
Chronos-2: Mô hình nền tảng chuỗi thời gian mới từ AWS và những điều cần biết
Bài viết khám phá Chronos-2, mô hình nền tảng chuỗi thời gian (TSFM) mới nhất từ AWS. Chúng ta sẽ đi sâu vào khả năng dự báo đa biến, sử dụng biến đồng thời và xử lý tình huống "cold-start" mà không cần huấn luyện lại.

Các mô hình nền tảng (Foundation Models) hiện nay đã trở nên phổ biến. Chúng ta từng thấy chúng xuất hiện trong lĩnh vực ngôn ngữ (LLM), sau đó là thị giác máy tính (Computer Vision), và giờ đây cả video và giọng nói. Công thức chung bây giờ đã quen thuộc: trước tiên, huấn luyện trước (pretrain) một mạng nơ-ron lớn trên đủ lượng dữ liệu, sau đó áp dụng mô hình cho các nhiệm vụ hạ nguồn mà không cần thích ứng cho từng nhiệm vụ cụ thể.
Đối với nhiều ứng dụng công nghiệp, chuỗi thời gian (time series) là một dạng dữ liệu quan trọng. Chúng ta thường xuyên cần thực hiện dự báo, phát hiện bất thường và phân loại bằng cách sử dụng các loại dữ liệu ghi nhận khác nhau. Thực tế hiện nay thường là xây dựng các mô hình chuyên dụng cho một vấn đề cụ thể. Cách tiếp cận này có thể hoạt động, nhưng nó liên quan đến việc "phát minh lại bánh xe", và có thể mang lại hiệu suất dưới tối ưu nếu tập dữ liệu cho vấn đề hiện tại quá nhỏ.
Tự nhiên, chúng ta muốn đặt câu hỏi: liệu chúng ta có thể áp dụng công thức tương tự ở đây không, tức là huấn luyện trước một mô hình nền tảng chuỗi thời gian lớn và sử dụng nó cho bất kỳ nhiệm vụ hạ nguồn nào ngay lập tức?
Đó là cược đặt đằng sau các mô hình nền tảng chuỗi thời gian, hay còn gọi là TSFMs. Trong bài viết này, chúng ta sẽ cùng tìm hiểu Chronos-2, mô hình mới nhất trong dòng Chronos được AWS phát hành vào tháng 10 năm 2025.
Mô hình nền tảng chuỗi thời gian thay đổi quy trình phân tích như thế nào?
Như tên gọi của nó, một TSFM là một mạng nơ-ron duy nhất được huấn luyện trước trên một tập hợp lớn và đa dạng các chuỗi thời gian. Lời hứa của nó giống như các LLM đối với văn bản: thay vì huấn luyện một mô hình mới mỗi khi một vấn đề dự báo mới xuất hiện, bạn chỉ cần tải một mô hình đã huấn luyện trước và yêu cầu nó dự báo.
Đây là một sự thay đổi lớn trong quy trình làm việc.
Giả sử chúng ta muốn thực hiện dự báo nhu cầu năng lượng hàng tuần cho các tòa nhà. Nếu tuân theo quy trình truyền thống, chúng ta sẽ bắt đầu bằng việc chuẩn bị dữ liệu, sau đó chọn các mô hình dự báo như ARIMA, gradient-boosted trees, LSTM, TCN, N-BEATS... và sau đó dành phần lớn thời gian dự án để huấn luyện, tinh chỉnh siêu tham số và xác thực. Kết quả là một mô hình giải quyết một vấn đề này trên một tập dữ liệu này.
Sáu tháng sau, một nhiệm vụ dự báo mới xuất hiện, và chu trình bắt đầu lại từ đầu.
