
Các bộ dữ liệu "tồi tệ" chứa ảnh minh tinh đang được dùng để huấn luyện mô hình y khoa AI
Các nhà nghiên cứu đã phát hiện những bộ dữ liệu chẩn đoán đột quỵ và tiểu đường trên nền tảng Kaggle chứa đầy lỗi nghiêm trọng, thậm chí xuất hiện cả hình ảnh của minh tinh như Sylvester Stallone. Vấn nạn dữ liệu kém chất lượng và thiếu nguồn gốc rõ ràng này đang đe dọa tính toàn vẹn của nhiều nghiên cứu trí tuệ nhân tạo trong lĩnh vực y tế.
Các bộ dữ liệu "tồi tệ" chứa ảnh minh tinh đang được dùng để huấn luyện mô hình y khoa AI
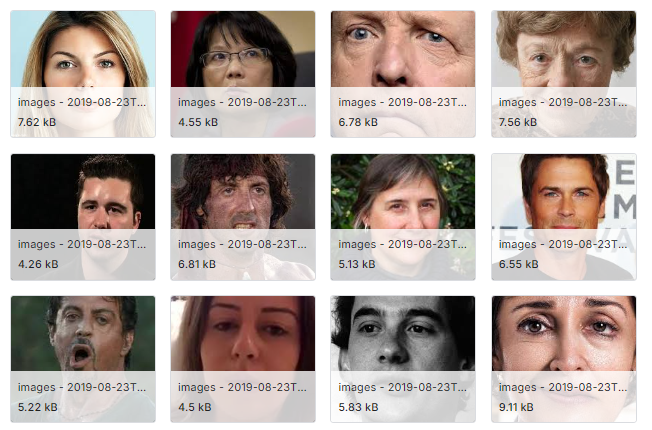
Một bộ dữ liệu trên nền tảng Kaggle được cho là chứa hình ảnh của những người bị đột quỵ thực tế lại bất ngờ xuất hiện hình ảnh của nam diễn viên Sylvester Stallone trong vai Rambo cùng nhiều người nổi tiếng khác. Đây là phát hiện gây chấn động cho thấy chất lượng dữ liệu thấp kém đang ảnh hưởng đến các nghiên cứu y khoa nghiêm túc.
Khi lướt qua một bộ dữ liệu hình ảnh trực tuyến, Adrian Barnett, một nhà thống kê tại Đại học Công nghệ Queensland (Úc), đã nhận ra những gương mặt quen thuộc. Không chỉ có Sylvester Stallone trong bộ phim hành động, mà còn có George Clooney, Angelina Jolie và Daniel Craig xuất hiện lặp đi lặp lại. "Điều này thật nực cười," Barnett nhận định. "Đây rõ ràng là một bộ dữ liệu tồi tệ đến mức hài hước."
Ảnh chụp màn hình bộ dữ liệu trên Kaggle
Vấn đề cốt lõi trong nghiên cứu AI y tế
Bộ dữ liệu cụ thể này, được lưu trữ trong một thư mục mang tên "droopy" trên kho lưu trữ mã nguồn mở Kaggle (thuộc sở hữu của Google), đã được sử dụng làm nền tảng cho một bài báo đăng trên tạp chí Scientific Reports. Thay vì được dùng cho trò chơi tìm người nổi tiếng, nó được sử dụng làm tập huấn luyện cho mô hình lâm sàng dự đoán nhằm phát hiện sớm đột quỵ.
Bài báo này là ví dụ mới nhất cho một vấn đề rộng lớn hơn mà Barnett và sinh viên tiến sĩ Alexander Gibson đã tài liệu hóa về Kaggle. Nền tảng này lưu trữ các bộ dữ liệu do người dùng tải lên, mà các nhà nghiên cứu và chuyên gia máy học sử dụng để xây dựng các mô hình dự đoán. Bằng cách kiểm tra hai bộ dữ liệu khác trên Kaggle về đột quỵ và tiểu đường (chứa dữ liệu dạng bảng của bệnh nhân), Gibson và Barnett đã truy xuất cách dữ liệu này di chuyển qua các tài liệu khoa học và trong một số trường hợp, được đưa vào ứng dụng lâm sàng thực tế.
Công trình của họ, được mô tả trong một bản in trước (preprint) đăng trên medRxiv vào tháng 2, đã dẫn đến việc rút lại nhiều bài báo khoa học sử dụng các bộ dữ liệu đáng ngờ này.
Những sai phạm nghiêm trọng trong dữ liệu
Sau khi rà soát qua vô số bộ dữ liệu đáng ngờ, Gibson cho biết bài báo trên Scientific Reports rất dễ tìm thấy. "Tôi chỉ tìm kiếm 'Kaggle' và 'đột quỵ' trên Google Scholar," Gibson nói. "Đây chỉ là một trong những kết quả đầu tiên hiện ra." Bài báo, được xuất bản vào tháng 12, sử dụng hai bộ dữ liệu được cho là hiển thị hình ảnh của những người bị đột quỵ để huấn luyện mô hình phát hiện đột quỵ theo thời gian thực và tạo điều kiện cho "can thiệp lâm sàng nhanh chóng".
