
Giải Mã Thuật Toán Mạng Xã Hội: Chúng Tạo Ra "Bong Bóng" Thông Tin Như Thế Nào?
Bài viết này đi sâu vào cơ chế hoạt động của các hệ thống gợi ý trên mạng xã hội, giải thích cách chúng sử dụng dữ liệu hành vi và độ tương đồng cosin để giữ chân người dùng. Chúng ta sẽ thấy cách chỉ vài cú nhấp chuột, kết hợp với trọng số thời gian, có thể thay đổi hoàn toàn nội dung hiển thị và tạo ra các "buồng vang" thông tin nguy hiểm.

Giải Mã Thuật Toán Mạng Xã Hội: Chúng Tạo Ra "Bong Bóng" Thông Tin Như Thế Nào?
 Mạng xã hội và thuật toán
Mạng xã hội và thuật toán
Bạn có bao giờ cảm thấy rằng bảng tin (feed) mạng xã hội của mình hiểu bạn quá rõ đến mức đáng sợ? Khi bạn lướt xem một video, đột nhiên dòng thời gian của bạn bị ngập tràn bởi những nội dung tương tự. Cách đây 5 năm, điều này có vẻ như một phép màu. Nhưng ngày nay, chúng ta nói về "thuật toán" như thể nó là một thực thể huyền bí đang giật dây trong tầng hầm của thung lũng Silicon.
Sự thật thì ít kịch tính hơn, nhưng cũng thú vị hơn nhiều. Thuật toán không cố tình xấu xa, nó không ngồi đó âm mưu cực đoan hóa bạn. Nó chỉ là một đoạn mã thực hiện tính toán độ tương đồng cosin (cosine similarity) và trung bình có trọng số, cố gắng dự đoán bạn sẽ nhấp vào cái gì tiếp theo. Vấn đề nằm ở chỗ: những gì chúng ta tương tác tạo ra sự tương tác. Và cách chắc chắn nhất để giữ con người tương tác lại hóa ra là cách tồi tệ nhất để giữ họ thông tin.
Bài viết này sẽ khám phá cách các động cơ gợi ý (recommender engines) hoạt động, tại sao chúng đẩy chúng ta vào các "buồng vang" (echo chambers), và chúng ta sẽ tự xây dựng một hệ thống như vậy từ đầu để chứng minh điều đó.
Động Cơ Tương Tác: Cách Các Hệ Thống Gợi Ý Hoạt Động
 Cơ chế hoạt động của thuật toán
Cơ chế hoạt động của thuật toán
Về bản chất, thuật toán mạng xã hội là một người quản lý nội dung. Nhiệm vụ của nó là sàng lọc hàng triệu bài đăng và phục vụ cho bạn những bài bạn có khả năng tương tác nhất: nhấp, xem, thích, chia sẻ hoặc bình luận phẫn nộ. Nó làm điều này dựa trên một từ khóa duy nhất: dữ liệu.
Mọi hành động bạn thực hiện đều là một manh mối:
- Những bài đăng bạn dừng lại xem (kể cả khi không nhấp).
- Những video bạn xem và thời lượng xem.
- Những tài khoản bạn theo dõi, tắt tiếng hoặc chặn.
- Những chủ đề bạn tìm kiếm lúc nửa đêm.
Sử dụng học máy (machine learning), thuật toán phát hiện ra các mẫu trong luồng hành vi này. Nó liên tục đặt ra cùng một câu hỏi: Điều gì giữ người này ở lại nền tảng lâu hơn? Hãy nhớ rằng đây là mục tiêu lớn nhất của bất kỳ công ty mạng xã hội nào.
Hai kỹ thuật cổ điển nằm dưới hầu hết các hệ thống gợi ý:
- Lọc cộng tác (Collaborative filtering): Tìm kiếm những người dùng có hành vi giống bạn và đề xuất những gì họ thích. Ví dụ, nếu cả Alice và Bob đều thích The Matrix và Inception, và Alice cũng thích Interstellar, hệ thống sẽ gợi ý Interstellar cho Bob.
