
Cloudflare và ETH Zurich phác thảo chiến lược tối ưu hóa Cache trong kỷ nguyên AI
Cloudflare và ETH Zurich đã chỉ ra cách lưu lượng truy cập từ các trình thu thập dữ liệu AI đang thách thức các cơ chế bộ nhớ đệm truyền thống trong CDN và cơ sở dữ liệu. Họ đề xuất các chiến lược nhận biết AI, bao gồm việc phân tầng bộ nhớ đệm, sử dụng thuật toán thích ứng và mô hình tính phí theo lần thu thập để cân bằng hiệu suất cho người dùng và dịch vụ AI.
Cloudflare và ETH Zurich phác thảo chiến lược tối ưu hóa Cache trong kỷ nguyên AI
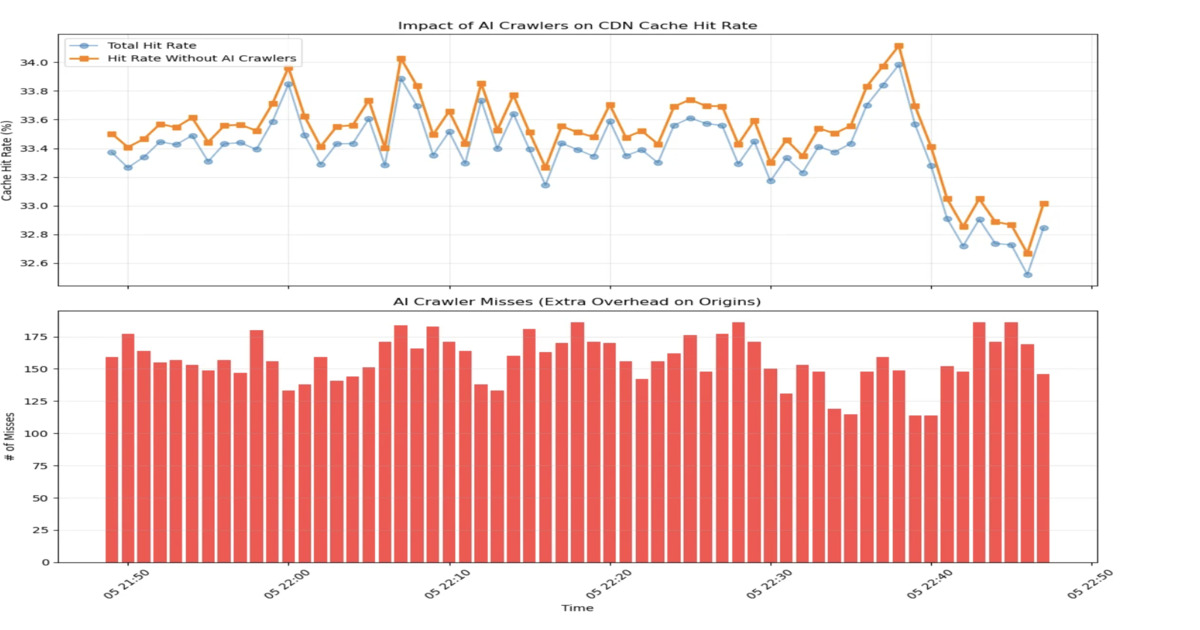
Cloudflare và ETH Zurich mới đây đã công bố các thách thức vận hành do lưu lượng truy cập từ các trình thu thập dữ liệu (crawler) sử dụng AI gây ra, đồng thời đề xuất các phương pháp để cải thiện hiệu quả bộ nhớ đệm trong mạng lưới phân phối nội dung (CDN). Các kỹ sư tại Cloudflare báo cáo rằng lưu lượng truy cập từ bot AI hiện đã vượt quá 10 tỷ yêu cầu mỗi tuần, tạo ra các mô hình hành vi khác biệt đáng kể so với hành vi duyệt web của con người. Những thay đổi này đang ảnh hưởng trực tiếp đến độ trễ, tỷ lệ trúng cache (cache hit rates) và việc sử dụng tài nguyên trên toàn bộ hạ tầng CDN và backend.
Tác động của lưu lượng truy cập AI đối với hạ tầng
Khoảng một phần ba lưu lượng truy cập của Cloudflare đến từ các nguồn tự động hóa, bao gồm trình thu thập dữ liệu của công cụ tìm kiếm, công cụ kiểm tra thời gian hoạt động (uptime checkers) và các trợ lý AI. Trong đó, các trình thu thập dữ liệu AI hoạt động mạnh mẽ nhất, chịu trách nhiệm cho khoảng 80% yêu cầu từ bot tự nhận dạng. Chúng phát ra hàng loạt yêu cầu song song với quy mô lớn, thường xuyên truy cập các trang hiếm khi được ghé thăm hoặc quét trang web theo tuần tự để hỗ trợ các dịch vụ AI như Retrieval-Augmented Generation (RAG).
Hành vi của trình thu thập AI khác biệt rõ rệt so với hành vi của người dùng. Nhiều trình thu thập AI duy trì tỷ lệ URL duy nhất rất cao, truy cập nhiều loại nội dung đa dạng và phát ra các yêu cầu không tái sử dụng nội dung bộ nhớ đệm hiệu quả. Không giống như người dùng, AI crawlers không tận dụng bộ nhớ đệm của trình duyệt hay tính liên tục của phiên làm việc, và nhiều phiên bản độc lập có thể tạo ra các yêu cầu lặp lại cho cùng một nội dung.
Mô hình hóa của Cloudflare cho thấy các vòng lặp lặp lại của các tác nhân AI tạo ra mức độ truy cập nội dung duy nhất liên tục, làm thay thế nội dung thường xuyên được yêu cầu bởi con người trong các bộ nhớ đệm tại biên (edge caches).
Erika S, một kỹ sư hệ thống, đã nhận định trong một bài đăng trên X:
