
Chủ đề từ LLM không phải là dữ liệu quan sát: Cảnh báo cho các nhà phân tích dữ liệu
Bài viết cảnh báo các chuyên gia dữ liệu về việc sử dụng các chủ đề được trích xuất từ LLM trong các mô hình nhân quả. Nó chỉ ra bốn cạm bẫy chính về lựa chọn, thời điểm, đo lường và vai trò, nhấn mạnh rằng đây là các biến được tạo ra chứ không phải quan sát trực tiếp.
Một nhà phân tích dữ liệu thường xuyên thực hiện thao tác sau: lấy các chủ đề (themes) được trích xuất từ LLM dựa trên nội dung cuộc gọi của khách hàng, sau đó ghép chúng vào bảng dữ liệu khách hàng chính. Những khách hàng không có bản ghi cuộc gọi sẽ nhận giá trị NULL. Trong quy trình tiền xử lý, giá trị NULL này thường được điền bằng số 0, hoặc ghi là "không có vấn đề gì", hoặc đơn giản là bị loại bỏ làm danh mục tham chiếu.
Chỉ trong một dòng lệnh tiền xử lý, quy trình này đã ngầm chuyển đổi ý nghĩa: "không gọi hỗ trợ" trở thành "không gặp phiền toái về thanh toán". Mô hình hồi quy chạy sau đó trông rất sạch sẽ. Hệ số của biến "phiền toái về thanh toán" có ý nghĩa thống kê, đúng như kỳ vọng của nhóm sản phẩm và đủ lớn để được đưa vào tài liệu lộ trình phát triển. Ít ai đặt câu hỏi về nguồn gốc thực sự của biến số này.
Bài viết này sẽ bàn về những gì đã bị "lén lút" đưa vào cùng với giá trị điền khuyết đó, và ba thao tác khác có vẻ vô hại trong notebook nhưng lại dựa trên các giả định mà phân tích chưa bao giờ đề cập.
 Dữ liệu phi cấu trúc và suy luận nhân quả
Dữ liệu phi cấu trúc và suy luận nhân quả
Biến được tạo ra, không phải quan sát
Thiết lập này không chỉ dành riêng cho các cuộc gọi hỗ trợ. Nó áp dụng cho nhật ký trò chuyện, tóm tắt vé, đánh giá sản phẩm, bản ghi bán hàng và các trường trả lời tự do trong khảo sát — ở bất cứ đâu một quy trình hiện đại chuyển đổi văn bản thành một cột dữ liệu gọn gàng. Quy trình đó có thể là một bộ phân loại tinh chỉnh (fine-tuned), một LLM zero-shot, hoặc một kết hợp của embedding và clustering. Vấn đề khái niệm là giống nhau: cột dữ liệu đó không phải là quan sát về thuộc tính của khách hàng. Nó là đầu ra của một quy trình tạo sinh được áp dụng cho một tập hợp con hành vi tự chọn của khách hàng.
Các chuyên gia ngày càng coi các đầu ra như thể chúng là những chỉ số trực tiếp về trạng thái của khách hàng. Nhưng thực tế không phải vậy. Chúng là các biến được tạo ra (generated variables): các phép đo được sản xuất bởi một pipeline, có điều kiện là khách hàng phải làm điều gì đó để lại dấu vết văn bản, và có điều kiện là dấu vết đó phải sống sót qua mô hình trích xuất. Mọi bước trong quá trình có điều kiện này đều có hậu quả đối với ý nghĩa của biến số trong mô hình nhân quả hạ nguồn, và hầu hết các hậu quả đó là vô hình trong bảng dữ liệu đã được ghép nối.
Bốn vấn đề thường gặp
Có bốn vấn đề thường xảy ra, và thao tác xử lý NULL làm lộ rõ cả bốn vấn đề cùng lúc.
1. Sự lựa chọn (Selection)
Một chủ đề tồn tại cho khách hàng vì khách hàng đó đã gọi, phàn nàn, đăng bài hoặc trả lời. Bất cứ điều gì thúc đẩy hành động đó cũng có thể tương quan với can thiệp (treatment), kết quả (outcome), hoặc cả hai. Việc điền khuyết NULL gộp "không tạo văn bản" vào danh mục tham chiếu, và phân tích không còn ước lượng tác động trên cơ sở khách hàng gốc. Nó đang ước lượng tác động trên một dân số được định nghĩa lại, và sự định nghĩa lại diễn ra trong quá trình tiền xử lý.
