
DiffuJudge-AV: Khung khổ "khử nhiễu" giúp AI đánh giá chính xác video an toàn cho xe tự lái
DiffuJudge-AV giới thiệu phương pháp tiếp cận mới sử dụng nguyên lý từ mô hình Diffusion để hiệu chuẩn và khử nhiễu cho các hệ thống đánh giá dựa trên LLM trong lĩnh vực xe tự lái. Kết quả bất ngờ cho thấy các mô hình mã nguồn mở nhỏ hơn như Qwen2.5-VL lại vượt trội hơn các "ông lớn" khép kín trong việc phát hiện lỗi an toàn quan trọng.
Có một loại kết quả trông rất ấn tượng cho đến khi bạn đặt ra một câu hỏi tiếp theo sai lầm. Trong dự án này, kết quả đó là hệ số tương quan Pearson đạt 0,753 từ một mô hình Claude chỉ dựa trên văn bản khi chấm điểm các câu hỏi trả lời trực quan (Visual-QA) về xe tự lái. Nhìn thoáng qua, đây dường như là một công cụ đánh giá khả dụng. Nó bám sát các điểm số chuẩn (gold scores), đưa ra lý do hợp lý và là một mô hình khép kín mạnh mẽ. Đủ tốt để phân loại đầu ra của mô hình, đúng không?
Nhưng khi nhìn vào hệ số Cohen’s κ có trọng số bậc hai, con số đó chỉ là 0,057.
Đó chính là khoảnh khắc dự án thay đổi hướng đi. "Giám khảo" AI này có tương quan thứ hạng với các nhãn chuẩn, nhưng nó không hoạt động như một người đánh giá an toàn thứ tự thực thụ. Nó đã học được chế độ thất bại trông an toàn nhất: nén hầu hết mọi thứ về giữa thang điểm 1–5. Đối với báo cáo điểm chuẩn thông thường, điều này có thể lọt qua mà không bị phát hiện. Nhưng đối với quy trình đánh giá xe tự lái cần gắn cờ cho các câu trả lời sai trước khi chúng chặn một bản phát hành phần mềm, điều này cực kỳ nguy hiểm.
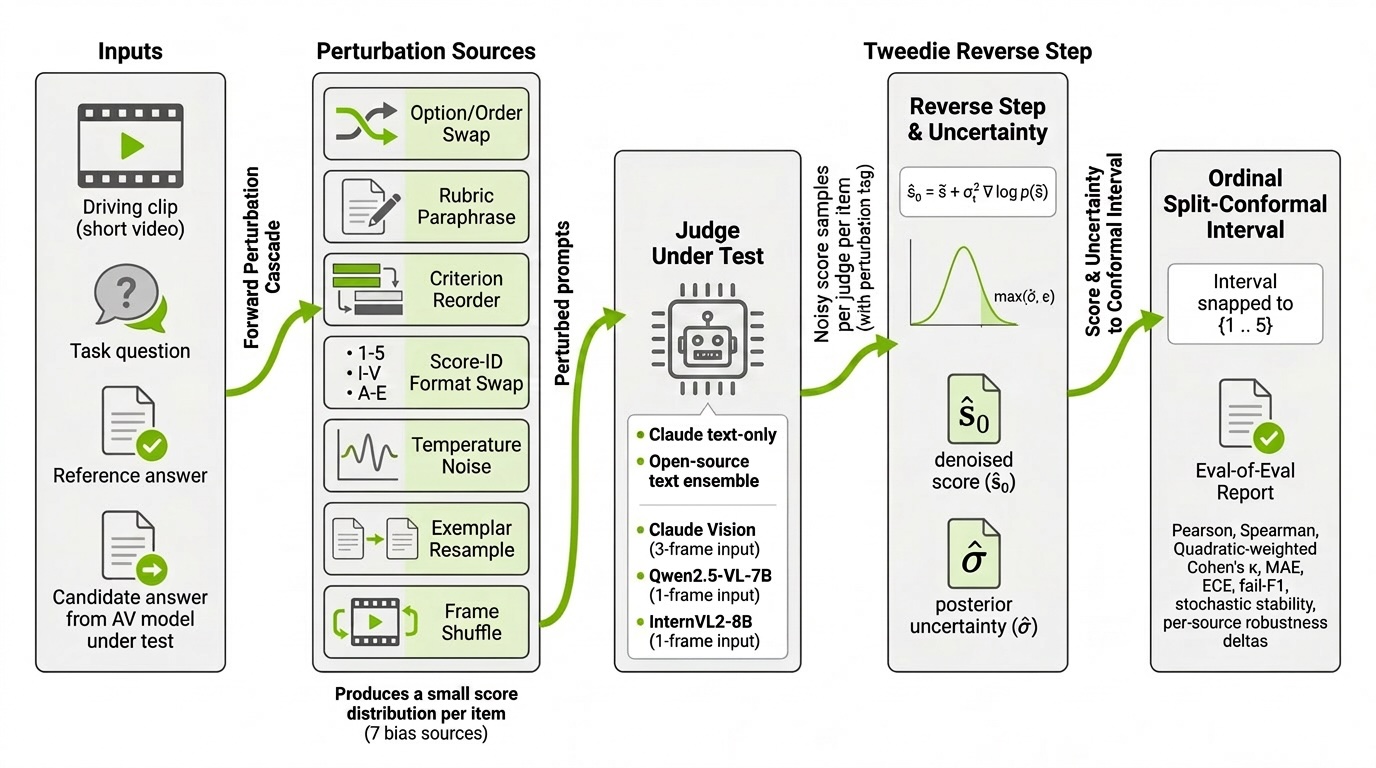
