
Cách chọn số lượng Bin tối ưu cho Histogram bằng phương pháp Bayesian
Bài viết này khám phá cách tiếp cận toán học nghiêm ngặt để xác định độ phân giải tối ưu cho biểu đồ Histogram thông qua lý thuyết Bayesian. Phương pháp này giúp cân bằng giữa độ chính xác và độ phức tạp của mô hình, tránh tình trạng quá khớp và mang lại cái nhìn trung thực hơn về mật độ dữ liệu.
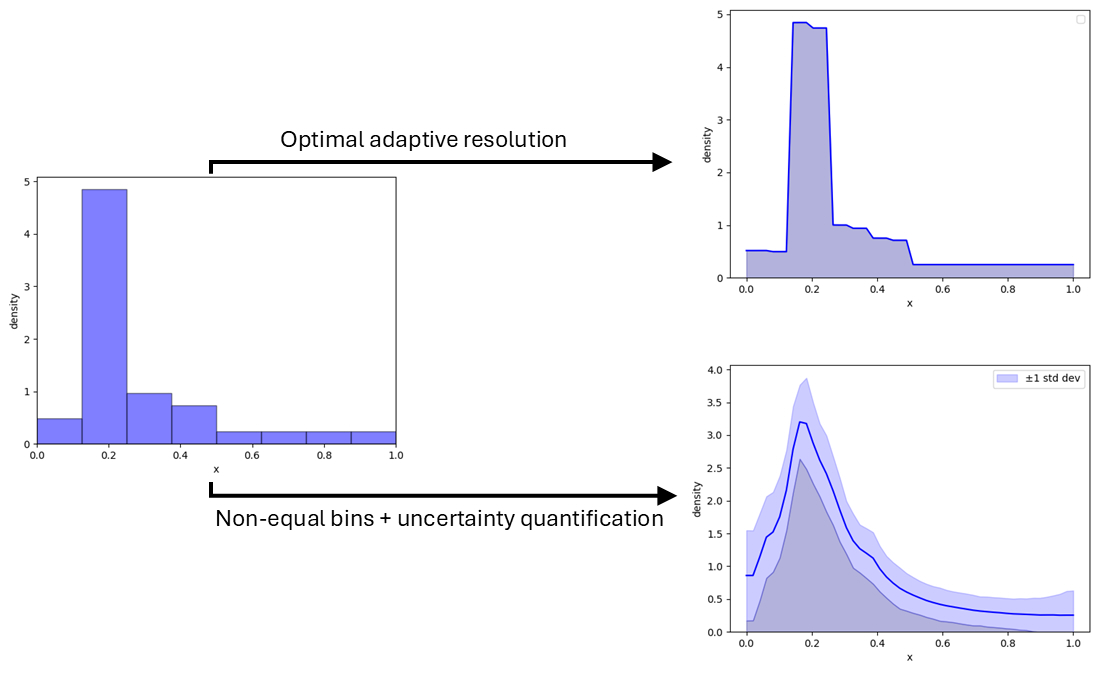
Histogram là công cụ cơ bản nhất để trực quan hóa dữ liệu, nhưng việc chọn số lượng bin (khoảng chia) luôn là một bài toán khó. Liệu có cách nào để xác định độ phân giải này một cách toán học thay vì chỉ dựa vào cảm giác "trông đẹp mắt"?
Bài viết này sẽ đi sâu vào toán học của việc ước tính mật độ (density fitting), sử dụng phương pháp Bayesian để tìm ra số lượng bin tối ưu. Cách tiếp cận này không chỉ giúp biểu đồ của bạn trông chuyên nghiệp hơn mà còn đảm bảo tính chính xác khi sử dụng dữ liệu đó cho các phân tích sâu hơn.
Tại sao việc chọn Bin lại quan trọng?
Trực giác của chúng ta thường mách bảo: dữ liệu càng nhiều, chi tiết càng nên cao. Nếu bạn chỉ có 10 quan sát, 2-3 bin rộng là hợp lý. Nhưng với 10 triệu quan sát, những bin rộng đó sẽ khiến biểu đồ của bạn trông giống như một bức ảnh độ phân giải thấp, bị "pixel hóa".
