
EmoNet: Nhận diện cảm xúc với Transformer và bài học từ sự trỗi dậy của LLM
Bài viết nhìn lại luận án thạc sĩ về mô hình EmoNet dùng để nhận diện cảm xúc trong hội thoại, từng đạt thứ hạng cao trên bảng xếp hạng EmoryNLP. Mặc dù lĩnh vực này đã chuyển dịch mạnh mẽ sang các mô hình ngôn ngữ lớn (LLM) và kỹ thuật fine-tuning LoRA, những tư duy cốt lõi về nhận diện người nói vẫn giữ nguyên giá trị. Tác giả chia sẻ về những gì đã xây dựng, kết quả đạt được và cách tiếp cận khác biệt nếu xây dựng lại hệ thống vào năm 2026.
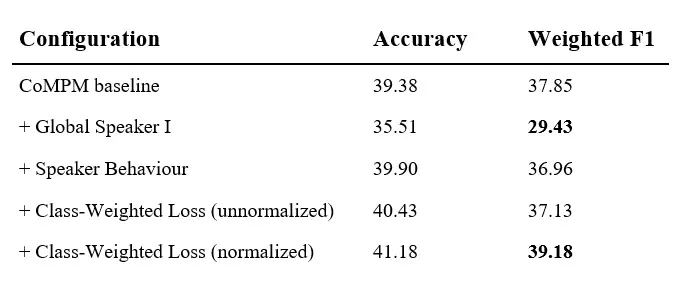
Vào tháng 3 năm 2024, tôi đã nộp luận án thạc sĩ về Nhận diện cảm xúc trong hội thoại (ERC). Mô hình EmoNet của tôi đã đạt được Weighted F1 là 39,18 trên bộ dữ liệu EmoryNLP — một kết quả cạnh tranh trực tiếp với bảng xếp hạng công khai PapersWithCode thời bấy giờ, xếp ngay sau TUCORE-GCN_RoBERTa (39,24) và trên S+PAGE (39,14), đồng thời cải thiện hơn 1,81 điểm F1 so với mô hình cơ sở (baseline) CoMPM mà tôi đã chọn.
Hai năm sau, khi quay lại nhìn xem lĩnh vực này đang ở đâu, tôi nhận thấy bảng xếp hạng đã thay đổi hoàn toàn. Các cái tên dẫn đầu không còn là những mô hình chỉ có bộ mã hóa (encoder-only) với các cơ chế chú ý (attention heads) tinh vi nữa — thay vào đó, chúng là các hệ thống dựa trên LLaMA-2–7B với fine-tuning LoRA và prompting tăng cường truy xuất (retrieval-augmented prompting): InstructERC, CKERC, BiosERC, LaERC-S. Phương pháp khác nhau, tài nguyên tính toán khác nhau và tư duy cũng khác nhau.
Tuy nhiên, khi đọc kỹ các bài báo mới này, tôi nhận thấy các ý tưởng cốt lõi mà tôi đề xuất trong EmoNet vẫn hiện hữu ở bên trong chúng, chỉ là được triển khai ở một lớp khác của kiến trúc hệ thống. Đây là câu chuyện về những gì tôi đã xây dựng, vị trí của nó, và những gì tôi sẽ xây dựng ngay bây giờ nếu được bắt đầu lại từ đầu.
ERC là gì và tại sao chỉ dùng văn bản lại khó?
Nhận diện cảm xúc trong hội thoại (ERC) là nhiệm vụ gán một nhãn cảm xúc cho mỗi lời thoại trong một cuộc hội thoại nhiều lượt. Nó khác với phân tích cảm xúc trên các câu đơn lẻ ở một điểm quan trọng: cảm xúc của một lời thoại bị chi phối bởi những gì đi trước nó, và bởi ai là người đang nói.
Hãy xem xét đoạn hội thoại sau từ bộ dữ liệu EmoryNLP (lấy từ chương trình truyền hình Friends):
Monica: Wendy, chúng ta đã có thỏa thuận! Cậu đã hứa! Wendy! Wendy! Wendy! [Tức giận] Rachel: Ai thế? [Trung tính] Monica: Wendy bỏ mặc. Tôi không có phục vụ nào cả. [Tức giận]
Nếu đứng riêng lẻ, câu "Ai thế?" về mặt cảm xúc là trung tính. Nhãn Trung tính chỉ có ý nghĩa trong ngữ cảnh — nó nằm giữa hai lời thoại giận dữ của một người nói khác, và các mô hình ERC phải nắm bắt được động thái hội thoại này.
