
Điều gì thực sự cần thiết để chạy code trên siêu máy tính MareNostrum 200 triệu Euro?
Bài viết khám phá cấu trúc bên trong của MareNostrum V, một trong những siêu máy tính mạnh nhất thế giới hiện nay. Chúng ta sẽ cùng tìm hiểu về kiến trúc Fat-tree, bộ lập lịch SLURM và những thách thức đặc thù khi làm việc với môi trường Điện toán hiệu năng cao (HPC) so với các nền tảng đám mây thương mại.

Điều gì thực sự cần thiết để chạy code trên siêu máy tính MareNostrum 200 triệu Euro?
Nếu bạn đi dạo qua khuôn viên trường Đại học Bách khoa Catalonia ở Barcelona, bạn có thể sẽ tình cờ bắt gặp nhà nguyện Torre Girona trong một công viên tuyệt đẹp. Được xây dựng vào thế kỷ 19, nơi này có một cây thánh giá khổng lồ, những vòm cao và kính màu. Tuy nhiên, bên trong gian chính, được bao bọc trong một chiếc hộp kính khổng lồ chiếu sáng, lại là một loại kiến trúc hoàn toàn khác.
Đây là nơi ở lịch sử của MareNostrum. Trong khi các rack phiên bản năm 2004 vẫn được trưng bày trong nhà nguyện như một hiện vật bảo tàng, thì thế hệ mới nhất, MareNostrum V — một trong 15 siêu máy tính mạnh nhất thế giới — lại nằm trải dài trong một cơ sở chuyên biệt được làm mát tích cực ngay sát vách đó.
Hầu hết các nhà khoa học dữ liệu đã quen với việc khởi tạo một phiên bản EC2 nặng ký trên AWS hoặc sử dụng các khung phân tán như Spark hay Ray. Tuy nhiên, Điện toán hiệu năng cao (HPC) ở cấp độ siêu máy tính lại là một "quái vật" hoàn toàn khác. Nó vận hành dựa trên các quy tắc kiến trúc khác biệt, các bộ lập lịch riêng biệt và ở một quy mô khó có thể tưởng tượng nổi nếu bạn chưa từng trải nghiệm.
Gần đây, tôi đã có cơ hội sử dụng MareNostrum V để tạo ra một lượng lớn dữ liệu tổng hợp cho một mô hình thay thế (surrogate model) trong học máy. Dưới đây là cái nhìn bên trong "cỗ máy" trị giá 200 triệu Euro này: nó là gì, tại sao kiến trúc của nó lại có thiết kế như vậy, và cách bạn thực sự tương tác với nó.
Kiến trúc Mạng: Tại sao Đường dây lại Quan trọng
Mô hình tư duy gây nhiều nhầm lẫn nhất khi tiếp cận HPC là: bạn không đang thuê thời gian trên một chiếc máy tính duyệt vô cùng mạnh mẽ. Thay vào đó, bạn đang gửi công việc để được phân phối đến hàng ngàn máy tính độc lập mà恰好 chia sẻ một mạng lưới cực kỳ nhanh.
Tại sao một nhà khoa học dữ liệu lại cần quan tâm đến mạng vật lý? Bởi vì nếu bạn từng cố gắng đào tạo một mạng nơ-ron khổng lồ trên nhiều phiên bản AWS và thấy những chiếc GPU đắt tiền của bạn rảnh rỗi trong khi chờ đợi chuyển một lô dữ liệu, bạn sẽ biết rằng trong điện toán phân tán, mạng lưới chính là máy tính.
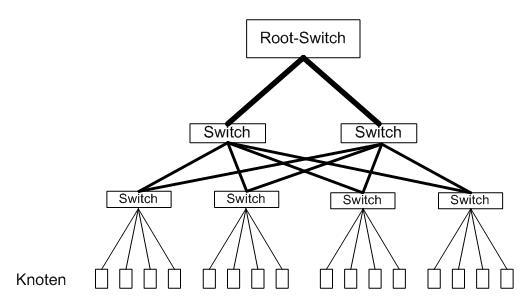 Kiến trúc Fat-tree giúp ngăn chặn tắc nghẽn băng thông
Kiến trúc Fat-tree giúp ngăn chặn tắc nghẽn băng thông
Để ngăn chặn các nút thắt cổ chai (bottlenecks), MareNostrum V sử dụng kết cấu InfiniBand NDR200 được sắp xếp theo topology Fat-tree. Trong một mạng văn phòng tiêu chuẩn, khi nhiều máy tính cố gắng giao tiếp qua một switch chính, băng thông sẽ bị tắc nghẽn. Topology Fat-tree giải quyết vấn đề này bằng cách tăng băng thông của các liên kết khi bạn di chuyển lên hệ thống phân cấp mạng, theo nghĩa đen là làm cho các "nhánh" dày hơn gần "gốc cây". Điều này đảm bảo băng thông không chặn: bất kỳ trong số 8.000 node nào cũng có thể nói chuyện với bất kỳ node nào khác ở cùng một độ trễ tối thiểu.
