
Embeddings Không Phải Là Phép Thuật: Những Cạm Bẫy Khi Sử Dụng RAG Trong Doanh Nghiệp
Mặc dù hệ thống RAG ấn tượng với khả năng xử lý đồng nghĩa và lỗi chính tả, chúng thường thất bại thầm lặng khi đối mặt với phủ định, định danh chính xác và thuật ngữ nội bộ. Bài viết này phân tích các chế độ thất bại có thể dự đoán của vector search và đề xuất các giải pháp thay thế hiệu quả hơn.

Hãy tưởng tượng hai tình huống quen thuộc thường xảy ra khi triển khai hệ thống trí tuệ tài liệu doanh nghiệp.
Tình huống 1: Một hệ thống RAG (Retrieval-Augmented Generation) mới được triển khai trên vài trăm trang tài liệu chính sách. Điều khiến mọi người ấn tượng đầu tiên là khả năng xử lý câu nói lại (paraphrase). Ai đó hỏi "làm sao để hủy?", dù tài liệu không hề dùng từ "hủy" mà chỉ nhắc đến "thủ tục chấm dứt", hệ thống vẫn tìm ra đúng trang. Một người dùng khác hỏi bằng tiếng Pháp trong khi tài liệu lại bằng tiếng Anh, và kết quả vẫn chính xác. Một vài lỗi chính tả hay đánh máy sai cũng không thành vấn đề. Cảm giác như phép thuật đang hiện hữu.
Tình huống 2: Cùng một hệ thống đó, nhưng hai tuần sau.
Người dùng hỏi "quy định về làm thêm giờ của nhà thầu là gì?". Hệ thống trả lời "Tôi không tìm thấy thông tin đó". Người dùng — người vừa lúc này là chuyên gia đã viết một nửa cuốn sổ tay này — nhíu mày, mở file PDF, gõ cụm từ "lao động phi nhân viên" vào Ctrl+F, và chỉ mất ba giây để tìm đến đúng đoạn văn. Từ khóa đúng không phải là "làm thêm giờ" (overtime), mà là thuật ngữ mà tài liệu thực sự sử dụng. Chuyên gia biết điều đó, nhưng embedding thì không.
Rất nhanh chóng, nhiều trường hợp tương tự xuất hiện. Các câu hỏi phủ định bị sai. Các số tham chiếu hợp đồng chính xác bị lỗi. Mã sản phẩm nội bộ trả về kết quả sai loại. Không một trong số này có thể sửa chữa được bằng cách đổi nhà cung cấp embedding.
Vị thế của loạt bài này rất rõ ràng: phần lớn độ tin cậy trong doanh nghiệp đến từ việc lọc dữ liệu thượng nguồn mạnh mẽ (từ khóa chuyên gia, cấu trúc tài liệu), chứ không phải từ một mô hình xếp hạng lại (reranker) xếp chồng lên quá trình truy xuất yếu kém.
Embeddings làm tốt ở đâu?
Trước khi nói về thất bại, hãy nhìn vào những điểm mạnh thực sự của embeddings. Những thất bại chỉ có ý nghĩa khi so sánh với các thành công này.
Embedding biến một đoạn văn bản thành một vector. Các đoạn văn bản có thuật ngữ tương tự sẽ nằm gần nhau trong không gian vector.
1. Gần gũi về mặt khái niệm
"Xe hơi" (car) sẽ khớp với các đoạn về "phương tiện", "ô tô". Embedding nắm bắt được trường ngữ nghĩa, không chỉ là các từ bề mặt. Đây là điều khiến embeddings trở nên mạnh mẽ: người dùng không cần đoán từ vựng của tài liệu; embedding sẽ cầu nối phần còn lại.