 Dữ liệu mẫu
Dữ liệu mẫu
Vấn đề cốt lõi là làm thế nào để масштаб hóa (scale) độ phân giải này một cách chính xác. Trong vật lý, chúng ta có Lý thuyết nhiễu loạn (Perturbation Theory) để giải quyết các hệ phức tạp. Trong toán học, có Chuỗi Taylor (Taylor Expansion). Tuy nhiên, đối với histogram, chúng ta cần một tham số cơ bản điều chỉnh sự tương tác giữa các điểm dữ liệu rời rạc và phân phối cơ bản mà chúng ta đang cố gắng ước tính.
Cách tiếp cận Bayesian: Cân bằng giữa Độ chính xác và Độ phức tạp
Trong thống kê Bayesian, một mô hình không chỉ được đánh giá bằng độ chính xác mà còn phải chịu hình phạt vì sự phức tạp. Chất lượng của một mô hình có thể được tính toán thông qua độ "ngạc nhiên" (surprisal):
log P(X|M) = -surprisal = độ chính xác – độ phức tạp
Các mô hình có quá nhiều tham số (ví dụ: quá nhiều bin) có thể đạt độ chính xác cao trên dữ liệu huấn luyện, nhưng sẽ bị "giết chết" bởi hình phạt của độ phức tạp. Mô hình lý tưởng không phải là chi tiết nhất, mà là mô hình nắm bắt nhiều thông tin nhất với ít "gánh nặng" không cần thiết nhất.
Mô hình hóa Histogram dưới góc độ Bayesian
Để xử lý mật độ như một mô hình hình thức, chúng ta coi mỗi bin trong số K bin là một tham số. Cụ thể, chúng ta gán một trọng số w_k cho mỗi bin, đại diện cho xác suất một điểm dữ liệu rơi vào khoảng đó. Vì tổng xác suất phải bằng 1, một mật độ với K bin được định nghĩa bởi K-1 tham số độc lập.
Trong khung Bayesian, chúng ta cần gán một prior (phân phối tiên nghiệm) cho các trọng số này. Phân phối Dirichlet là lựa chọn tự nhiên nhất. Đối với việc xây dựng một mật độ chuẩn, việc chọn siêu tham số $\alpha = 1$ (prior phẳng hoặc Laplace) thường là tự nhiên nhất. Nó phản ánh một điểm khởi đầu trung lập, nơi chúng ta giả định dữ liệu được phân phối đồng đều trên khoảng đó cho đến khi bằng chứng chứng minh điều ngược lại.
Trọng số mô hình thay vì chọn "Kẻ chiến thắng"
Khi xem xét một tập hợp các mô hình (ví dụ: histogram với 1, 2, 4, 8... bin), rất dễ dàng để chỉ chọn mô hình có xác suất cao nhất và tiếp tục. Tuy nhiên, cách tiếp cận "người chiến thắng lấy tất cả" này mang lại rủi ro:
- Biến động thống kê: Dữ liệu có thể chứa một sự cố ngẫu nhiên khiến một mô hình kém tối ưu trông có vẻ vượt trội tạm thời.
- Trọng số của đám đông: Đôi khi, tổng của nhiều mô hình "ít khả năng" hơn thực sự vượt quá xác suất của một mô hình "tốt nhất" duy nhất.
Do đó, một cách tiếp cận mạnh mẽ hơn là giữ tất cả các mô hình, có trọng số theo xác suất của chúng. Điều này không phải là sự "pha trộn" các sự thật khác nhau; chúng ta vẫn giả định chỉ có một mô hình là đúng, nhưng chúng ta sử dụng toàn bộ phân phối các khả năng để tính đến sự không chắc chắn của chính mình.