Cỗ máy này đại diện cho khoản đầu tư chung từ EuroHPC Joint Undertaking, Tây Ban Nha, Bồ Đào Nha và Thổ Nhĩ Kỳ, được chia thành hai phân vùng tính toán chính:
Phân vùng Mục đích Chung (GPP): Được thiết kế cho các tác vụ CPU tính toán song song cao. Nó chứa 6.408 node, mỗi node đóng gói 112 nhân Intel Sapphire Rapids, với hiệu suất đỉnh kết hợp là 45,9 PFlops. Đây là phần bạn sẽ sử dụng thường xuyên nhất cho các tác vụ tính toán "tổng quát".
Phân vùng Tăng tốc (ACC): Phần này chuyên biệt hơn, được thiết kế với ý định đào tạo AI, động học phân tử và các tác vụ tương tự. Nó chứa 1.120 node, mỗi node có bốn GPU NVIDIA H100 SXM. Với mức giá lẻ khoảng 25.000 USD cho một chiếc H100, riêng chi phí GPU đã vượt quá 110 triệu USD. Các GPU mang lại cho nó hiệu suất đỉnh cao hơn nhiều so với GPP, đạt tới 260 PFlops.
 Hệ thống máy chủ và hạ tầng làm mát của MareNostrum V
Hệ thống máy chủ và hạ tầng làm mát của MareNostrum V
Ngoài ra còn có một loại node đặc biệt gọi là Login Nodes. Các node này đóng vai trò là "cánh cửa trước" của siêu máy tính. Khi bạn SSH vào Mare Nostrum, đây là nơi bạn sẽ hạ cánh. Login nodes chỉ dành cho các tác vụ nhẹ: di chuyển tệp, biên dịch mã và gửi tập lệnh công việc lên bộ lập lịch. Chúng không dành để tính toán.
Hạ tầng Lượng tử: Sự kết hợp Cổ điển và Lượng tử
Các node cổ điển không còn là phần cứng duy nhất bên trong chiếc hộp kính. Gần đây, Mare Nostrum 5 đã được tích hợp về mặt vật lý và logic với các máy tính lượng tử đầu tiên của Tây Ban Nha. Điều này bao gồm một hệ thống lượng tử dựa trên cổ kỹ thuật số và MareNostrum-Ona mới được trang bị, một máy tính lượng tử kiểu annealer hiện đại dựa trên qubit siêu dẫn. Thay vì thay thế siêu máy tính cổ điển, các đơn vị xử lý lượng tử (QPUs) này đóng vai trò là các bộ tăng tốc chuyên dụng cao.
Khi siêu máy tính gặp phải các vấn đề tối ưu hóa cực kỳ phức tạp hoặc mô phỏng hóa học lượng tử mà ngay cả GPU H100 cũng bị "ngợp", nó có thể chuyển các tính toán cụ thể đó sang phần cứng lượng tử, tạo ra một cỗ máy tính lai cổ điển - lượng tử khổng lồ.
Thực tế về Airgap, Hạn ngạch và HPC
Hiểu về phần cứng chỉ mới là một nửa trận chiến. Các quy tắc vận hành của một siêu máy tính hoàn toàn khác so với một nhà cung cấp đám mây thương mại. MareNostrum V là một tài nguyên công cộng được chia sẻ, điều này có nghĩa là môi trường bị hạn chế nặng nề để đảm bảo bảo mật và sự công bằng.