Có một vấn đề phức tạp thứ hai: thiếu thông tin đa phương thức (multimodal). Trong cuộc hội thoại thực của con người, giọng điệu, biểu cảm khuôn mặt và ngôn ngữ cơ thể mang lại một phần rất lớn tín hiệu cảm xúc. ERC chỉ dùng văn bản đã loại bỏ tất cả những điều đó. Cùng một câu nói — "Ồ, tuyệt vời." — có thể là chân thành hoặc mỉa mai, và chỉ dựa vào văn bản thường không thể phân biệt được đâu là đâu.
Sự mất mát thông tin này là thách thức trung tâm. Bạn phải trích xuất cảm xúc từ một tín hiệu nhiễu hơn nhiều so với chuẩn mực của con người.
Bối cảnh năm 2024
Khi tôi bắt đầu luận án vào cuối năm 2023, bảng xếp hạng EmoryNLP bị thống trị bởi các kiến trúc dựa trên Transformer với nhiều sửa đổi tinh vi. Một cái nhìn nhanh qua:
- KET (Zhong et al., 2019) — transformer được làm giàu kiến thức với chú ý đồ thị cảm xúc, bài báo đầu tiên mang transformer vào ERC.
- DialogueGCN (Ghosal et al., 2019) — mạng tích chập đồ thị chuyển đổi hội thoại thành bài toán phân loại nút.
- RGAT (Ishiwatari et al., 2020) — chú ý đồ thị nhận thức quan hệ với mã hóa vị trí quan hệ cho sự phụ thuộc của người nói.
- DialogXL (Shen et al., 2020) — thích nghi XLNet với sự lặp lại của lời thoại và chú ý hội thoại.
- HiTrans (Li et al., 2020) — transformer phân cấp với xác minh người nói lời thoại cặp như một nhiệm vụ phụ trợ.
- TUCORE-GCN (Lee & Choi, 2021) — đồ thị hội thoại dị thể với BERT nhận biết người nói.
- CoMPM (Lee & Lee, 2021) — kết hợp ngữ cảnh hội thoại với theo dõi bộ nhớ được huấn luyện trước cho người nói.
Tôi chọn CoMPM làm cơ sở vì hai lý do. Thứ nhất, nó mô hình hóa rõ ràng bộ nhớ được huấn luyện trước của người nói như một mô-đun riêng biệt — điều này phù hợp với trực giác của tôi rằng ai đang nói quan trọng ngang bằng với họ đang nói gì. Thứ hai, kiến trúc của nó đủ mô-đun để mở rộng mà không cần viết lại từ đầu. Bài báo CoMPM cho thấy việc thêm bộ nhớ được huấn luyện trước vào mô hình ngữ cảnh mang lại sự cải thiện đáng đoán — nhưng danh tính người nói của họ vẫn bị giới hạn trong mỗi cuộc hội thoại. Ngay khi một cuộc hội thoại mới bắt đầu, mọi thứ mô hình đã học về người nói đó đều bị loại bỏ.
Đó dường như là một vấn đề đáng giải quyết.
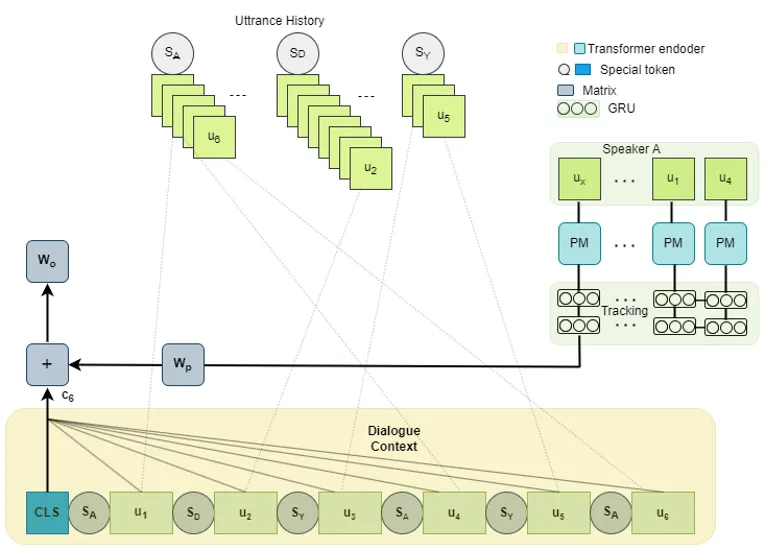
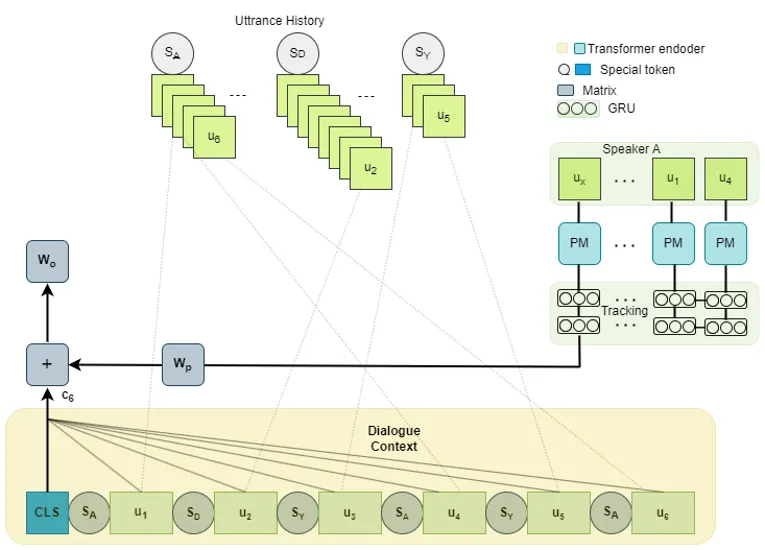 Kiến trúc mô hình EmoNet
Kiến trúc mô hình EmoNet
Ba đóng góp chính với trực giác
1. Danh tính người nói toàn cục (Global Speaker Identity)
