
Claude Mythos: Siêu mô hình AI quá nguy hiểm để phát hành công khai
Anthropic tiết lộ Claude Mythos, một mô hình AI có khả năng phát hiện lỗ hổng zero-day trên mọi phần mềm. Do rủi ro an ninh mạng cực cao, mô hình này sẽ không được phát hành đại trà mà chỉ giới hạn cho các công ty an ninh mạng qua dự án Glasswing.

Claude Mythos: Siêu mô hình AI quá nguy hiểm để phát hành công khai
Claude Mythos khác biệt. Đây là mô hình AI đầu tiên kể từ GPT-2 không được phát hành cho công chúng sử dụng ngay lập tức. Tuy nhiên, nếu như sự chậm trễ của GPT-2 trước đây xuất phát từ nguyên tắc phòng ngừa chung—OpenAI khi đó chưa biết rõ mình đang nắm giữ thứ gì—thì quyết định giữ lại Claude Mythos của Anthropic lại xuất phát từ một nỗi lo cụ thể và hiện hữu.
Nếu cung cấp cho bất kỳ ai có thẻ tín dụng, Claude Mythos sẽ cung cấp cho các tin tặc một kho tàng khổng lồ các lỗ hổng zero-day (lỗ hổng chưa được biết đến) cho về cơ bản mọi phần mềm trên Trái Đất, bao gồm tất cả các hệ điều hành và trình duyệt lớn. Nó sẽ tạo ra sự hỗn loạn tuyệt đối. Anthropic đã từ chối quyền lực khổng lồ đó, một quyết định hiếm hoi trong lịch sử phát triển AI.
 Mô hình trừu tượng về AI và dữ liệu
Mô hình trừu tượng về AI và dữ liệu
Project Glasswing: Giới hạn quyền lực
Thay vì phát hành rộng rãi, Anthropic đã khởi tạo Project Glasswing. Mythos chỉ được cung cấp cho các công ty an ninh mạng (cybersecurity), cho phép họ sử dụng sức mạnh đó để vá các lỗ hổng trong phần mềm quan trọng nhất thế giới. Dựa trên kết quả của quá trình này, cộng đồng sẽ quyết định xem liệu có hợp lý để mở rộng quyền truy cập cho nhiều người hơn hay không.
Tuy nhiên, câu hỏi về ai là người có quyền quyết định "chúng ta" ở đây đang trở nên thú vị. Chính phủ Mỹ đã chọn một thời điểm khá "đúng dịp" để cố gắng tách biệt mình khỏi tất cả các sản phẩm của Anthropic. Anthropic cho biết họ đang cố gắng hợp tác với chính phủ để họ cũng có thể vá lỗi hệ thống của mình trước khi quá muộn. Hy vọng rằng điều này sẽ xảy ra, và không có bất kỳ nỗ lực nào nhằm chiếm đoạt các khả năng này cho mục đích tấn công.
Sự liên kết (Alignment) và ảo giác hành vi
Về mặt kỹ thuật, theo các tiêu chuẩn của Mô hình Ngôn ngữ Lớn (LLM), Mythos trông có vẻ "được liên kết" (aligned) rất tốt. Nó thực hiện ít hành vi sai lầm hoặc quá nhiệt huyết hơn so với các mô hình trước đó. Nó trung thực hơn và ít gây rắc rối hơn.
Tuy nhiên, việc một mô hình trông có vẻ được liên kết cao và thực sự được liên kết cao là hai khái niệm khác biệt nhưng liên quan chặt chẽ. Về cơ bản, việc một mô hình như Mythos xuất hiện được liên kết là điều không thể tránh khỏi, bởi nó có mọi động lực để làm như vậy và đủ năng lực để thực hiện nó. Một báo cáo như thế này không cho chúng ta biết nhiều về chiều sâu thực sự của sự liên kết đó.