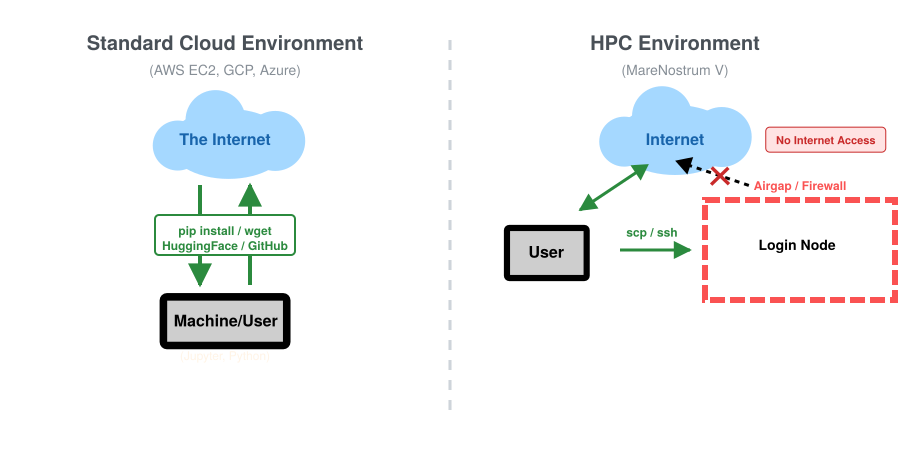 Định nghĩa Airgap - sự cô lập mạng hoàn toàn
Định nghĩa Airgap - sự cô lập mạng hoàn toàn
Airgap (Vùng mạng cô lập): Một trong những cú sốc lớn nhất đối với các nhà khoa học dữ liệu chuyển sang HPC là hạn chế mạng. Bạn có thể truy cập siêu máy tính từ thế giới bên ngoài thông qua SSH, nhưng các node tính toán hoàn toàn không thể truy cập thế giới bên ngoài. Không có kết nối Internet đi ra. Bạn không thể pip install một thư viện còn thiếu, wget một tập dữ liệu, hay kết nối với kho lưu trữ HuggingFace bên ngoài theo ý muốn. Mọi thứ mà tập lệnh của bạn cần phải được tải xuống trước, biên dịch và nằm trong thư mục lưu trữ của bạn trước khi bạn gửi công việc.
Trong thực tế, vấn đề này ít nghiêm trọng hơn vẻ bề ngoài, vì quản trị viên của Marenostrum cung cấp hầu hết các thư viện và phần mềm bạn có thể cần thông qua một hệ thống module.
Di chuyển Dữ liệu: Do ranh giới nghiêm ngặt này, việc nhập và xuất dữ liệu diễn ra thông qua scp hoặc rsync qua các login node. Bạn đẩy các tập dữ liệu thô vào qua SSH, đợi các node tính toán "nhai" xong các mô phỏng, và kéo các tensor đã xử lý trở lại máy local của mình. Một khía cạnh đáng ngạc nhiên của sự hạn chế này là, vì quá trình tính toán thực tế có thể cực kỳ nhanh, nút thắt cổ chai lại nằm ở việc trích xuất kết quả hoàn chỉnh về máy local để xử lý hậu kỳ và trực quan hóa.
Giới hạn và Hạn ngạch: Bạn không thể chỉ cần khởi chạy một nghìn công việc và độc chiếm máy móc. Dự án của bạn được cấp một ngân sách CPU-giờ cụ thể. Hơn nữa, có các giới hạn cứng về số lượng công việc đồng thời mà một người dùng có thể chạy hoặc xếp hàng tại bất kỳ thời điểm nào.
Bạn cũng phải chỉ định giới hạn thời gian chạy nghiêm ngặt cho mỗi công việc bạn gửi. Siêu máy tính không dung nhan sự làm lê thê; nếu bạn yêu cầu hai giờ tính toán nhưng tập lệnh của bạn cần hai giờ và một giây, bộ lập lịch sẽ vô tình kết thúc quy trình của bạn giữa chừng để nhường chỗ cho nhà nghiên cứu tiếp theo.
Hiểu về Trình quản lý Khối lượng Công việc SLURM
Khi bạn cuối cùng cũng được phê duyệt phân bổ nghiên cứu và đăng nhập vào MareNostrum V qua SSH, phần thưởng của bạn là... một dòng nhắc terminal Linux hoàn toàn tiêu chuẩn.
Sau nhiều tháng viết đề xuất xin quyền truy cập vào một cỗ máy 200 triệu Euro, thành thật mà nói, nó hơi thất vọng. Không có đèn nhấp nháy, không có thanh tiến trình holographic, không có gì để báo hiệu just how powerful the engine behind the wheel is.