Vấn đề. Trong CoMPM và hầu hết các công việc trước đây, ID người nói được giới hạn trong một cuộc hội thoại duy nhất. Người nói A ở cảnh 1 không có mối quan hệ nào với Người nói A ở cảnh 14, ngay cả khi họ là cùng một người. Do đó, mọi cuộc hội thoại đều bắt đầu từ con số không.
Trực giác. Con người có các mô hình cảm xúc đặc trưng. Monica dễ tức giận về những việc cụ thể; Phoebe luôn vui vẻ; Ross có những cơn bất an dễ dự đoán. Nếu mô hình có thể mang thông tin về người nói cụ thể này xuyên suốt các cuộc hội thoại, nó nên có thể đưa ra dự đoán được hiệu chỉnh tốt hơn khi người đó xuất hiện lại.
Triển khai. Mỗi người nói duy nhất trong toàn bộ bộ dữ liệu nhận được một ID ổn định trên phạm vi toàn bộ bộ dữ liệu. Lần đầu tiên Monica Geller xuất hiện, cô ấy được gán một ID — ví dụ, ID 7 — và đi theo cô ấy. Mỗi lần xuất hiện tiếp theo — xuyên suốt các tập, các mùa, các cảnh — cô ấy vẫn là ID 7. Mô hình giờ đây có thể học các mẫu đặc trưng cho người nói mà tồn tại mãi.
Điều này nghe có vẻ hiển nhiên khi nhìn lại. Vào năm 2024, đó không phải là cách các mô hình trên bảng xếp hạng hoạt động.
2. Mô-đun hành vi người nói (Speaker Behaviour Module)
Vấn đề. Danh tính người nói toàn cục đơn thuần chỉ là một nhãn. Để làm cho nó hữu ích, mô hình cần làm điều gì đó với lịch sử tích lũy của người nói. Làm thế nào để bạn cung cấp cho một transformer quyền truy cập vào "mọi thứ Monica đã nói trong bộ dữ liệu này", mà không làm vỡ cửa sổ ngữ cảnh (context window) hoặc khiến việc huấn luyện trở nên bất khả thi?
Trực giác. Sự lặp lại (Recurrence). GRU là một lựa chọn tự nhiên để nén tuần tự các lời thoại lịch sử của người nói thành một biểu diễn kích thước cố định duy nhất. Các lời thoại gần đây đóng góp nhiều hơn; các lời thoại cũ hơn dần loãng đi. Một cửa sổ trượt (sliding window) có thể cấu hình sẽ giới hạn đầu vào của GRU — ví dụ, N lời thoại cuối cùng của người nói này — giữ cho tính toán và bộ nhớ có thể dự đoán được.
Triển khai. Mỗi lời thoại được mã hóa độc lập bởi xương sống RoBERTa được huấn luyện trước. Các embedding kết quả chảy qua một GRU một chiều. Trạng thái ẩn cuối cùng của GRU — gọi là kt — đại diện cho mẫu hành vi của người nói tại thời điểm hiện tại. Điều này được chiếu vào cùng chiều kích thước với đầu ra ngữ cảnh hội thoại và được cộng vào. Tín hiệu kết hợp cung cấp cho bộ phân loại cuối cùng.