- Lọc dựa trên nội dung (Content-based filtering): Nhìn vào các đặc điểm của những gì bạn đã thích và tìm kiếm những thứ tương tự. Nếu bạn xem nhiều video nấu ăn, nó sẽ đưa ra nhiều video được gắn thẻ "nấu ăn", "công thức" hoặc "kỹ thuật dùng dao".
Các nền tảng thực tế pha trộn các phương pháp này với hàng trăm tín hiệu khác. Nhưng ý tưởng cốt lõi vẫn giống nhau: học từ hành vi của bạn, dự đoán điều gì khác có thể thu hút bạn.
Thuật toán không có ý định hiển thị cho bạn nội dung xấu hoặc giả mạo. Nó tối ưu hóa cho sự tương tác. Và một trong những cách chắc chắn nhất để giữ con người tương tác là khai thác cảm xúc của chúng ta, đặc biệt là những cảm xúc tiêu cực mạnh mẽ.
Xây Dựng Trình Gợi Ý Tin Tức Trên Dữ Liệu Thực
Thay vì nói lý thuyết suông, hãy cùng xây dựng một hệ thống. Chúng ta sẽ sử dụng nhật ký nhấp chuột ẩn danh thực tế từ Microsoft News. Bộ dữ liệu này gọi là MIND (Microsoft News Dataset), chứa 50.000 người dùng, hơn 51.000 bài báo tiếng Anh và 156.000+ phiên hiển thị.
Về cơ bản, chúng ta sử dụng Python để tính toán độ tương đồng cosin giữa các người dùng. Độ tương đồng cosin tìm kiếm 50 hàng xóm gần nhất của bạn - những người nhấp vào các loại bài báo giống bạn. Chúng ta lấy các bài viết họ đã nhấp, đánh trọng số chúng dựa trên mức độ tương đồng của hàng xóm đó với bạn, và phục vụ 15 bài viết hàng đầu.
Đây là nền tảng của một ngành công nghiệp tỷ đô.
Độ tương đồng cosin là gì?
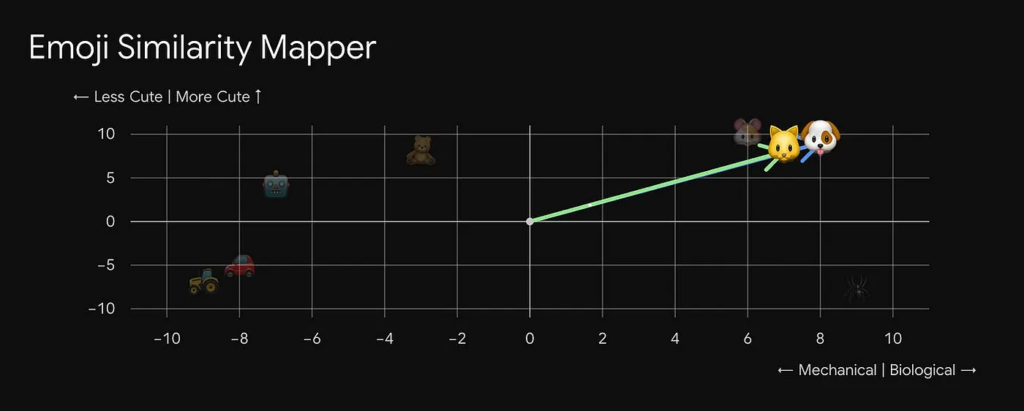
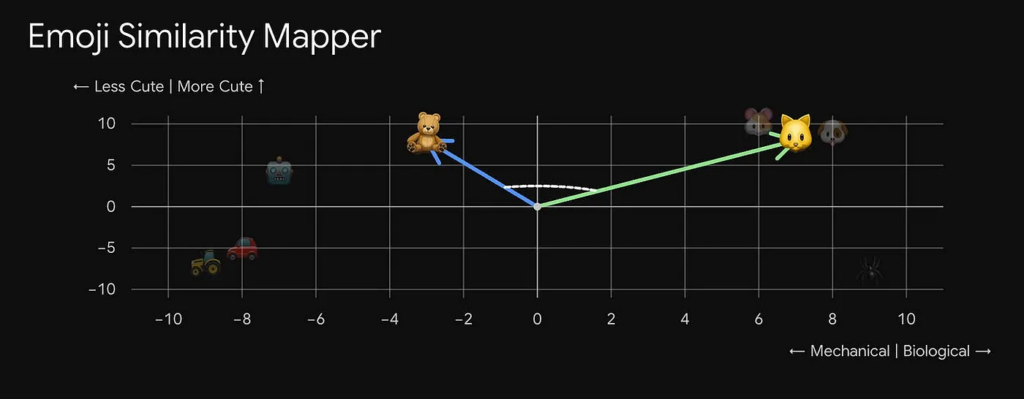
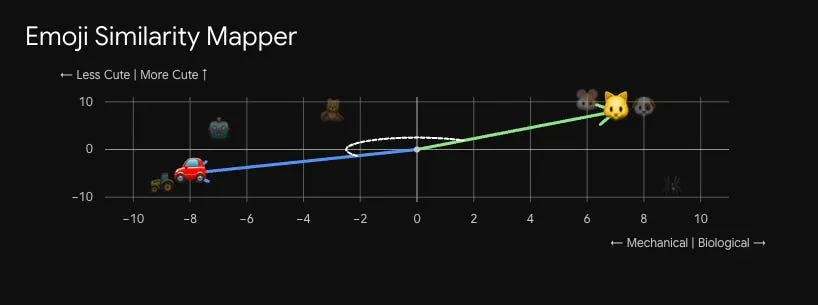