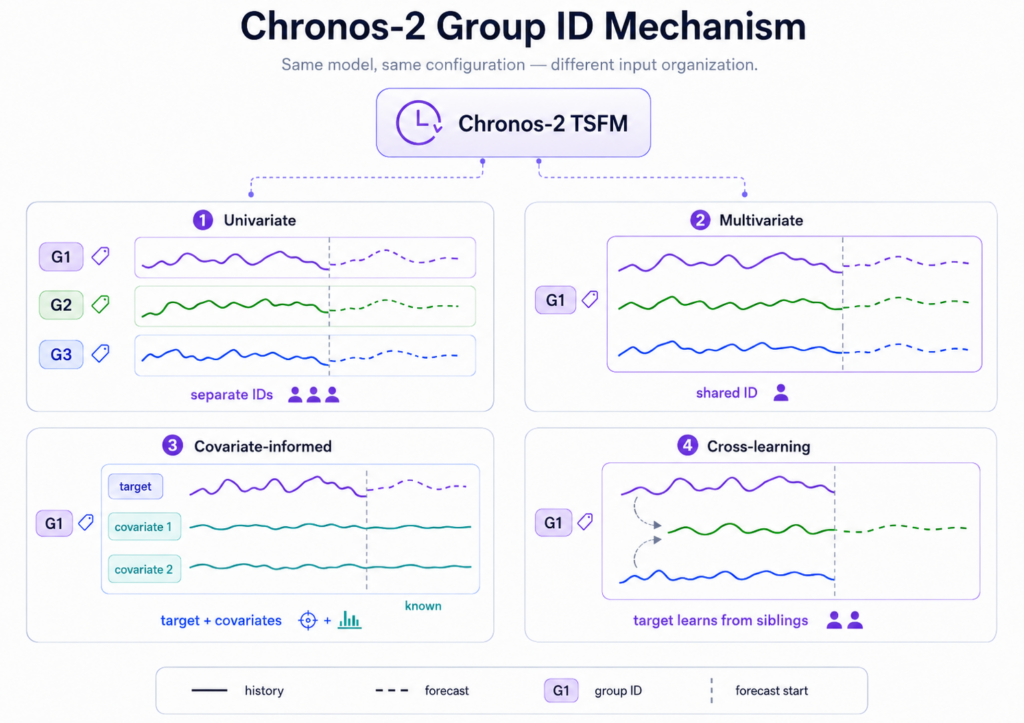 Cơ chế Group ID trong Chronos-2
Cơ chế Group ID trong Chronos-2
Với TSFM, hầu hết những gì tôi mô tả ở trên được nén vào một lệnh suy luận (inference) duy nhất. Quy trình giờ đây trở thành: Lấy chuỗi lịch sử (nếu có, cả các biến đồng thời liên quan), đưa vào TSFM đã huấn luyện trước, đặt chân trời dự báo mong muốn, sau đó chạy suy luận TSFM và nhận về dự báo.
Điều thú vị là bạn không chỉ nhận được một dự báo điểm (point forecast), mà thường là các phân vị dự báo (predictive quantiles) để định lượng sự không chắc chắn.
Điều này ngụ ý rằng chi phí để thử nghiệm một dự báo giảm đi rất nhiều. Nếu nó hoạt động, tuyệt vời. Nếu không, bạn đã học được điều gì đó hữu ích chỉ trong mười phút. Hơn nữa, vấn đề "khởi động nguội" (cold-start) không còn là rào cản lớn. Với một mô hình đã huấn luyện trước, lượng dữ liệu "ít ỏi" đó có thể đủ để mang lại kết quả có ý nghĩa.
Tại sao mô hình nền tảng lại hoạt động với chuỗi thời gian?
"Tôi không tin vào TSFM. Điều này không nên hoạt động."
Đó là điều tôi nghe thấy nhiều nhất từ các đồng nghiệp, và sự hoài nghi đó là hợp lý. Ngôn ngữ bị giới hạn và có từ vựng hữu hạn. Con số thì không như vậy. Con số là liên tục, và ý nghĩa của chúng có thể thay đổi rất nhiều tùy theo ngữ cảnh. Một con số "100" trong nhu cầu bán lẻ sẽ có ý nghĩa rất khác so với một "100" trong biểu đồ nhịp tim.
Tại sao chúng ta lại hy vọng một mô hình đã huấn luyện trước có thể hoạt động trên các ngữ cảnh khác nhau?
Thực tế, mô hình không thực sự học dữ liệu cụ thể của bạn; nó học các hình dạng (shapes) như chu kỳ, xu hướng, sự thay đổi mức độ, các đỉnh nhọn lặp lại... và những hình dạng này lặp lại trên các chuỗi thời gian của nhiều lĩnh vực khác nhau. Những hình dạng này chính là "từ vựng" ở đây. Một mô hình đã thấy đủ các hình dạng này ở đủ quy mô và tần số có thể hy vọng nhận ra chúng trong chuỗi dữ liệu của bạn, ngay cả khi nó chưa từng thấy hoặc được huấn luyện trên chuỗi của bạn trước đó.
Chronos-2 cụ thể là gì?
Chronos-2 là một Transformer chỉ có bộ mã hóa (encoder-only) với 120 triệu tham số, khá nhỏ nếu so với tiêu chuẩn LLM ngày nay. Một số lựa chọn thiết kế nổi bật:
- Nhúng bản vá liên tục (Continuous patch embeddings): Khác với Chronos gốc sử dụng từ vựng rời rạc, Chronos-2 nhóm các quan sát liên tiếp thành một "bản vá" và nhúng toàn bộ bản vá đó dưới dạng một vectơ liên tục. Điều này giúp mô hình xử lý ít mục hơn mỗi chuỗi, dẫn đến suy luận nhanh hơn và không mất độ chính xác do lượng tử hóa.