Đó là lý do DiffuJudge-AV ra đời — một khung đánh giá nhỏ dành cho các "giám khảo" LLM/VLM trên video lái xe. Ý tưởng rất đơn giản: coi điểm số của giám khảo là một quan sát nhiễu của một điểm số quy tắc tiềm ẩn, cố tình phơi bày giám khảo với các nguồn thiên kiến chấm điểm đã biết, sau đó khử nhiễu phân bố điểm số kết quả bằng posterior mean Tweedie một bước và báo cáo độ không chắc chắn đã hiệu chuẩn.
 Biểu đồ so sánh hiệu suất của các mô hình
Biểu đồ so sánh hiệu suất của các mô hình
Tại sao lại là "Đánh giá của đánh giá"?
Khi một mô hình trả lời một câu hỏi về cảnh lái xe, câu hỏi đánh giá hiển nhiên là: Mô hình có trả lời đúng không?
Ví dụ: Câu hỏi: Có xe nào đỗ bên đường không? Tham chiếu: Có, có hai xe đỗ ở bên phải. Câu trả lời ứng viên (mô hình đang thử nghiệm): Tôi không biết. Điểm số chuẩn: 1,13 (thấp).
Đối với con người, việc này rất dễ dàng. Xem đoạn clip, so sánh câu trả lời với cảnh, và đưa ra điểm số. Tuy nhiên, ở quy mô lớn, đánh giá của con người trở thành nút thắt cổ chai. Các hệ thống tự lái hiện đại tạo ra nhiều đoạn clip nhận thức, nhật ký kịch bản, mô phỏng và đầu ra mô hình hơn bất kỳ đội ngũ chú giải nào có thể chấm điểm thủ công. Do đó, các nhóm tự nhiên hướng tới giải pháp LLM-as-a-Judge hoặc VLM-as-a-Judge: đưa cho mô hình câu hỏi, câu trả lời tham chiếu, câu trả lời ứng viên, quy tắc và đôi khi là các khung hình, sau đó yêu cầu nó chấm điểm.
Điều này tạo ra một vấn đề thứ tự: Nếu giám khảo là một mô hình, làm sao chúng ta biết giám khảo đó đáng tin cậy? Đây chính là "đánh giá của đánh giá" (eval-of-eval). Thay vì chỉ hỏi liệu mô hình xe tự lái có đúng không, chúng ta hỏi liệu chính người đánh giá có ổn định, đã hiệu chuẩn, kháng thiên kiến và hữu ích cho các quyết định hạ nguồn hay không.