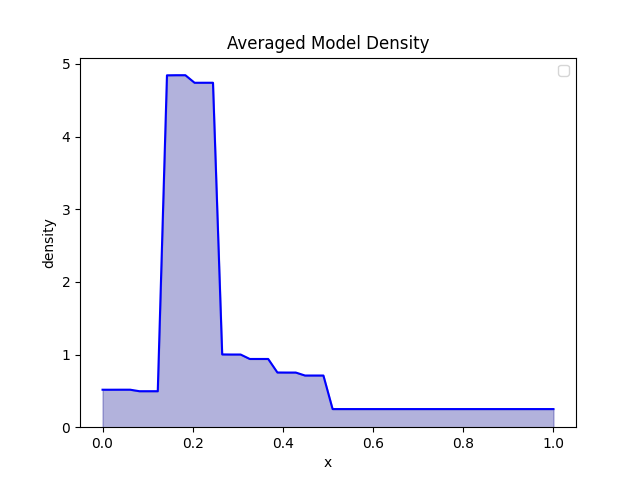 Kết quả mô hình hóa với các số lượng bin khác nhau
Kết quả mô hình hóa với các số lượng bin khác nhau
Kết quả: Histogram mượt mà hơn
Bằng cách sử dụng phương pháp Bayesian, chúng ta có thể kết hợp các mật độ từ các độ phân giải khác nhau. Thay vì chọn một số bin cố định (ví dụ: 8 bin), việc lấy tổng có trọng số trên tất cả các mô hình sẽ tạo ra một biểu đồ mượt mà và trung thực hơn.
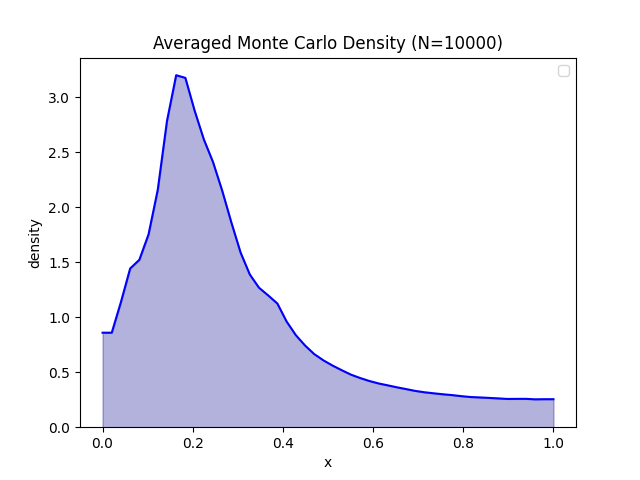 Histogram mượt mà sau khi áp dụng trọng số mô hình
Histogram mượt mà sau khi áp dụng trọng số mô hình
Hơn nữa, phương pháp này cũng cho phép chúng ta sử dụng các bin không đều nhau hoặc trực quan hóa sự không chắc chắn (uncertainty) thông qua các thanh sai số (error bars), cung cấp cái nhìn sâu sắc hơn về độ tin cậy của ước tính mật độ.
Kết luận
Chúng ta đã bắt đầu với một câu hỏi đơn giản: Có nền tảng toán học nào cho việc chọn bin trong histogram không? Câu trả lời nằm ở cách tiếp cận Bayesian.
- Trọng số mô hình cho phép chúng ta kết hợp nhiều độ phân giải, cung cấp sự trình bày dữ liệu mượt mà và trung thực hơn.
- Dirichlet Priors cung cấp một cách nghiêm ngặt để diễn đạt các giả định ban đầu của chúng ta về phân phối dữ liệu.
Giống như lý thuyết nhiễu loạn cung cấp một hệ phân cấp cho các tương tác vật lý, khung Bayesian này cung cấp một hệ phân cấp cho độ phân giải dữ liệu. Độ phân giải sẽ mở rộng tự nhiên khi có nhiều dữ liệu hơn, giúp các nhà khoa học dữ liệu tránh được bẫy quá khớp (overfitting) và tối ưu hóa việc trực quan hóa thông tin.
Bài viết liên quan

Công nghệ
Bị AI từ chối hồ sơ xin việc? Cuộc chiến đơn độc của một sinh viên y khoa
05 tháng 5, 2026
Công nghệ
Chủ đề từ LLM không phải là dữ liệu quan sát: Cảnh báo cho các nhà phân tích dữ liệu
21 tháng 5, 2026
Công nghệ
Thử nghiệm thú vị: Tại sao mọi mô hình AI hàng đầu đều có cùng tính cách INTJ?
25 tháng 5, 2026