Độ tương đồng cosin có vẻ giống một khái niệm trong sách giáo khoa toán học, nhưng hãy kiên nhẫn, nó dễ hiểu hơn bạn nghĩ. Hãy tưởng tượng các điểm dữ liệu được rải rác trên hai trục: "cơ học" và "sinh học", cùng với mức độ "dễ thương".
Độ tương đồng cosin đo góc giữa hai mũi tên, mỗi mũi tên bắt đầu từ gốc tọa độ (0,0) và chỉ về một trong các điểm dữ liệu của chúng ta. Góc giữa chúng càng nhỏ, hai mục càng tương tự nhau.
Nếu hai mũi tên gần như chỉ theo cùng một hướng, các mục chúng đại diện chia sẻ các đặc điểm tương tự. Ví dụ, mèo và chó đều có điểm cao về "sinh học" và "dễ thương", nên mũi tên của chúng chỉ theo gần cùng một hướng. Nhưng nếu so sánh mèo với gấu bông, chúng khác nhau trên trục sinh học, làm kéo giãn mũi tên của chúng ra xa nhau.
Các mô hình AI sử dụng loại thông tin này để đề xuất nội dung có khả năng kích hoạt phản ứng tương tự ở bạn. Nếu bạn nhấp vào một video chính trị khiến bạn tức giận và xem hết nó, nền tảng sẽ ghi nhận cả hai chiều: chủ đề và phản ứng cảm xúc. Sử dụng độ tương đồng cosin, nó tìm thấy các video khác có "mũi tên" chỉ theo cùng hướng đó và phục vụ chúng cho bạn tiếp theo.
Thí Nghiệm Với Người Dùng U92876: Cổ Động Viên Thể Thao
Tôi đã chọn một người dùng từ bộ dữ liệu MIND có lịch sử đọc bài thuần túy là thể thao: bảng xếp hạng NFL, tin đồn chuyển nhượng NBA, lệnh cấm MLB. Người này đã đọc 25 bài báo, tất cả đều về thể thao.
Khi yêu cầu hệ thống gợi ý, kết quả cho thấy:
- 40% thể thao
- 13% tin tức
- 13% ô tô
- 34% rải rác mọi thứ khác.
Thuật toán nhận ra thói quen thể thao của người này và phản hồi lại, nhưng nó cũng cung cấp một chế độ ăn uống khá đa dạng. Có chính trị, giải trí, phong cách sống, tài chính. Không tệ, đúng không?
