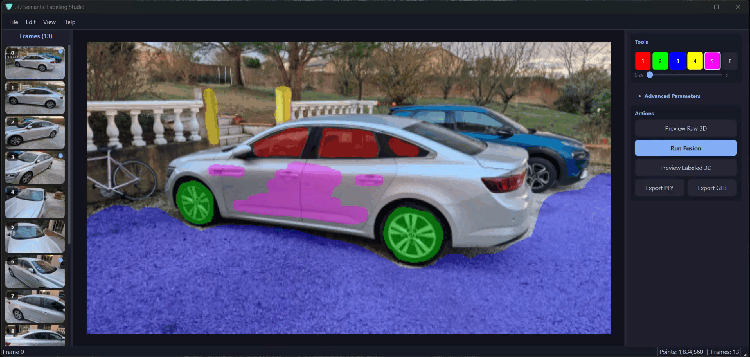 Bản đồ độ sâu
Bản đồ độ sâu
Bước đột phá chính không phải là dự đoán độ sâu (điều này đã tồn tại từ thời kỳ đầu của deep learning). Đó là sự chuyển dịch từ độ sâu tương đối sang độ sâu đo lường (metric depth). Độ sâu tương đối cho bạn biết bàn gần hơn tường, hữu ích cho chỉnh sửa ảnh nhưng vô dụng cho tái tạo 3D. Độ sâu đo lường cho bạn biết bàn cách 1,3 mét và tường cách 4,1 mét, nghĩa là bạn có thể đặt các bề mặt đó ở vị trí chính xác trong một hệ tọa độ.
Lớp 2: Phân đoạn nền tảng từ câu lệnh văn bản
Mô hình Segment Anything (SAM) và các phiên bản sau (SAM 2, Grounded SAM, FastSAM) có thể phân vùng bất kỳ hình ảnh nào thành các vùng nhất quán từ một cú nhấp chuột, một khung giới hạn hoặc một câu lệnh văn bản.
Các mô hình này không phụ thuộc vào lớp (class-agnostic) theo cách hữu ích nhất: chúng không cần nhìn thấy danh mục vật thể cụ thể của bạn trong quá trình huấn luyện. Bạn có thể chỉ vào một van công nghiệp, một dụng cụ phẫu thuật hoặc một món đồ chơi trẻ em, SAM sẽ tạo ra mặt nạ chính xác đến từng điểm ảnh.
Lớp 3: Hợp nhất hình học (Geometric Fusion)
Đây là nơi thách thức kỹ thuật thực sự nằm: hợp nhất hình học.
Thông số nội tại và ngoại tại của camera cung cấp cầu nối toán học giữa tọa độ ảnh 2D và tọa độ thế giới 3D. Nếu bạn biết tiêu cự của camera, vị trí và hướng từ đó mỗi bức ảnh được chụp, và độ sâu tại mỗi điểm ảnh, bạn có thể chiếu bất kỳ dự đoán 2D nào vào vị trí 3D chính xác của nó.
Lớp thứ ba là phần không ai tặng bạn miễn phí. Đó là vì nó yêu cầu sự hiểu biết về các mô hình camera, xử lý độ sâu nhiễu, giải quyết xung đột giữa các góc nhìn và lan truyền các dự đoán thưa thành độ phủ dày đặc. Đó là mô liên kết biến các dự đoán AI theo từng ảnh thành sự thấu hiểu 3D nhất quán.
Hợp nhất hình học biến pixel 2D thành địa điểm 3D được gán nhãn
Hoạt động trung tâm trong stack AI không gian là những gì tôi gọi là "cầu nối tính chiều": bạn thực hiện một nhiệm vụ ở chiều mà nó dễ nhất, sau đó chuyển kết quả sang chiều mà nó cần thiết.
Con người và mô hình AI đều nhanh và chính xác khi gán nhãn ảnh 2D. Gán nhãn đám mây điểm 3D thì chậm, tốn kém và dễ sai sót. Vì vậy, bạn gán nhãn trong 2D và chiếu sang 3D, sử dụng camera làm cầu nối.
Bản đồ độ sâu từ ước lượng đơn mắt không phải là sự thật mặt đất (ground truth). Chúng chứa lỗi tại ranh giới vật thể, trên bề mặt phản chiếu và trong các vùng không có kết cấu. Một mặt nạ chiếu ngược đơn lẻ sẽ đặt một số nhãn ở vị trí 3D sai. Và khi kết hợp các mặt nạ từ nhiều góc nhìn, các camera khác nhau sẽ không đồng thuận về nhãn nào thuộc về một điểm nhất định.
Đây là nơi thuật toán hợp nhất phát huy tác dụng.
Quy trình hợp nhất 4 giai đoạn để lan truyền nhãn 3D
Quy trình hợp nhất tôi đã tinh chỉnh qua một số dự án tuân theo bốn giai đoạn, mỗi giai đoạn giải quyết một chế độ thất bại cụ thể:
- Cổng nhiễu (Noise gate): Các điểm nằm xa bất kỳ vị trí camera nào có khả năng là tạo tác tái tạo. Bằng cách tính toán khoảng cách tối thiểu từ mỗi điểm đến camera gần nhất và loại bỏ nhãn vượt quá ngưỡng, bạn loại bỏ các lỗi đường dài.
- Chỉ mục không gian: Thay vì lập chỉ mục tất cả 800.000 điểm, thuật toán xây dựng một cây KD-tree chỉ sử dụng tập hợp con đã được gán nhãn. Điều này giảm kích thước cây 80% hoặc hơn.