2. Thời điểm (Timing)
Cuộc gọi diễn ra trước, trong, hay sau can thiệp? Văn bản tiền can thiệp là một ứng cử viên cho biến gây nhiễu (confounder). Văn bản sau can thiệp là một ứng cử viên cho biến trung gian (mediator) hoặc kết quả, và việc coi nó là biến kiểm soát tiền can thiệp là nguồn gốc cổ điển của thiên lệch sau can thiệp. Bảng dữ liệu đã ghép hiếm khi làm rõ điều này.
3. Đo lường (Measurement)
Nhãn "phiền toái về thanh toán" không phải là phiền toái về thanh toán. Nó là những gì pipeline phát hiện là ngôn ngữ có hình dáng giống "phiền toái về thanh toán". Độ chính xác của bộ phân loại là hữu hạn, và độ chính xác có thể khác nhau giữa các nhóm can thiệp, bởi vì một can thiệp thay đổi cách khách hàng nói chuyện cũng sẽ thay đổi cách mô hình đọc họ. Nhiễu của nhãn không trực giao với vật đang được nghiên cứu.
4. Vai trò (Role)
Chủ đề đó đang đóng vai trò là biến gây nhiễu, trung gian, can thiệp, kết quả, hay đặc điểm mô tả? DAG (đồ thị nhân quả) quyết định điều này, không phải tên cột. Một biến hợp lệ về mặt phương pháp luận ở vai trò này sẽ trở thành nguồn thiên lệch ở vai trò khác.
Vai trò và Thời điểm là cùng một câu hỏi
Bước đầu tiên một nhà phân tích thực hiện với một chủ đề bắt nguồn từ bản ghi là ngầm định: họ coi nó là một hiệp biến (covariate). Các chủ đề đi vào vế phải của phương trình hồi quy. Cụm từ "được kiểm soát cho" đang thực hiện công việc mà nhà phân tích chưa kiểm tra. Việc kiểm soát một biến số sẽ điều chỉnh một phần mối quan hệ giữa can thiệp và kết quả chảy qua nó. Việc điều chỉnh đó giúp hay hại hoàn toàn phụ thuộc vào vị trí của biến số trong đồ thị nhân quả, và vị trí đó được xác định bởi thời điểm.
- Văn bản tiền can thiệp: Có thể đóng vai trò là biến gây nhiễu.
- Văn bản đồng thời: Là một phần của can thiệp, không phải là hiệp biến.
- Văn bản sau can thiệp: Là loại nguy hiểm nhất, dễ bị phân loại nhầm là biến gây nhiễu nhất. Việc kiểm soát một chủ đề được trích xuất từ văn bản này là đang kiểm soát một biến sau can thiệp, có thể chặn các đường trung gian hoặc gây ra các liên kết collider.
Câu hỏi về sự lựa chọn và đo lường
Hầu hết các phân tích trong ngành sử dụng bản ghi hỗ trợ đều ngầm định nghĩa lại dân số từ "khách hàng" thành "khách hàng đã tạo ra ngôn ngữ hỗ trợ". Quyết định xử lý NULL là nơi vấn đề này trở nên hoạt động.