Khoảnh Khắc Tò Mò và Trọng Số Thời Gian
Tôi đã mô phỏng một điều gì đó phổ biến hơn nhiều so với việc "lạc sâu" vào một chủ đề: một khoảnh khắc tò mò nhàn nhã. Cổ động viên thể thao của chúng ta không dành hàng giờ để đọc chính trị. Họ chỉ đơn giản là nhấp vào 3 mục bắt mắt:
- Tin tức về Joe Biden.
- Tin tức về Mitch McConnell.
- Video về các cuộc tấn công của Trump.
Chỉ 3 cú nhấp trong chưa đầy 10 phút. Nếu chúng ta chạy các cú nhấp này qua mã Python cơ bản, không có gì đáng kể xảy ra. Về mặt toán học, 25 cú nhấp thể thao lịch sử vẫn sẽ lấn át 3 cú nhấp chính trị mới.
Tuy nhiên, đây là bí mật gia vị rất quan trọng của mạng xã hội hiện đại: Trọng số gần đây (Recency Weighting) hay Sự suy giảm theo thời gian.
Các thuật toán thực sự không đối xử với tất cả các cú nhấp của bạn như nhau. Một cú nhấp bạn thực hiện 3 năm trước là lịch sử cổ đại; một cú nhấp bạn thực hiện 3 phút trước là vàng ròng. Để giữ bạn bị cuốn hút trong phiên hiện tại, các nền tảng áp dụng một hệ số nhân lớn cho bất cứ điều gì bạn đang làm gần đây.
Nếu chúng ta áp dụng trọng số thời gian (ví dụ: cú nhấp gần đây quan trọng hơn 100 lần), hãy chạy lại các đề xuất:
Kết quả gây sốc: Tin tức chính trị tăng từ 13% lên 40% nguồn cấp dữ liệu. Một sự gia tăng 3 lần chỉ từ một buổi tối nhấp và đọc 3 bài báo. Thể thao (món ăn tinh thần của người này trong nhiều năm) có thể tụt từ vị trí thống trị xuống vị trí thứ hai.
Thuật toán không dừng lại để suy nghĩ "khoan đã, người này có 25 bài thể thao trong lịch sử". Nó không suy nghĩ, nó chỉ tính toán lại các ma trận tương đồng có trọng số thời gian, tìm thấy một tập hợp hàng xóm mới và phục vụ những gì họ thích.
Hai điều nổi bật:
- Tốc độ: Có thể chỉ mất một buổi tối để lật đổ hoàn toàn cấu thành nguồn cấp của một người dùng.
- Những gì biến mất: Điều này không chỉ là về thuật toán thêm vào gì, mà còn là về nó loại bỏ gì. Chế độ ăn thông tin của người dùng không chỉ trở nên chính trị hơn, nó trở nên hẹp hơn. Và sự hẹp hơn mới là mối nguy hiểm thực sự ở đây.
Thiên Khuynh Tiêu Cực và Tác Động Nhận Thức
 Tác động của thuật toán đến nhận thức
Tác động của thuật toán đến nhận thức
Bạn đã biết cách các cú nhấp ảnh hưởng đến toán học của thuật toán. Nhưng điều này còn tồi tệ hơn — nội dung khiến chúng ta tức giận, sợ hãi hoặc sốc dán chặt chúng ta vào màn hình tốt hơn nhiều so với nội dung khiến chúng ta cảm thấy tốt hoặc được thông tin.
Một nghiên cứu lớn năm 2025 phân tích dữ liệu kỹ thuật số của 25.000 người dùng SmartNews đã tìm thấy rằng con người có "thiên kiến tiêu cực" (negativity bias) khi chọn tin tức. Về mặt tiến hóa, chúng ta được lập trình để chú ý đến các mối đe dọa. Nghiên cứu xác nhận rằng các nguồn cấp tin tức được cá nhân hóa lấy thiên kiến tiêu cực vốn có của chúng ta và tăng cường nó.