- Cơ chế chú ý kép: Chronos-2 có hai loại chú ý: chú ý thời gian (time attention) và chú ý nhóm (group attention), thay thế nhau ở mỗi lớp. Chú ý thời gian giúp mỗi chuỗi chú ý vào quá khứ của chính nó, trong khi chú ý nhóm hoạt động trên các chuỗi cùng nhóm ID.
- Hồi quy phân vị trực tiếp: Thay vì tạo token tự hồi quy, Chronos-2 sử dụng đầu hồi quy xuất ra tất cả 21 mức dự báo phân vị cho tất cả các bước trong chân trời dự báo cùng một lúc.
Về dữ liệu huấn luyện, Chronos-2 dựa nhiều vào dữ liệu tổng hợp (synthetic data) từ các trình tạo như Gaussian-process curves, kết hợp ngẫu nhiên của xu hướng/mùa vụ... Một phát hiện đáng chú ý là một biến thể chỉ được huấn luyện trên dữ liệu tổng hợp hoạt động chỉ kém hơn một chút so với mô hình cuối cùng.
Khám phá khả năng của Chronos-2 qua một nghiên cứu tình huống
Chúng ta hãy cùng thực hiện một nghiên cứu tình huống nhỏ với vấn đề dự báo nhu cầu điện tiêu thụ của tòa nhà. Cụ thể, chúng ta muốn dự báo nhu cầu điện theo giờ cho một tuần tới. Đối với hầu hết các tòa nhà, chúng ta có 45 ngày dữ liệu ghi nhận gần đây. Đối với một tòa nhà mới được đưa vào hoạt động, chỉ có vài ngày dữ liệu. Điều này cho phép chúng ta kiểm tra cài đặt cold-start.
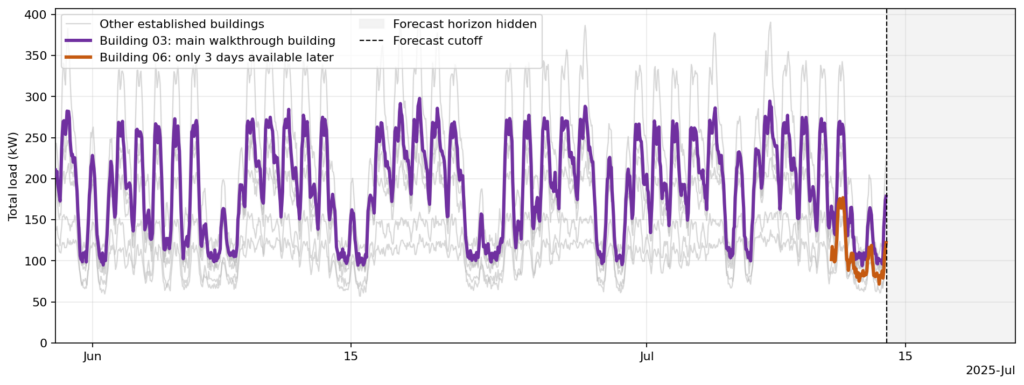 Thiết lập nghiên cứu tình huống
Thiết lập nghiên cứu tình huống
Dự báo đơn biến (Univariate)
Chúng ta bắt đầu với thiết lập đơn giản nhất: đưa lịch sử nhu cầu của từng tòa nhà cho Chronos-2 và yêu cầu dự báo một tuần tới. Kết quả cho thấy Chronos-2 có thể thực hiện dự báo zero-shot khá tốt, nắm bắt được các chu kỳ hàng ngày và hàng tuần mà không cần tinh chỉnh.
Dự báo đa biến (Multivariate)
Ở đây, chúng ta dự báo nhiều mục tiêu cùng một lúc (ví dụ: tổng tải, tải HVAC, tải đèn, tải cắm) vì chúng có thể di chuyển cùng nhau hoặc chúng muốn các dự báo của chúng được thông báo lẫn nhau. Bằng cách cung cấp cùng một nhóm ID cho tất cả các chuỗi liên quan, Chronos-2 có thể tận dụng mối quan hệ giữa các thành phần tải khác nhau để cải thiện độ chính xác.
Dự báo có biến đồng thời (Covariate-informed)
Đây là khi bạn có các chuỗi bổ sung ảnh hưởng đến mục tiêu của bạn, chẳng hạn như nhiệt độ ngoài trời. Để thực hiện dự báo này, bạn cần gán mục tiêu và các biến đồng thời của nó vào cùng một nhóm ID, với mục tiêu được xác định là chuỗi cần dự báo và các chuỗi khác được cung cấp làm ngữ cảnh đã biết.