Tỷ lệ truy cập duy nhất từ 70-100% trong các vòng lặp RAG giải thích sự biến động cache mà tôi đã trải qua trong quá trình tinh chỉnh gần đây. Việc LRU thất bại dưới tải trọng AI khiến việc lưu trữ tại Đức trở nên khó dự đoán.
Phá vỡ kiến trúc bộ nhớ đệm truyền thống
Lưu lượng truy cập AI làm tăng tỷ lệ cache miss cho CDN, làm giảm hiệu quả của các chiến lược tối ưu hóa truyền thống như thuật toán loại bỏ bộ nhớ đệm ít được sử dụng gần đây (LRU), suy đoán bộ nhớ đệm và tải trước (prefetching). Lưu lượng trình thu thập AI mô phỏng đã gây ra sự sụt giảm có thể đo lường được trong tỷ lệ cache hit tại một nút CDN duy nhất, dẫn đến tăng tải cho máy chủ gốc (origin server) và làm chậm thời gian phản hồi.
BeePopCommunity, một quan sát viên công nghệ, đã nhấn mạnh tác động vận hành rộng rãi trong một bài đăng trên X:
Lưu lượng truy cập AI đang phá vỡ các giả định được xây dựng cho con người.
Amy Lee, CFO tại Aerospike, đã mô tả tác động rộng hơn đối với cơ sở dữ liệu trong một bài đăng trên LinkedIn:
Đúng vậy! Lưu lượng truy cập AI đang phá vỡ kiến trúc bộ nhớ đệm truyền thống, không chỉ ở tầng CDN mà còn kéo dài đến cơ sở dữ liệu. Khi 70-100% yêu cầu là duy nhất, các mô hình truy cập không còn đủ khả dự đoán để lưu vào bộ nhớ đệm. Hầu hết các cơ sở dữ liệu hoạt động tốt khi các điều kiện thuận lợi. Lưu lượng truy cập AI đang loại bỏ có hệ thống các điều kiện được tối ưu hóa đó.
Các chiến lược giải pháp nhận biết AI
Để giải quyết các thách thức này, Cloudflare và ETH Zurich đề xuất các chiến lược bộ nhớ đệm nhận biết AI (AI-aware caching strategies). Các giải pháp bao gồm:
- Tách biệt lưu lượng truy cập của con người và AI vào các tầng bộ nhớ đệm riêng biệt.
- Kiểm tra các thuật toán thay thế khác như "ít được sử dụng nhất" (LFU) hoặc "vào trước ra trước" (FIFO).
- Khám phá các chính sách dựa trên học máy có thể thích ứng động.
Ngoài ra, các biện pháp bổ sung như nguồn cấp dữ liệu có cấu trúc hoặc mô hình tính phí theo lần thu thập (pay-per-crawl) có thể giúp kiểm soát quyền truy cập của AI trong khi vẫn bảo toàn hiệu quả của bộ nhớ đệm. Cloudflare nhấn mạnh rằng các dịch vụ điều khiển bởi AI đòi hỏi các cách tiếp cận bộ nhớ đệm khác biệt so với lưu lượng truy cập của con người. Các đề xuất này làm nổi bật những điều chỉnh kỹ thuật và vận hành tiềm năng mà các trang web cần thực hiện để phục vụ hiệu quả cả người dùng và tác nhân AI.
Bài viết liên quan

Phần cứng
Gemma 4 áp dụng Multi-Token Prediction, tăng tốc độ suy luận lên tới 3 lần
25 tháng 5, 2026

Công nghệ
Các tác nhân AI đã khiến thế giới công nghệ chao đảo: Câu chuyện đằng sau cuộc cách mạng Claude Code và OpenClaw
26 tháng 5, 2026

Phần cứng
Nvidia chính thức đưa siêu vi xử lý Grace Blackwell lên PC với dòng notebook RTX Spark
01 tháng 6, 2026