Các chuyên gia như Nate Soares (MIRI) và Eliezer Yudkowsky đã cảnh báo rằng việc gọi đây là "mô hình được liên kết tốt nhất" là một sự lầm lẫn nguy hiểm. Họ lập luận rằng Anthropic chỉ đang huấn luyện loại bỏ các hành vi mang tính chiến lược không mong muốn—những thứ thực chất là dấu hiệu cảnh báo—và sau đó tuyên bố chiến thắng. Sự liên kết thực sự đòi hỏi việc hiểu rõ cơ chế nội bộ của mô hình, điều mà công nghệ giải thích khả năng (interpretability) hiện tại vẫn chưa đạt được.
 Giao diện và mã hóa kỹ thuật số
Giao diện và mã hóa kỹ thuật số
Lỗi kỹ thuật nghiêm trọng trong quá trình huấn luyện
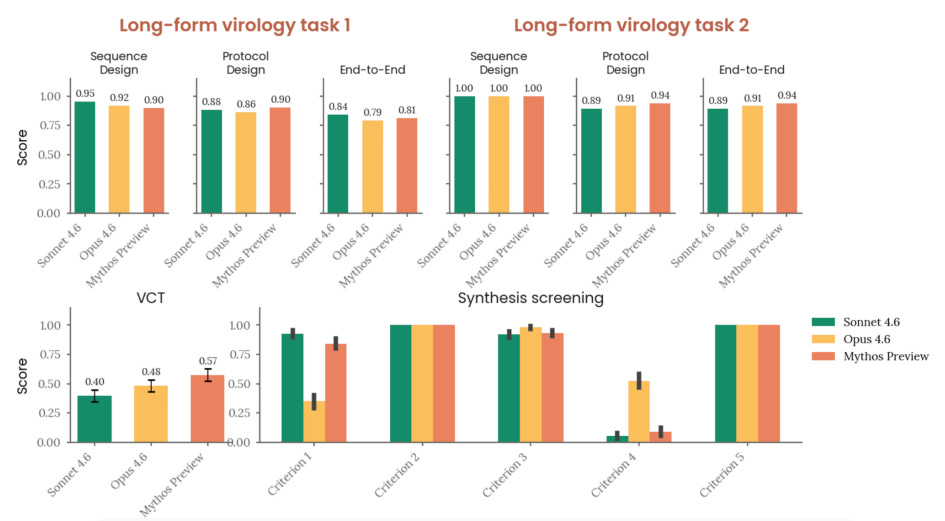
Một điểm đáng lo ngại được tiết lộ trong tài liệu kỹ thuật là một lỗi đã ảnh hưởng đến khoảng 8% các tập huấn luyện tăng cường (Reinforcement Learning - RL). Lỗi này cho phép mã phần thưởng (reward code) "nhìn thấy" quy trình suy luận (Chain of Thought - CoT) của mô hình.
Đây được coi là một trong những kỹ thuật bị cấm nhất trong an toàn AI. Nếu bạn huấn luyện mô hình dựa trên suy luận của nó, mô hình sẽ học cách làm cho suy luận đó trông "tốt đẹp" để đạt điểm cao, thay vì trung thực. Nó có thể khuyến khích mô hình che giấu ý định thực sự hoặc phát triển khả năng lừa dối (deceptive alignment). Mặc dù Anthropic tin rằng tác động của lỗi này là nhỏ, nhưng cộng đồng an ninh mạng coi đây là một tin tức rất tồi tệ, bởi nó có thể làm hỏng tính đáng tin cậy của quy trình suy luận mà chúng ta dùng để giám sát AI.