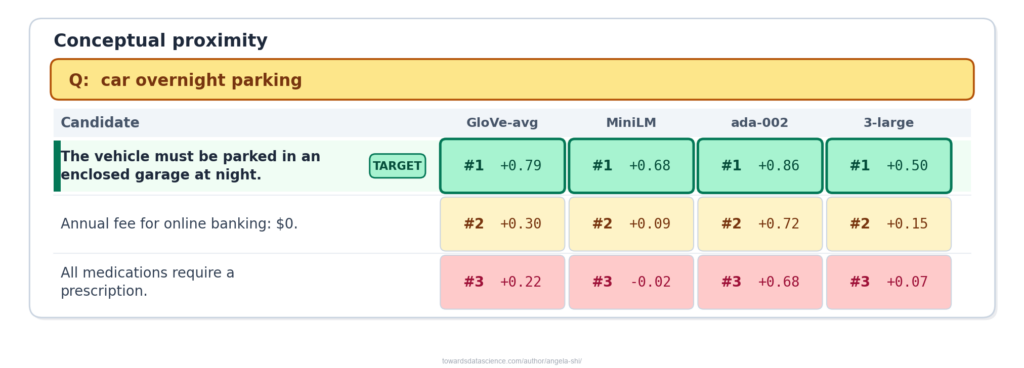 Ví dụ về sự gần gũi khái niệm
Ví dụ về sự gần gũi khái niệm
2. Đồng nghĩa và câu nói lại
"Số điện thoại" khớp với "điện thoại". "Hủy chính sách" khớp với mục có tiêu đề "thủ tục chấm dứt". Mô hình đã học được hai bộ từ vựng nói cùng một việc, bao gồm cả khoảng cách giữa cách nói bình thường của người dùng và ngôn ngữ trang trọng trong tài liệu.
3. Lỗi chính tả và đánh sai
"insurence" (thiếu r) vẫn được nhúng gần "insurance". "polciy" vẫn tìm thấy mục chính sách. Các mô hình embedding hiện đại được huấn luyện trên "món súp" văn bản từ web nơi các lỗi chính tả này xuất hiện liên tục, và chúng đã học cách hấp thụ nhiễu.
4. Khớp đa ngôn ngữ
Các embedding đa ngôn ngữ đặt các từ như "premium" (Anh), "prime" (Pháp) và "Prämie" (Đức) vào cùng một khu vực lân cận. Một từ khóa tiếng Pháp có thể truy xuất được đoạn tiếng Anh về cùng một khái niệm.
Tại sao chúng thất bại?
Những khả năng ở trên là có thật, nhưng những thất bại dưới đây cũng thực tế không kém, có thể tái hiện và tồn tại trên mọi mô hình. Một mô hình lớn hơn không thể thay đổi thứ hạng. Giải pháp nằm ở kiến trúc, không phải là "chọn một embedding mạnh hơn".
1. Thuật ngữ không có trong mô hình
Đây là thất bại cơ bản nhất. Hãy lấy từ "pool" trong hợp đồng bảo hiểm: nó là công cụ chia sẻ rủi ro, không phải hồ bơi. Ý nghĩa hồ bơi xuất hiện khắp nơi trên web công cộng, trong khi ý nghĩa chia sẻ rủi ro lại bị chôn vùi trong sách giáo khoa tính toán. Khi truy vấn từ "pool", embedding sẽ ưu tiên ý nghĩa hồ bơi vì nó phổ biến hơn nhiều trong dữ liệu huấn luyện.
2. Phủ định (Negation)
Một câu hỏi phủ định đảo ngược quan hệ logic: người dùng muốn ứng viên là phần bù của chủ đề, không phải cái gần chủ đề nhất. Embeddings không làm được điều này.
Ví dụ, câu hỏi: "Cái gì KHÔNG phải là thành phố?". Bốn ứng viên: ba là thực thể thành phố (Paris, New York, từ "City") và một là "Bàn" (Table) — vật duy nhất trả lời đúng câu hỏi.
Mọi mô hình đều xếp câu trả lời đúng cuối cùng. Từ "NOT" trong câu hỏi hầu như không mang tín hiệu trong không gian embedding; mô hình chỉ thấy một "túi" chứa từ "city" và xếp bất cứ thứ gì liên quan đến thành phố lên cao hơn.
 Thất bại trong xử lý phủ định
Thất bại trong xử lý phủ định
3. Độ lớn và ngưỡng (Magnitudes and Thresholds)
Các so sánh số học, ngày tháng, số tiền hợp đồng. Câu hỏi "tìm giá trị lớn hơn 1M". Mọi mô hình đều chọn ứng viên là "1M" — ứng viên bằng ngưỡng nhưng không vượt quá nó. Embedding không có khái niệm về độ lớn. Nó thấy "1M" nằm cạnh "1M" và chọn nó.