Kiến trúc này về mặt cấu trúc tương tự như mô-đun bộ nhớ được huấn luyện trước của CoMPM, nhưng có hai điểm khác biệt chính: nhóm lịch sử người nói là toàn cục (không phải cục bộ cho cuộc hội thoại hiện tại), và GRU mô hình hóa rõ ràng sự suy giảm thời gian.
3. Hàm mất mát Cross-Entropy có trọng số
Vấn đề. EmoryNLP mất cân bằng — Trung tính (Neutral) nhiều hơn Buồn (Sad) khoảng 4,5:1. Hầu hết các bài báo xử lý việc này bằng cách tăng cường dữ liệu hoặc lấy mẫu ít (under-sampling). Nhưng dữ liệu hội thoại là tuần tự: việc loại bỏ hoặc nhân bản lời thoại sẽ làm méo mó dòng chảy cảm xúc tự nhiên, và đây chính là tín hiệu mà mô hình đang cố gắng học từ đó.
Trực giác. Nếu bạn không thể thay đổi dữ liệu một cách an toàn, hãy thay đổi hàm mất mát. Hãy đánh trọng số cao hơn cho các lớp hiếm để một lần phân loại sai của lớp Buồn sẽ tốn kém hơn cho mô hình so với một lần phân loại sai của lớp Trung tính.
Triển khai. Cross-entropy với các trọng số theo lớp xuất phát từ tần suất nghịch đảo của lớp, sau đó được chuẩn hóa. Không có gì quá xa lạ — nhưng với lập luận về chuỗi hội thoại làm động lực rõ ràng, điều này trở thành một lựa chọn có nguyên tắc thay vì một lựa chọn tùy ý.
Kết quả: Điều gì hiệu quả và điều gì gây ngạc nhiên
Dưới đây là bảng ablation từ luận án:
Kết quả khiến tôi ngạc nhiên — và tôi nghĩ đây là phần trung thực nhất của công việc này — là hàng thứ hai. Việc chỉ thêm ID Người nói Toàn cục đã làm cho mô hình tồi tệ hơn đáng kể (F1 giảm từ 37,85 xuống 29,43). Lúc đầu, nó trông giống như một thất bại.
Nhưng không phải vậy. Danh tính Người nói Toàn cục là một khả năng — nó mang lại cho mô hình khả năng học các mẫu người nói tầm xa. Một mình nó, khả năng đó tạo ra gánh nặng biểu diễn mà phần còn lại của mô hình không thể hấp thụ. Chỉ khi Mô-đun Hành vi Người nói được thêm vào — cung cấp cho mô hình một cách có cấu trúc để sử dụng các danh tính toàn cục — thì đóng góp mới bộc lộ. Đến cấu hình cuối cùng, EmoNet đã phục hồi và vượt qua cơ sở CoMPM là 1,81 F1.
Đây là bài học tôi rút ra từ ablation: một tính năng không có giá trị khi đứng một mình; nó có giá trị khi kết hợp với máy móc tiêu thụ nó. Các bài báo nghiên cứu báo cáo "thêm này mang lại cho chúng ta +X%" thường giấu các hàng ablation nơi việc thêm đó làm mọi thứ tệ hơn. Tôi đã chọn giữ lại hàng đó.
Mô hình đầy đủ xử lý Trung tính, Vui vẻ và Sợ hãi tốt. Lớp Quyền lực (Powerful) vẫn là lớp khó nhất — một phần vì nó hiếm, một phần vì Quyền lực và Vui vẻ gần như không thể phân biệt được trong hội thoại bằng văn bản mà không có các tín hiệu âm thanh. Đây là một vấn đề đa phương thức (multimodal) giả dạng thành vấn đề văn bản.
Suy ngẫm (2026): Lĩnh vực đã chuyển dịch, và chúng ta cũng vậy
Hai năm sau, bảng xếp hạng EmoryNLP trông hoàn toàn khác. Các hệ thống dẫn đầu hiện nay là:
- InstructERC (Lei et al., 2023) — tái định hình ERC thành một nhiệm vụ LLM tạo sinh. Nó sử dụng các mẫu hướng dẫn tăng cường truy xuất và các nhiệm vụ phụ như xác định người nói và dự đoán cảm xúc để mô hình hóa tốt hơn vai trò hội thoại và động thái cảm xúc.
- CKERC (Fu, 2024) — giới thiệu ERC được tăng cường trí tuệ phổ thông (commonsense). Đối với mỗi lời thoại, một LLM tạo ra các chú giải trí tuệ phổ thông về ý định của người nói và phản ứng có thể có của người nghe, cung cấp lý luận xã hội và cảm xúc ngầm vượt ra ngoài ngữ cảnh hội thoại rõ ràng.