- Xác định mục tiêu: Mọi điểm vẫn mang nhãn 0 sau cổng nhiễu trở thành ứng cử viên lan truyền. Trong một phiên điển hình với 5 góc nhìn, khoảng 20% cảnh nhận nhãn trực tiếp. Nghĩa là 80% điểm đang chờ bước bỏ phiếu.
- Bỏ phiếu dân chủ: Đối với mỗi điểm chưa gán nhãn, một truy vấn hình cầu (ball query) thu thập tất cả các hàng xóm đã gán nhãn trong bán kính tối đa. Nếu ít hơn số lượng hàng xóm tối thiểu các điểm đã gán nhãn nằm trong phạm vi, điểm đó vẫn chưa được gán nhãn (sự kiêng quyết ngăn chặn các phỏng đoán kém tự tin). Nếu không, nhãn phổ biến nhất sẽ thắng.
 Kết quả hợp nhất
Kết quả hợp nhất
Toàn bộ quá trình chạy trong dưới mười giây trên 800.000 điểm với CPU thông thường. Không cần GPU, không cần suy luận mô hình, không cần huấn luyện. Chỉ là hình học tính toán thuần túy.
Từ 20% lên 78% độ phủ nhãn: Hợp nhất hình học thực tế tạo ra gì
Khi bạn chiếu các dự đoán ngữ nghĩa từ năm trong số mười lăm bức ảnh vào 3D, khoảng 20% đám mây điểm nhận được nhãn trực tiếp. Độ phủ lốm đốm vì mỗi camera chỉ nhìn thấy một phần cảnh.
Sau khi quy trình hợp nhất chạy, độ phủ nhảy lên khoảng 78%. Sự mở rộng 3.5 lần đó đến hoàn toàn từ suy luận hình học trong bước bỏ phiếu truy vấn hình cầu.
Không cần thêm đầu vào của con người, không có suy luận mô hình nào xảy ra, không có thông tin mới nào nhập vào hệ thống. Thuật toán chỉ đơn giản là lan truyền các nhãn hiện có sang các điểm chưa gán nhãn gần đó bằng sự gần gũi không gian và đồng thuận dân chủ.
Lớp hợp nhất hình học hoạt động như một bộ khuếch đại nhãn. Bất kỳ dự đoán ngược dòng nào, dù đến từ con người, từ SAM hay từ một mô hình được kích hoạt bằng văn bản trong tương lai, đều được khuếch đại bởi cùng một hệ số.
Vấn đề còn mở trong AI không gian
Các mô hình nền tảng tạo ra dự đoán độc lập cho từng hình ảnh. SAM không biết nó đã phân đoạn gì trong khung hình trước đó. Depth-Anything-3 không thực thi tính nhất quán giữa các góc nhìn.
Khi bạn chiếu các dự đoán theo từng ảnh này vào 3D, chúng đôi khi không đồng thuận. Một camera có thể gán nhãn một vùng là "tường" trong khi một cái khác gán các điểm chồng chéo là "trần", không phải vì dự đoán nào sai trong 2D, mà vì ranh giới lớp trông khác nhau từ các góc độ khác nhau.
Lớp hợp nhất giải quyết một phần các bất đồng này thông qua bỏ phiếu đa số. Nhưng tại các ranh giới lớp thực sự (nơi tường gặp trần), việc bỏ phiếu trở thành một trò tung đồng xu.
Biên giới tiếp theo là tính nhất quán đa góc nhìn (multi-view consistency): làm cho các mô hình ngược dòng nhận thức về dự đoán của nhau trước khi chúng đến lớp hợp nhất. Một hệ thống cung cấp kết quả hợp nhất 3D ngược lại vào vòng lặp dự đoán 2D (sửa chữa mặt nạ theo từng ảnh dựa trên đồng thuận 3D mới nổi) sẽ đóng vòng lặp hoàn toàn.
Trong 12 đến 18 tháng tới, chúng ta có thể mong đợi việc ước lượng độ sâu trên thiết bị đủ chính xác cho AI không gian, các mô hình SAM 3 với nhận thức đa góc nhìn nguyên bản, và việc phát trực tiếp ngữ nghĩa 3D theo thời gian thực.
Nút thắt sẽ chuyển từ việc sản xuất nhãn sang việc kiểm soát chất lượng chúng, một vấn đề tốt hơn nhiều để giải quyết.
Bài viết liên quan

Công nghệ
Các tác nhân AI đã khiến thế giới công nghệ chao đảo: Câu chuyện đằng sau cuộc cách mạng Claude Code và OpenClaw
26 tháng 5, 2026

Công nghệ
Alienware 15 mới: Dell đang làm loãng thương hiệu cao cấp vì khủng hoảng RAM?
14 tháng 5, 2026

Công nghệ
Pinterest áp dụng "vân tay nội dung" để loại bỏ URL trùng lặp trên hàng triệu tên miền
08 tháng 6, 2026