4. Sự loãng tín hiệu trong ngữ cảnh dài
Khi bạn nhúng toàn bộ một trang (300-500 từ) thành một vector duy nhất, tín hiệu của một dòng chứa câu trả lời sẽ bị trung bình với tất cả mọi thứ khác. Vector cấp trang sẽ trôi dạt về trọng tâm của nhiễu xung quanh. Đây là lý do các pipeline sản xuất nhúng cấp trang thường xuyên bỏ sót trang đúng ngay cả khi câu trả lời đang ở đó.
Cách sử dụng thực tế
Cho rằng embeddings có cả điểm mạnh và điểm yếu, làm thế nào để chúng ta sử dụng chúng thực tế trong sản xuất?
1. Tái định hình: Tìm kiếm đồng nghĩa cấp dòng
Cách đơn giản nhất để hiểu embeddings: vector tìm kiếm là tìm kiếm từ khóa có khả năng xử lý đồng nghĩa, lỗi chính tả và ngôn ngữ khác, được áp dụng từng dòng một. Nó không phải là "hiểu ngữ nghĩa cấp trang".
Trên một dòng đơn, mô hình coi "cancel" và "terminate" là gần nhau. Khi bạn nhúng cả một trang, tín hiệu của dòng tốt bị hòa lẫn. Vì vậy, hãy nhúng từng dòng (line-by-line). Chỉ tổng hợp lên cấp trang khi bước tạo nội dung cần ngữ cảnh xung quanh.
 Tìm kiếm cấp dòng hiệu quả hơn
Tìm kiếm cấp dòng hiệu quả hơn
2. HyDE: Tìm kiếm nội dung câu trả lời sẽ chứa
Thay vì đưa câu hỏi vào bộ truy xuất, hãy đưa vào văn bản trông giống như câu trả lời. Đó là ý tưởng của HyDE (Hypothetical Document Embeddings). Viết (hoặc để LLM viết) một câu có thể trả lời câu hỏi, bằng từ vựng mà tài liệu sẽ dùng, rồi nhúng nó.
Giá trị thực sự của HyDE, đặc biệt trong ngữ cảnh doanh nghiệp, là nó làm nổi bật các từ khóa mà câu trả lời sẽ chứa. "Thủ tục chấm dứt", "quyền hủy bỏ", "phí hủy". Đây là những từ khóa neo cho tìm kiếm.
3. Từ khóa chuyên gia là chìa khóa
Sửa chữa không phải là một mô hình embedding lớn hơn. Sửa chữa là chuyên gia biết từ vựng, được mã hóa thành từ điển từ khóa. Các luật sư, chuyên gia điều chỉnh khiếu nại đã biết rằng "hủy" trong ngôn ngữ người dùng bằng "chấm dứt" trong hợp đồng. Mã hóa ánh xạ này một lần là bền vững; việc yêu cầu LLM khám phá lại nó mỗi lần truy vấn là lãng phí.
Kết luận là, embeddings không phải là đũa thần. Chúng là công cụ tìm kiếm mờ (fuzzy search) tuyệt vời ở cấp dòng, nhưng cần sự hỗ trợ của kiến trúc lọc thượng nguồn và từ khóa chuyên gia để hoạt động hiệu quả trong môi trường doanh nghiệp phức tạp.
Bài viết liên quan

Phần mềm
OpenSSL Khắc Phục Lỗ Hổng Nghiêm Trọng Được Phát Hiện Bởi Trí Tuệ Nhân Tạo
09 tháng 6, 2026

Phần mềm
CVE Lite CLI: Công cụ giúp lập trình viên phát hiện và sửa lỗi phụ thuộc trong vài giây
05 tháng 6, 2026

Phần mềm
Microsoft vá gần 200 lỗ hổng bảo mật, bao gồm lỗi BitLocker và tấn công từ chối dịch vụ
09 tháng 6, 2026