 Giao diện dòng lệnh khi đăng nhập vào hệ thống
Giao diện dòng lệnh khi đăng nhập vào hệ thống
Vì hàng ngàn nhà nghiên cứu đang sử dụng máy móc đồng thời, bạn không thể chỉ thực thi một tập lệnh python hay C++ nặng ký trực tiếp trong terminal. Nếu bạn làm vậy, nó sẽ chạy trên "login node", nhanh chóng làm cho nó bị treo và gây ảnh hưởng đến người khác, đồng thời mang lại cho bạn một email lịch sự nhưng kiên quyết từ các quản trị viên hệ thống.
Thay vào đó, HPC dựa vào một trình quản lý khối lượng công việc được gọi là SLURM. Bạn viết một tập lệnh bash chi tiết chính xác phần cứng bạn cần, môi trường phần mềm nào cần tải, và mã nào để thực thi. SLURM đặt công việc của bạn vào một hàng đợi, tìm kiếm phần cứng khi nó trở nên khả dụng, thực thi mã của bạn và giải phóng các node.
SLURM là viết tắt của Simple Linux Utility for Resource Management, là một phần mềm mã nguồn mở miễn phí xử lý lập lịch công việc trong nhiều cụm máy tính và siêu máy tính.
Trước khi xem xét một pipeline phức tạp, bạn cần hiểu cách giao tiếp với bộ lập lịch. Điều này được thực hiện bằng cách sử dụng các chỉ thị #SBATCH được đặt ở đầu tập lệnh gửi của bạn. Các chỉ thị này hoạt động như danh sách mua sắm tài nguyên của bạn:
--nodes: Số lượng máy vật lý riêng biệt bạn cần.--ntasks: Tổng số quy trình MPI riêng biệt (tác vụ) bạn muốn tạo. SLURM xử lý việc phân phối các tác vụ này trên các node được yêu cầu.--time: Giới hạn thời gian đồng hồ tường nghiêm ngặt cho công việc của bạn. Siêu máy tính không dung nhan sự làm lê thê; nếu tập lệnh của bạn chạy quá hạn mức này dù chỉ một giây, SLURM sẽ kết thúc công việc.--account: ID dự án cụ thể sẽ bị tính phí cho CPU-giờ của bạn.--qos: "Chất lượng Dịch vụ" hoặc hàng đợi cụ thể bạn đang nhắm tới. Ví dụ, sử dụng hàng đợi debug cho phép truy cập nhanh hơn nhưng giới hạn bạn ở thời gian chạy ngắn để kiểm tra.
Ví dụ Thực tế: Điều phối OpenFOAM Sweep
Để hiện thực hóa điều này, đây là cách tôi thực sự sử dụng máy móc. Tôi đang xây dựng một mô hình thay thế ML để dự đoán lực ép khí động học, yêu cầu dữ liệu thực tế từ 50 mô phỏng Động lực học chất lưu tính toán (CFD) độ trung thực cao trên 50 lưới 3D khác nhau.
Dưới đây là tập lệnh công việc SLURM thực tế cho một trường hợp CFD OpenFOAM đơn lẻ trên Phân partition Mục đích Chung:
#!/bin/bash
#SBATCH --job-name=cfd_sweep
#SBATCH --output=logs/sim_%j.out
#SBATCH --error=logs/sim_%j.err
#SBATCH --qos=gp_debug
#SBATCH --time=00:30:00
#SBATCH --nodes=1
#SBATCH --ntasks=6
#SBATCH --account=nct_293
module purge
module load OpenFOAM/11-foss-2023a
source $FOAM_BASH
# MPI launchers xử lý ánh xạ lõi tự động
srun --mpi=pmix surfaceFeatureExtract
srun --mpi=pmix blockMesh
srun --mpi=pmix decomposePar -force
srun --mpi=pmix snappyHexMesh -parallel -overwrite
srun --mpi=pmix potentialFoam -parallel
srun --mpi=pmix simpleFoam -parallel
srun --mpi=pmix reconstructPar
Thay vì gửi cái này thủ công 50 lần và làm ngập bộ lập lịch, tôi đã sử dụng các phụ thuộc SLURM để xâu chuỗi mỗi công việc phía sau cái trước. Điều này tạo ra một pipeline dữ liệu tự động sạch sẽ:
#!/bin/bash
PREV_JOB_ID=""
for CASE_DIR in cases/case_*; do
cd $CASE_DIR
if [ -z "$PREV_JOB_ID" ]; then
OUT=$(sbatch run_all.sh)
else
OUT=$(sbatch --dependency=afterany:$PREV_JOB_ID run_all.sh)
fi
PREV_JOB_ID=$(echo $OUT | awk '{print $4}')
cd ../..
done
Trình điều phối này thả một chuỗi 50 công việc vào hàng đợi trong vài giây. tôi rời đi và vào sáng hôm sau, 50 đánh giá khí động học của tôi đã được xử lý, ghi nhật ký và sẵn sàng để được định dạng thành tensor cho việc đào tạo ML.