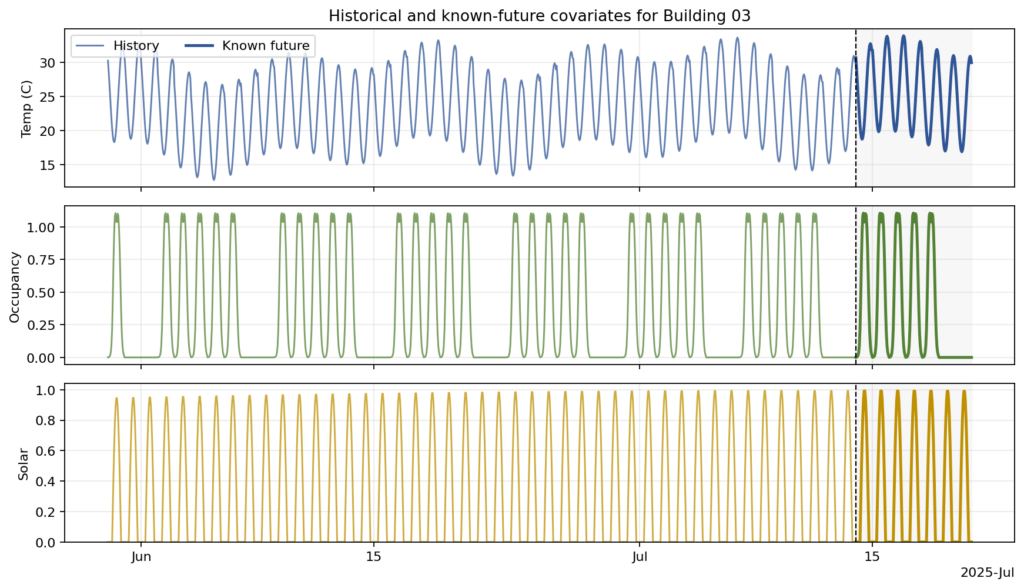 Dự báo có biến đồng thời
Dự báo có biến đồng thời
Học chéo (Cross-learning) và Cold-start
Đây là phần thú vị nhất. Chúng ta có một tòa nhà mới (Building 06) chỉ có 3 ngày dữ liệu. Nếu sử dụng riêng biệt (isolated), dự báo sẽ kém chính xác. Tuy nhiên, khi kích hoạt "cross-learning" và cung cấp dữ liệu của 7 tòa nhà khác cùng nhóm, Chronos-2 có thể học các hình dạng ngày trong tuần/nhật cuối tuần và độ lớn đỉnh từ các tòa nhà khác, áp dụng cho tòa nhà mới.
Kết quả cho thấy chiến lược cross-learning giúp giảm WAPE (Weighted Absolute Percentage Error) từ 22,2% xuống còn 16,7%. Mô hình thực hiện "học trong ngữ cảnh" (in-context learning): nó nhìn thấy bảy tòa nhà trong danh mục đầu tư này, sau đó đối chiếu các mẫu của Building 06 và dự báo tương ứng.
Khi nào Zero-shot không còn đủ?
Trước khi quá hào hứng với các khả năng mới của Chronos-2, chúng ta cần nhớ rằng: Zero-shot là một mặc định tuyệt vời, nhưng không phải là câu trả lời phổ quát.
Zero-shot có thể không đủ khi:
- Dữ liệu của bạn trông không giống bất cứ thứ gì trong hỗn hợp huấn luyện trước (ví dụ: tín hiệu khoa học chuyên biệt).
- Bạn có nhiều lịch sử sạch nhưng không được sử dụng (Chronos-2 chỉ chú ý đến cửa sổ ngữ cảnh tối đa 8192 bước).
- Bạn thấy các lỗi hệ thống mà mô hình liên tục mắc phải.
- Bạn cần hành vi mà mục tiêu zero-shot không tối ưu hóa (ví dụ: chi phí dự báo thấp quá tốn kém hơn nhiều so với dự báo cao quá).
Trong những trường hợp này, tinh chỉnh (fine-tuning) sẽ là giải pháp, mà chúng ta sẽ đề cập trong phần tiếp theo.
Bài viết liên quan

Công nghệ
Sự trở lại của Xbox: Chiến lược mới, thay đổi nhân sự và tương lai Project Helix
07 tháng 5, 2026

Công nghệ
Samsung Galaxy Book6 Ultra: Bản sao MacBook Pro đắt đỏ nhưng đầy khiếm khuyết
07 tháng 5, 2026

Công nghệ
Tạm biệt "Ferrynoia": Công nghệ hàng hải xanh đang thay đổi ngành vận tải thủy
05 tháng 6, 2026