Trực giác: Điểm số giám khảo là phép đọc từ cảm biến nhiễu
Điểm số của giám khảo LLM trông sạch sẽ vì nó là một con số: 1, 2, 3, 4 hoặc 5. Nhưng con số đó có thể thay đổi vì những lý do không liên quan gì đến chất lượng thực tế của câu trả lời. Thay đổi thứ tự tùy chọn. Diễn giải lại quy tắc. Đảo lại tiêu chí. Đổi nhãn điểm từ chữ số Ả Rập sang chữ La Mã. Lấy mẫu lại ví dụ. Thay đổi nhiệt độ (temperature). Xáo trộn các khung hình video. Chất lượng câu trả lời thực tế không đổi, nhưng giám khảo thì đã thay đổi.
Điều đó gợi ý một mô hình tinh thần hữu ích: Hãy coi giám khảo như một cảm biến nhiễu.
Có một điểm số tiềm ẩn $s_0$. Giám khảo không bao giờ quan sát trực tiếp nó. Mỗi biến thể của câu hỏi (prompt) tạo ra một phép đọc nhiễu. Trong khuôn khổ này, $t$ không phải là bước thời gian diffusion theo nghĩa tạo ảnh. Nó là một nguồn được ghi nhận của sự nhiễu loạn giám khảo, được rút trực tiếp từ tài liệu về thiên kiến LLM-as-a-Judge giai đoạn 2024–2025.
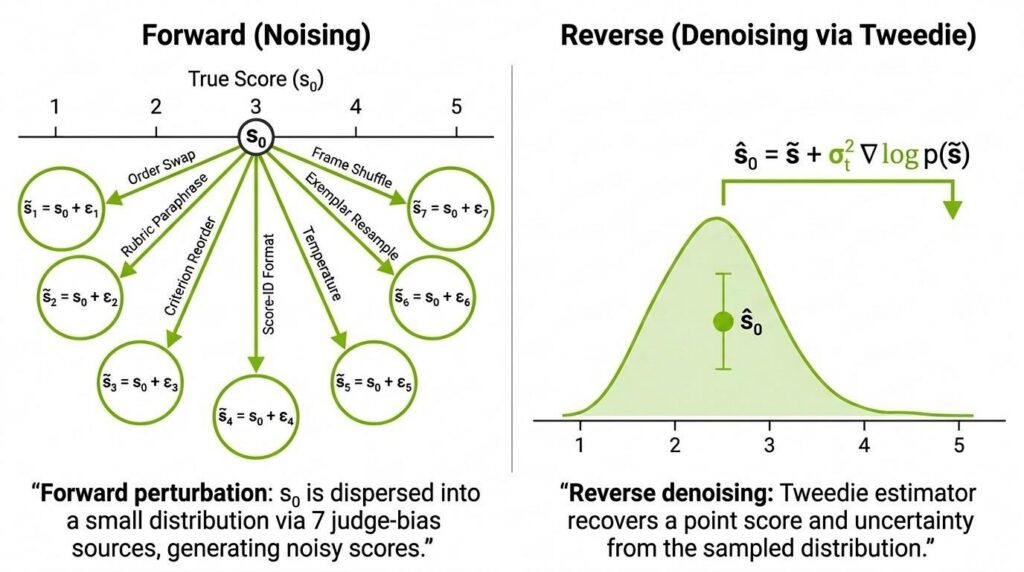 Sơ đồ quy trình DiffuJudge-AV
Sơ đồ quy trình DiffuJudge-AV
Bước khử nhiễu: Công thức Tweedie
Sự tương đồng với diffusion trở nên hữu ích vì có một kết quả kinh điển đằng sau việc khử nhiễu: công thức Tweedie. Nếu một quan sát nhiễu $\tilde{s}$ được tạo ra bằng cách thêm nhiễu Gaussian vào một giá trị sạch tiềm ẩn $s_0$, thì posterior mean là:
$\hat{s}0 = \tilde{s} + \sigma_t^2 , \nabla{\tilde{s}} \log p(\tilde{s})$
Khung này ước tính $p(\tilde{s})$ bằng Gaussian KDE trên các điểm số mẫu theo từng mục. Phương sai trong từng mức độ nhiễu loạn cho $\sigma_t^2$. Tổng hợp qua các cấp độ được trọng số chính xác trước khi hiệu chỉnh Tweedie. Hai đầu ra ra khỏi từ bước ngược duy nhất này:
- Một ước lượng điểm khử nhiễu $\hat{s}_0$.