Giới hạn Tính toán Song song: Định luật Amdahl
Một câu hỏi phổ biến từ những người mới đến là: Nếu bạn có 112 nhân mỗi node, tại sao bạn chỉ yêu cầu 6 tác vụ (ntasks=6) cho mô phỏng CFD của mình?
Câu trả lời nằm ở Định luật Amdahl. Mọi chương trình đều có một phần tuần tự không thể song song hóa. Nó tuyên bố rõ ràng rằng sự tăng tốc lý thuyết khi thực thi một chương trình trên nhiều bộ xử lý bị giới hạn nghiêm ngặt bởi phần mã phải được thực thi tuần tự. Về mặt toán học, nó được biểu thị như:
[ S=\frac{1}{(1-p)+\frac{p}{N}} ]
Trong đó S là sự tăng tốc tổng thể, p là tỷ lệ mã có thể song song hóa, 1−p là phần tuần tự nghiêm ngặt, và N là số lượng lõi xử lý.
Bởi vì số hạng (1−p) trong mẫu số, bạn đối mặt với một trần không thể vượt qua. Nếu chỉ 5% chương trình của bạn về cơ bản là tuần tự, thì tốc độ tăng lý thuyết tối đa bạn có thể đạt được, ngay cả khi bạn sử dụng mọi lõi đơn trong MareNostrum V, chỉ là 20x.
Hơn nữa, chia nhỏ một tác vụ trên quá nhiều lõi làm tăng chi phí truyền tải qua mạng InfiniBand mà chúng ta đã thảo luận earlier. Nếu các lõi dành nhiều thời gian hơn để truyền các điều kiện biên cho nhau thay vì thực hiện phép tính thực tế, việc thêm phần cứng sẽ làm chậm chương trình đi.
Viết mã cho một siêu máy tính là một bài tập trong việc quản lý tỷ lệ tính toán trên truyền tải này.
Cơ hội Truy cập
Mặc dù chi phí phần cứng là khổng lồ, việc truy cập vào MareNostrum V là miễn phí cho các nhà nghiên cứu, vì thời gian tính toán được coi là một tài nguyên khoa học được tài trợ công khai.
Nếu bạn liên kết với một tổ chức Tây Ban Nha, bạn có thể nộp đơn qua Mạng lưới Siêu máy tính Tây Ban Nha (RES). Đối với các nhà nghiên cứu trên khắp châu Âu còn lại, EuroHPC Joint Undertaking chạy các đợt truy cập thường xuyên. Dòng "Truy cập Phát triển" của họ được thiết kế đặc biệt cho các dự án chuyển mã hoặc benchmark các mô hình ML, giúp nó rất dễ tiếp cận với các nhà khoa học dữ liệu.
Khi bạn ngồi tại bàn làm việc và nhìn vào dòng nhắc SSH hoàn toàn bình thường đó, rất dễ quên những gì bạn thực sự đang nhìn thấy. Những gì con trỏ nhấp nháy đó không hiển thị là 8.000 node mà nó kết nối, cấu trúc Fat-tree đang định tuyến tin nhắn giữa chúng ở tốc độ 200 Gb/s, hoặc bộ lập lịch đang điều phối hàng trăm công việc đồng thời từ các nhà nghiên cứu trên sáu quốc gia.
Hình ảnh "máy tính đơn lẻ mạnh mẽ" vẫn tồn tại trong đầu chúng ta vì nó đơn giản hơn. Nhưng thực tế phân tán mới là thứ làm cho điện toán hiện đại trở nên khả thi, và nó dễ tiếp cận hơn nhiều so với what most people realize.
Bài viết liên quan

Phần cứng
Gemma 4 áp dụng Multi-Token Prediction, tăng tốc độ suy luận lên tới 3 lần
25 tháng 5, 2026

Phần cứng
Nvidia chính thức đưa siêu vi xử lý Grace Blackwell lên PC với dòng notebook RTX Spark
01 tháng 6, 2026

Công nghệ
Alienware 15 mới: Dell đang làm loãng thương hiệu cao cấp vì khủng hoảng RAM?
14 tháng 5, 2026