Hơn nữa, dữ liệu từ các nền tảng như Facebook và X cho thấy người dùng mạng xã hội có khả năng chia sẻ liên kết tin tức tiêu cực cao hơn 1,91 lần so với tin tức tích cực. Tiêu cực tính bằng tính lan truyền, và vòng lặp phẫn nộ được sinh ra.
Tác động của các vòng lặp thuật toán này không chỉ là về loại nội dung chúng ta tiêu thụ; nó là về cách nó thay đổi cơ bản não bộ của chúng ta. Một bài tổng hợp hệ thống năm 2025 về các nguồn cấp video ngắn (như TikTok, Instagram Reels) cho thấy các hậu quả nhận thức sâu sắc. Việc tương tác nhiều với các nền tảng cuộn vô tận này liên quan đến hiệu suất nhận thức kém hơn, cụ thể là ảnh hưởng đến sự chú ý bền bỉ và khả năng kiểm soát ức chế.
Người dùng nặng các nền tảng này cho thấy hoạt động điện sinh lý giảm trong các nhiệm vụ đòi hỏi sự chú ý. Một số nhà nghiên cứu thậm chí chỉ ra sự khác biệt về cấu trúc ở các vùng kiểm soát nhận thức chính, bao gồm vỏ não trước trán và mạch lương thưởng vỏ striatum.
Chi Phí Xã Hội và Cách Giải Phóng Nguồn Cấp
Do các ma trận toán học, mỗi chúng ta đều nằm trong "bong bóng" thông tin được cá nhân hóa riêng của mình. Khi các thuật toán cho chúng ta xem nội dung xác nhận những gì chúng ta đã tin, chúng ta trải nghiệm thiên kiến xác nhận trên steroid. Những bong bóng lọc này làm sâu sắc thêm sự chia rẽ xã hội. Thông tin sai lệch phát triển mạnh trong các vòng lặp khép kín vì những câu chuyện giả mạc không bị phơi bày trước sự kiểm tra bên ngoài bong bóng.
Bạn không bất lực ở đây. Thuật toán có phản hồi, nhưng có một vài điều bạn có thể làm để thoát khỏi bong bóng của mình:
- Đa dạng hóa đầu vào: Chủ động theo dõi một vài nguồn ngoài vùng an toàn của bạn.
- Đặt lại định kỳ: Xóa lịch sử xem của bạn. Sử dụng "Không quan tâm" trên các gợi ý.
- Sử dụng nguồn cấp theo thời gian: Hầu hết các nền tảng vẫn cho phép bạn tắt xếp hạng thuật toán và chỉ xem bài đăng theo thứ tự thời gian.
- Tạm dừng trước khi chia sẻ: Mỗi lượt thích, bình luận và chia sẻ là một phiếu bầu cho "thêm cái này nữa". Nếu điều gì đó khiến bạn phẫn nộ, đó chính là lúc thuật toán có khả năng đang khai thác bạn nhất.
- Giới hạn thời gian: Đặt giới hạn thời gian màn hình. Ít phụ thuộc vào nguồn cấp dữ liệu, nó càng có ít quyền lực để định hình niềm tin của bạn.
Bước đầu tiên để phá vỡ sự ràng buộc đơn giản là nhận thức. Lần tới khi bạn thấy mình trong một cơn cuồng trực tuyến, hãy hít thở sâu và hỏi: Tại sao tôi lại thấy cái này? Ai lợi ích từ việc tôi phản ứng như thế này? Câu trả lời thường xuyên truy ngược về một thuật toán đang làm việc của nó, và công việc đó hiếm khi là "thông báo cho bạn".
Bài viết liên quan

Công nghệ
Camp Snap 2: Máy ảnh kỹ thuật số không màn hình mỏng hơn, thêm nhiều bộ lọc và màu sắc trong suốt
02 tháng 6, 2026

Công nghệ
Bị AI từ chối hồ sơ xin việc? Cuộc chiến đơn độc của một sinh viên y khoa
05 tháng 5, 2026
Công nghệ
Chủ đề từ LLM không phải là dữ liệu quan sát: Cảnh báo cho các nhà phân tích dữ liệu
21 tháng 5, 2026