
Decoupled DiLoCo: Kiến trúc huấn luyện AI phân tán mới của Google, bền bỉ và tiết kiệm băng thông
Google DeepMind giới thiệu Decoupled DiLoCo, một phương pháp huấn luyện AI phân tán cho phép kết nối nhiều trung tâm dữ liệu mà không cần đồng bộ hóa chặt chẽ. Công nghệ này giúp tăng khả năng chịu lỗi phần cứng, giảm thiểu yêu cầu về băng thông và cho phép kết hợp linh hoạt các thế hệ phần cứng khác nhau.

Huấn luyện một mô hình AI tiên phong hiện nay thường phụ thuộc vào một hệ thống lớn với sự liên kết chặt chẽ, trong đó các chip phải được đồng bộ hóa gần như hoàn hảo. Mặc dù cách tiếp cận này hiệu quả với các mô hình hiện đại, nhưng khi hướng tới các thế hệ quy mô lớn hơn trong tương lai, việc duy trì mức độ đồng bộ hóa này hàng ngàn chip trở thành một thách thức lớn về hậu cần.
Để giải quyết vấn đề này, Google DeepMind đã công bố một phương pháp mới mang tên Decoupled DiLoCo (Distributed Low-Communication - Phân tán Thấp thông tin liên lạc). Đây là một kiến trúc giúp huấn luyện các Mô hình Ngôn ngữ Lớn (LLM) trên nhiều trung tâm dữ liệu xa cách nhau với băng thông thấp hơn và khả năng phục hồi phần cứng cao hơn.
 Kiến trúc Decoupled DiLoCo
Kiến trúc Decoupled DiLoCo
Cách tiếp cận "Đảo" tính toán phân tán
Decoupled DiLoCo hoạt động bằng cách chia nhỏ các quá trình huấn luyện lớn thành các "đảo" tính toán tách biệt (các đơn vị học tập), với luồng dữ liệu không đồng bộ giữa chúng. Kiến trúc này cô lập các sự cố cục bộ để các phần khác của hệ thống có thể tiếp tục học hỏi hiệu quả mà không bị gián đoạn.
Điều này khác biệt hoàn toàn so với các phương pháp huấn luyện song song dữ liệu (Data-Parallel) truyền thống, vốn yêu cầu độ trễ liên lạc rất thấp và trở nên không khả thi khi áp dụng ở quy mô toàn cầu.
Khả năng phục hồi và tự chữa lành
Một trong những ưu điểm lớn nhất của Decoupled DiLoCo là khả năng chịu lỗi (resilience). Hệ thống này được xây dựng dựa trên cơ chế tự chữa lành. Trong quá trình kiểm thử, nhóm nghiên cứu đã sử dụng phương pháp "kỹ thuật hỗn loạn" (chaos engineering) để tạo ra các lỗi phần cứng nhân tạo.
Kết quả cho thấy Decoupled DiLoCo tiếp tục quá trình huấn luyện ngay cả khi mất toàn bộ các đơn vị học tập, và sau đó tái tích hợp chúng một cách liền mạch khi chúng quay lại trực tuyến. Các thử nghiệm trên mô hình Gemma 4 đã chứng minh rằng khi phần cứng gặp sự cố, hệ thống duy trì mức độ sẵn sàng của cụm huấn luyện cao hơn nhiều so với các phương pháp truyền thống.