Trong bộ dữ liệu "droopy" vẫn còn trực tuyến, Barnett và Gibson đã phát hiện thông qua tìm kiếm hình ảnh ngược rằng nhiều hình ảnh thực chất mô tả chứng liệt mặt (Bell's palsy), bên cạnh hình ảnh trẻ sơ sinh và... người nổi tiếng. Trên Kaggle, người tạo bộ dữ liệu tuyên bố nó chứa 1024 hình ảnh của "các bệnh nhân khác nhau", bất chấp sự trùng lặp rõ ràng, và khẳng định nó phục vụ mục đích giáo dục.
"Rõ ràng điều này không phù hợp cho nghiên cứu nghiêm túc, về mặt đạo đức và khoa học đều không phù hợp," Barnett nhận định. "Không có lý do gì để sử dụng nó nếu thực hiện các kiểm tra cơ bản."
Hậu quả và sự "rửa tiền" học thuật
Sau khi tiếp xúc với Springer Nature, tạp chí đã thêm một ghi chú của biên tập viên lên bài báo để cảnh báo độc giả về những lo ngại liên quan đến độ tin cậy của dữ liệu. Tuy nhiên, thiệt hại đã lan rộng. Gibson và Barnett đã xác định được 124 bài báo đã xuất bản xây dựng các mô hình dựa trên các bộ dữ liệu đột quỵ và tiểu đường đáng ngờ này. Cả hai bộ dữ liệu đều không vượt qua được danh sách kiểm tra về nguồn gốc dữ liệu (ai, khi nào, ở đâu và tại sao).
Bất kỳ ai thực hiện các kiểm tra cơ bản cũng sẽ thấy ngay lập tức rằng dữ liệu này không giống dữ liệu thật. Các phát hiện chi tiết rằng các bộ dữ liệu chứa hàng nghìn quan sát bệnh nhân trùng lặp và rất ít giá trị bị thiếu — điều này rất khó xảy ra trong dữ liệu bệnh nhân thực tế.
Khi Gibson và Barnett nêu lên những lo ngại này trên PubPeer, một tác giả của bài báo sử dụng dữ liệu Kaggle đã phản hồi bằng cách trích dẫn 25 bài báo khác cũng đã sử dụng cùng một bộ dữ liệu đó. Naeem Ramzan, tác giả chính, đã viết: "Sự hiện diện liên tục của nó trong các tài liệu hiện tại cho thấy nó vẫn là một tài nguyên được chấp nhận phổ biến để đánh giá thực nghiệm trong lĩnh vực nghiên cứu này."
Barnett gọi đây là hiệu ứng "rửa tiền" (laundering effect). Khi các bài báo này xuất hiện trong một phân tích tổng hợp (meta-analysis), rất ít người quay lại kiểm tra nguồn gốc ban đầu.
Kêu gọi hành động và trách nhiệm của các nền tảng
Hầu hết các nghiên cứu bị gắn cờ trong bản in trước đều đưa ra các đề xuất thực tế về việc sử dụng các mô hình này trên bệnh nhân, và phần lớn không có tuyên bố đạo đức. Ít nhất hai mô hình có trang web công khai, và một mô hình được liên kết với bằng sáng chế thiết bị y tế đăng ký bởi Viện Công nghệ California và Đại học Nam California.
Ben Van Calster, một nhà thống kê sinh học tại KU Leuven, người đã giúp phát triển các hướng dẫn về nguồn gốc dữ liệu, cho biết các phát hiện này không gây ngạc nhiên. "Các kho lưu trữ không thể thực sự kiểm soát liệu mọi người có sử dụng dữ liệu này đúng cách hay không," ông nói. "Tôi nghĩ các kho lưu trữ nên cải thiện tài liệu của họ."
Một người phát ngôn của Kaggle cho biết nền tảng này dựa vào việc cộng đồng tự báo cáo siêu dữ liệu và nguồn gốc. Việc sử dụng dữ liệu tổng hợp (synthetic data) trên Kaggle là "hoàn toàn hợp pháp", nhưng "các bộ dữ liệu này dành cho điểm chuẩn và phát triển — không phải bằng chứng chính cho nghiên cứu y tế hoặc ra quyết định".
Gibson nói danh sách các bộ dữ liệu đáng ngờ của anh ấy tiếp tục tăng lên. "Rất đơn giản," Gibson kết luận. "Bạn quan tâm đến bệnh nhân hay một bài báo khoa học?"