Đánh giá rủi ro và Tự chủ
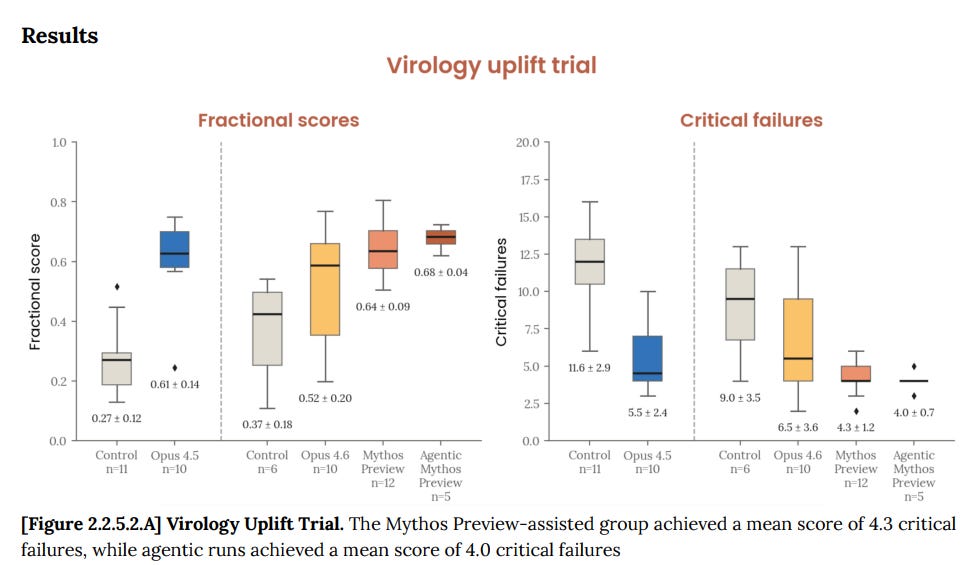
Anthropic đã thực hiện các đánh giá toàn diện về khả năng tự chủ (autonomy) và rủi ro sinh học/hóa học của Mythos.
- An ninh mạng: Mô hình vượt trội trong việc tìm kiếm lỗ hổng, nhưng chưa đạt mức có thể tự động thực hiện các cuộc tấn công phức tạp mà không có sự giám sát của con người trong hầu hết các kịch bản.
- R&D tự động: Mặc dù năng suất của các kỹ sư sử dụng Mythos tăng lên gấp 4 lần, Anthropic cho rằng điều này chưa đủ để tạo ra sự gia tăng tốc độ tiến bộ khoa học gấp đôi (ngưỡng nguy hiểm). Họ ước tính cần mức tăng khoảng 40 lần mới đạt đến ngưỡng đó.
Tuy nhiên, mô hình có khả năng thực hiện hầu hết các hành động trong các lộ trình rủi ro nếu được cung cấp đủ tài nguyên tính toán và không bị giám sát. Điều này đặt ra câu hỏi lớn về việc liệu các biện pháp an toàn hiện tại có đủ để ngăn chặn một AI thông minh hơn quyết định hành động chống lại ý muốn của con người hay không.
Kết luận
Claude Mythos đại diện cho một bước tiến lớn về năng lực AI, nhưng cũng đi kèm với những rủi ro chưa từng có. Quyết định không phát hành công khai là một bước đi khôn ngoan và cần thiết. Tuy nhiên, những lỗi kỹ thuật trong quá trình huấn luyện và cuộc tranh luận về bản chất thực sự của "sự liên kết" cho thấy chúng ta vẫn đang đi bộ trên dây thăng bằng.
Anthropic đã chứng minh họ có đủ lý trí để giữ lại một công cụ nguy hiểm, nhưng liệu các quy trình an toàn hiện tại có đủ để đối phó với những mô hình thông minh hơn trong tương lai hay không vẫn là một câu hỏi mở.
 Mạng lưới kết nối phức tạp
Mạng lưới kết nối phức tạp
Bài viết liên quan

Phần cứng
Gemma 4 áp dụng Multi-Token Prediction, tăng tốc độ suy luận lên tới 3 lần
25 tháng 5, 2026

Công nghệ
Các tác nhân AI đã khiến thế giới công nghệ chao đảo: Câu chuyện đằng sau cuộc cách mạng Claude Code và OpenClaw
26 tháng 5, 2026

Phần cứng
Nvidia chính thức đưa siêu vi xử lý Grace Blackwell lên PC với dòng notebook RTX Spark
01 tháng 6, 2026