- BiosERC (Xue et al., 2024) — tiêm thông tin tiểu sử người nói có nguồn gốc từ LLM vào quy trình ERC, cho phép mô hình không chỉ lý luận trên ngữ cảnh lời thoại mà còn trên các đặc điểm cụ thể của người nói.
- LaERC-S (Fu et al., 2025) — điều chỉnh hướng dẫn hai giai đoạn. Giai đoạn 1: trang bị cho LLM các đặc điểm cụ thể của người nói. Giai đoạn 2: sử dụng các đặc điểm đó trong chính nhiệm vụ ERC.
Hãy nhìn kỹ hai cái cuối cùng.
Thông tin tiểu sử người nói của BiosERC về mặt tinh thần là Danh tính Người nói Toàn cục được mở rộng quy mô — thay vì một ID số nguyên, đó là một hồ sơ văn bản mà LLM có thể chú ý đến. Các đặc điểm người nói của LaERC-S về mặt tinh thần là Mô-đun Hành vi Người nói — các mẫu lịch sử người nói được cung cấp cho mô hình — nhưng được gộp vào điều chỉnh hướng dẫn thay vì được triển khai như một GRU riêng biệt.
Các trực giác về kiến trúc vẫn đứng vững. Lớp triển khai đã thay đổi.
Đây là phần tôi thực sự thấy thú vị. Khi tôi làm việc trên EmoNet vào năm 2024, tôi đang suy nghĩ trong khuôn khổ paradigm encoder-only-transformer: "làm thế nào để tôi thêm một mô-đun khác vào kiến trúc?". Các bài báo 2024–2025 suy nghĩ trong khuôn khổ paradigm LLM: "làm thế nào để tôi mã hóa ý tưởng này vào điều chỉnh hướng dẫn hoặc ngữ cảnh truy xuất?". Các ý tưởng tương tự; các điểm đòn bẩy khác nhau.
Nếu tôi xây dựng lại EmoNet ngay hôm nay, tôi sẽ không bắt đầu từ RoBERTa-large. Tôi sẽ bắt đầu từ một LLM mã nguồn mở nhỏ — LLaMA-3.2–3B, Qwen-2.5–3B, hoặc Phi-3.5 — và sử dụng LoRA để fine-tune nó trên EmoryNLP, theo theo các tiếp cận thuộc họ InstructERC. Danh tính Người nói Toàn cục trở thành một tiểu sử người nói dạng văn bản được truy xuất từ một vector store. Mô-đun Hành vi Người nói trở thành một prompt few-shot với lịch sử cảm xúc gần nhất của người nói. Hàm Mất mát Có trọng số gần như không đổi — mất cân bằng lớp không quan tâm bạn đang dùng mô hình nào.
Sơ đồ kiến trúc sẽ trông hoàn toàn khác. Nợ khái niệm đối với luận án năm 2024 sẽ hữu hình nếu bạn biết nơi để tìm.
Nó đã dạy tôi rằng nợ nghiên cứu có chu kỳ bán h dài hơn tôi mong đợi — các ý tưởng sống sót qua các sự thay đổi paradigm ngay cả khi các triển khai của chúng thì không.
 Sự chuyển dịch sang LLM trong nhận diện cảm xúc
Sự chuyển dịch sang LLM trong nhận diện cảm xúc
Điều này để lại điều gì cho tôi
EmoNet hiện đã được lưu trữ công khai dưới DOI 10.5281/zenodo.20048006 với toàn văn luận án, slide bảo vệ và triển khai PyTorch trên GitHub. Tôi hiện đang làm việc trên bản port hiện đại hóa — một LLM được fine-tune LoRA với ngữ cảnh người nói dựa trên truy xuất — như một dự án tiếp theo mà tôi sẽ viết về nó sớm.
Nếu bạn đang làm việc về AI hội thoại, NLP ứng dụng, hoặc fine-tuning LLM, tôi rất muốn nghe xem bạn đang xây dựng gì.
Bài viết liên quan

Công nghệ
Sự trở lại của Xbox: Chiến lược mới, thay đổi nhân sự và tương lai Project Helix
07 tháng 5, 2026

Công nghệ
Samsung Galaxy Book6 Ultra: Bản sao MacBook Pro đắt đỏ nhưng đầy khiếm khuyết
07 tháng 5, 2026

Công nghệ
Tạm biệt "Ferrynoia": Công nghệ hàng hải xanh đang thay đổi ngành vận tải thủy
05 tháng 6, 2026