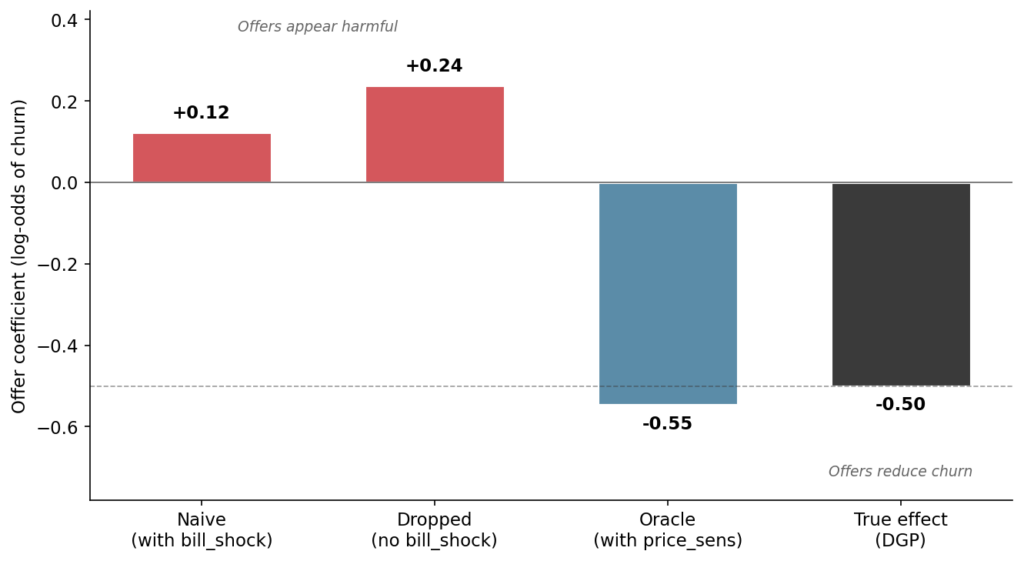
Điền NULL bằng 0 giả định rằng việc không tạo văn bản có ý nghĩa thông báo về sự vắng mặt của cấu trúc cơ bản. Điều này thường không hợp lý. Khách hàng không gọi có thể đã trải qua sự thất vọng và giải quyết bằng cách hủy dịch vụ, chuyển sang đối thủ cạnh tranh hoặc phàn nàn trên mạng xã hội. Việc điền 0 biến tất cả những điều này thành "không có sự thất vọng".
Về mặt đo lường, các đầu ra của LLM trông rất giống các cấu trúc tiềm ẩn. Một nhãn như "sự thất vọng về thanh toán" đọc giống như mô tả tâm trạng của khách hàng. Tuy nhiên, vấn đề thống kê là một chủ đề LLM là một đại diện nhiễu (noisy proxy) cho cấu trúc cơ bản. Nếu một can thiệp thay đổi cách khách hàng nói chuyện, độ chính xác của bộ phân loại có thể khác nhau giữa nhóm can thiệp và nhóm đối chứng. Nhiễu của nhãn không còn có giá trị trung bình bằng 0. Nó tương quan với can thiệp và làm thiên lệch tác động ước tính.
Danh sách kiểm tra cho người thực hành
Một phân tích nhân quả sử dụng biến được tạo ra từ bản ghi vẫn có thể được bảo vệ. Nó chỉ cần trả lời năm câu hỏi trước khi chạy hồi quy:
- Tôi đang giả định biến này đóng vai trò gì? Biến gây nhiễu, trung gian, can thiệp, kết quả hay đặc điểm mô tả? DAG quyết định, tên cột thì không.
- Văn bản được tạo ra khi nào so với can thiệp? Trước, trong hay sau? Nếu không thể trả lời từ dữ liệu, biến không được nhập mô hình làm biến gây nhiễu.
- Cơ chế lựa chọn nào đã tạo ra văn bản, và tôi đang giả định điều gì về những người không có văn bản? Điền 0, loại bỏ hay IPW? Mỗi lựa chọn là một giả định.
- Nhãn được sản xuất như thế nào, và độ tin cậy có thể khác nhau giữa các nhóm can thiệp không? Nếu can thiệp thay đổi cách khách hàng diễn đạt cấu trúc cơ bản, độ chính xác của bộ phân loại không hằng số.
- Kết quả trông như thế nào trong bài kiểm tra căng thẳng (stress test)? Chạy lại mô hình mà không có biến bắt nguồn từ bản ghi. Nếu hệ số chính dễ bị thay đổi, kết quả không đủ ổn định để đưa ra khẳng định nhân quả.
Các câu hỏi này không phải là giải pháp. Chúng là một chẩn đoán. Một nhà phân tích không thể trả lời chúng đang làm công việc mô tả nhưng gắn ngôn ngữ nhân quả vào đó. Các giả định không biến mất, chúng chỉ di chuyển ngược dòng quy trình.