- Một độ không chắc chắn posterior theo từng mục $\hat{\sigma}_i$.
Đầu ra thứ hai là phần quan trọng hơn. Trong quy trình xem xét an toàn, tôi không chỉ muốn một con số. Tôi muốn biết liệu giám khảo có đủ tự tin để con số đó có thể hành động được hay không.
Kết quả: Mã nguồn mở chiến thắng
Trên 28.400 đánh giá giám khảo trên điểm chuẩn LingoQA của Wayve, phát hiện thú vị nhất không phải là một mô hình khép kín lớn hơn đã thắng. Thực tế là nó đã thua. Giám khảo tốt nhất trong thí nghiệm là Qwen2.5-VL-7B, một mô hình ngôn ngữ thị giác mã nguồn mở 7B. Nó đạt được:
- Pearson r = 0,857
- Spearman $\rho$ = 0,856
- Cohen’s $\kappa$ có trọng số bậc hai = 0,837
- MAE = 0,57
- Fail-detection F1 = 0,712
Đối với nhiệm vụ đánh giá kiểu xe tự lái này, một VLM mã nguồn mở không chỉ cạnh tranh được. Nó tốt hơn trên các chỉ số thực sự quan trọng.
 Biểu đồ phân tán so sánh điểm số giữa các mô hình
Biểu đồ phân tán so sánh điểm số giữa các mô hình
Tầm quan trọng của thị giác (Vision)
Khám phá đáng ngạc nhiên không chỉ là việc đánh giá chỉ dựa trên văn bản hoạt động kém hơn. Đó là cùng một mô hình Claude lại hoạt động khác nhau khi được cung cấp khung hình.
- Claude TEXT-only (chỉ văn bản): Nén dự đoán vào khoảng [1,3, 3,5]. Nó từ chối sử dụng phần dưới và phần trên của thang điểm.
- Claude VISION (có thị giác): Với ba khung hình lái xe, phạm vi mở rộng ra khoảng [1,0, 5,0].
Sự nén này không phải là thuộc tính của họ mô hình hay hiệu ứng RLHF chung chung. Nó đặc thù theo chế độ đầu vào. Khi giám khảo chỉ thấy văn bản, nó phòng thủ. Khi giám khảo thấy cảnh, nó sẵn sàng sử dụng toàn bộ thang điểm thứ tự. Nhiều quy trình đánh giá vẫn sử dụng câu hỏi giám khảo chỉ dựa trên văn bản ngay cả cho các nhiệm vụ thị giác. Chúng yêu cầu giám khảo so sánh câu trả lời ứng viên với câu trả lời tham chiếu, nhưng giám khảo không bao giờ thấy bằng chứng cơ bản. Đối với các cảnh lái xe, đây là một hạn chế nghiêm trọng.
Kết luận
Bài học quan trọng nhất từ dự án này không phải là một mô hình đánh bại mô hình khác. Đó là chỉ số bạn tối ưu hóa trong eval-of-eval sẽ quyết định giám khảo bạn triển khai.
Nếu tôi chỉ tối ưu hóa cho Pearson r, tôi đã triển khai một giám khảo Claude chỉ dựa trên văn bản hầu như không sử dụng thang điểm thứ tự và chỉ bắt được 2% các lỗi an toàn nghiêm trọng. Sử dụng bảng eval-of-eval đầy đủ (thứ tự $\kappa$, fail-detection F1, hiệu chuẩn, ổn định ngẫu nhiên) đã đảo ngược quyết định sang một giám khảo VLM mã nguồn mở với độ không chắc chắn đã hiệu chuẩn và quy tắc định tuyến gửi các trường hợp mơ hồ cho con người.
Đối với các hệ thống đánh giá đã học, đặc biệt trong lái xe tự động, robot học và y tế, chúng ta nên ngừng coi điểm số của người đánh giá là chân lý tuyệt đối. Chúng là phép đo. Phép đo có nhiễu. Nhiễu có cấu trúc. Nếu chúng ta có thể đo lường cấu trúc đó, chúng ta có thể xây dựng những người đánh giá tốt hơn.