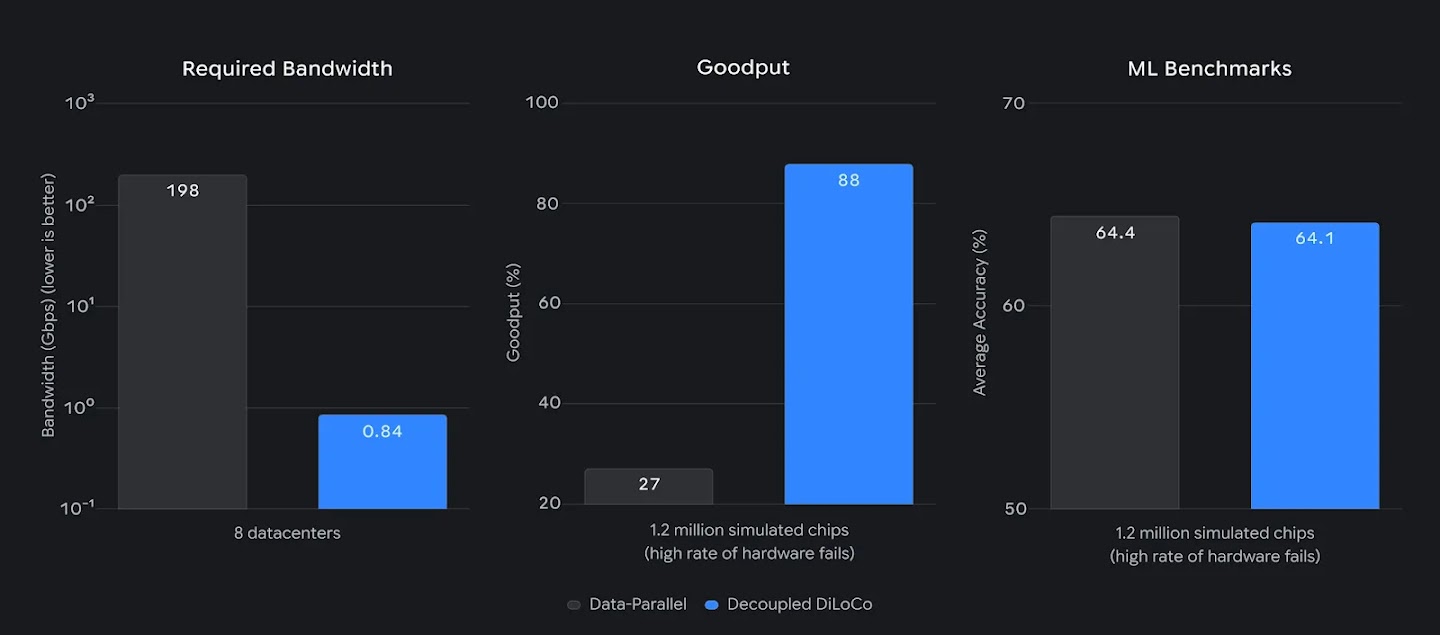 Biểu đồ hiệu suất và băng thông
Biểu đồ hiệu suất và băng thông
Hiệu quả vượt trội về băng thông và tốc độ
Decoupled DiLoCo không chỉ bền bỉ hơn mà còn thực tế để thực hiện việc tiền huấn luyện phân tán quy mô sản xuất. Google đã thành công trong việc huấn luyện một mô hình có 12 tỷ tham số trên bốn khu vực riêng biệt tại Hoa Kỳ chỉ bằng cách sử dụng kết nối mạng diện rộng (WAN) 2-5 Gbps.
Đây là mức băng thông có thể đạt được thông qua kết nối internet hiện có giữa các cơ sở trung tâm dữ liệu, không yêu cầu cơ sở hạ tầng mạng tùy chỉnh mới. Đáng chú ý, hệ thống đạt được kết quả huấn luyện này nhanh hơn 20 lần so với các phương pháp đồng bộ hóa truyền thống, nhờ việc tích hợp truyền thông vào các chu kỳ tính toán dài hơn và tránh các nút thắt cổ chai "chặn" (blocking).
Linh hoạt kết hợp nhiều thế hệ phần cứng
Ngoài hiệu suất và khả năng phục hồi, mô hình huấn luyện này còn mở ra khả năng kết hợp các thế hệ phần cứng khác nhau trong cùng một lần chạy huấn luyện. Ví dụ, có thể kết hợp chip TPU v6e và TPU v5p.
Cách tiếp cận này không chỉ kéo dài tuổi thọ hữu ích của phần cứng hiện có mà còn tăng tổng lượng tính toán có sẵn cho huấn luyện mô hình. Trong các thí nghiệm, các chip từ các thế hệ khác nhau chạy ở tốc độ khác nhau vẫn đạt được hiệu suất ML tương đương với các lần chạy chỉ sử dụng một loại chip. Điều này đặc biệt hữu ích khi các thế hệ phần cứng mới không được triển khai đồng thời ở mọi nơi, giúp giảm thiểu các nút thắt cổ chai về hậu cần và công suất.
Với sự phát triển của Decoupled DiLoCo, Google đang chứng minh rằng việc tái cấu trúc cách các lớp phần cứng, phần mềm hạ tầng và nghiên cứu phù hợp với nhau là chìa khóa để mở khóa thế hệ AI tiếp theo.
Bài viết liên quan

Phần cứng
Nvidia chính thức đưa siêu vi xử lý Grace Blackwell lên PC với dòng notebook RTX Spark
01 tháng 6, 2026

Phần cứng
Kẻ trộm táo bạo cắt đứt đường truyền sóng FM 100.000 watt giữa ban ngày
07 tháng 6, 2026

Công nghệ
Cơ quan giám sát thi cử Anh lo ngại kính thông minh biến kỳ thi thành công cụ tìm kiếm
07 tháng 6, 2026