
Giải thích Hồi quy Tuyến tính bằng Hình ảnh: Hướng dẫn Toàn diện cho Người mới bắt đầu
Bài viết cung cấp cái nhìn trực quan sâu sắc về Hồi quy tuyến tính (Linear Regression), một thuật toán cốt lõi trong Học máy. Nội dung bao gồm cách xây dựng mô hình, đánh giá chất lượng thông qua các chỉ số và biểu đồ, cùng các phương pháp cải thiện hiệu suất.
Hồi quy tuyến tính (Linear Regression) thường được coi là bài toán "Xin chào" của thế giới Học máy (Machine Learning). Dù có vẻ đơn giản, đây là một kỹ thuật thống kê mạnh mẽ giúp chúng ta hiểu mối quan hệ giữa các biến số và đưa ra dự đoán. Bài viết này sẽ tổng hợp lại những điểm chính từ một hướng dẫn chi tiết, sử dụng hơn 100 hình ảnh minh họa để giải thích cách hoạt động của thuật toán này một cách trực quan nhất.
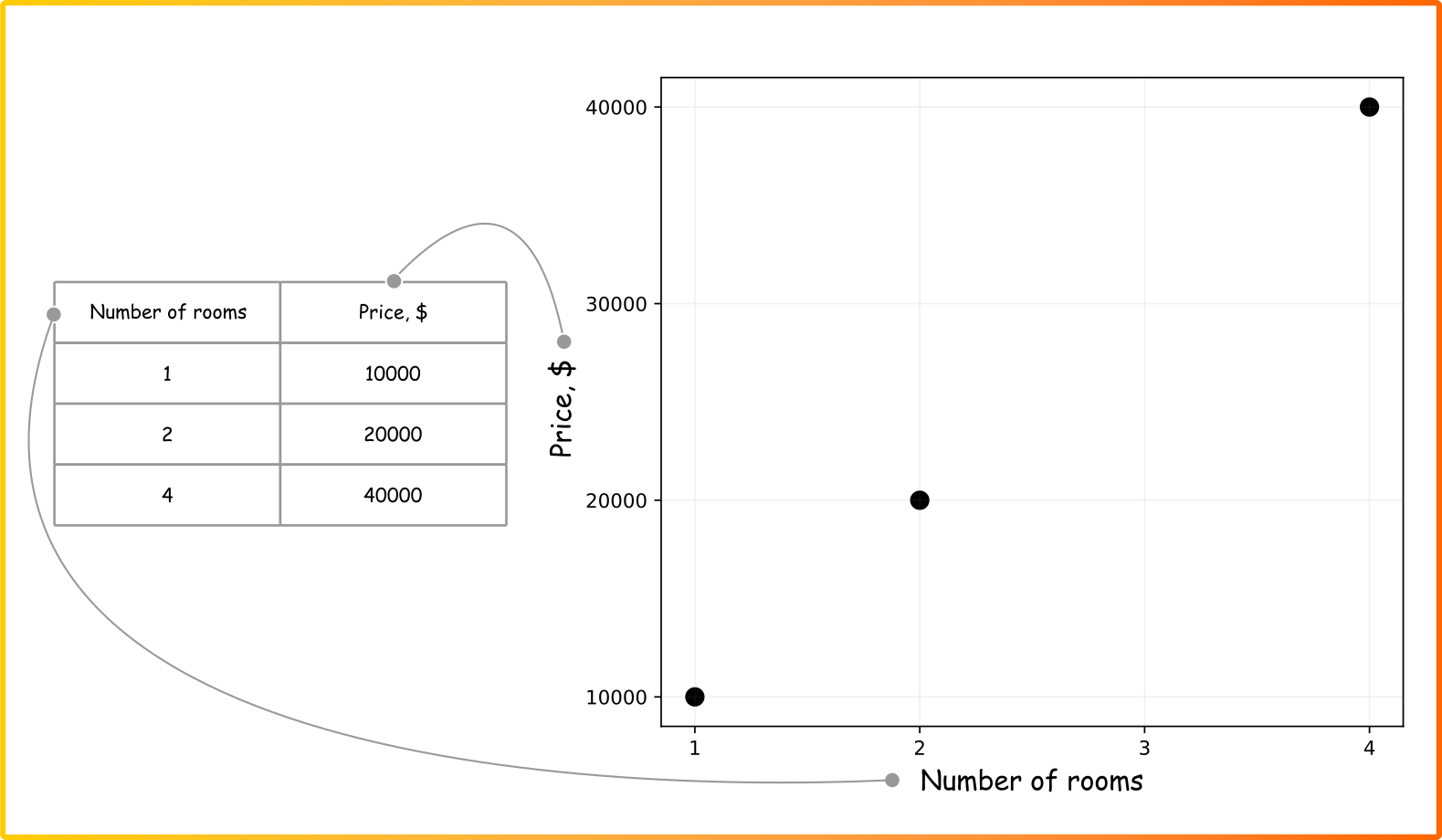 Dữ liệu ban đầu về giá căn hộ
Dữ liệu ban đầu về giá căn hộ
Mô hình tốt bắt đầu từ dữ liệu
Trước khi bàn về thuật toán, yếu tố quan trọng nhất chính là dữ liệu. Trong ví dụ này, chúng ta sử dụng một bộ dữ liệu giả lập gồm hai cột: số lượng phòng ngủ và giá của căn hộ. Nguyên tắc "rác vào, rác ra" (garbage in, garbage out) luôn đúng; một mô hình chỉ có thể tốt nếu dữ liệu đầu vào đủ chất lượng.
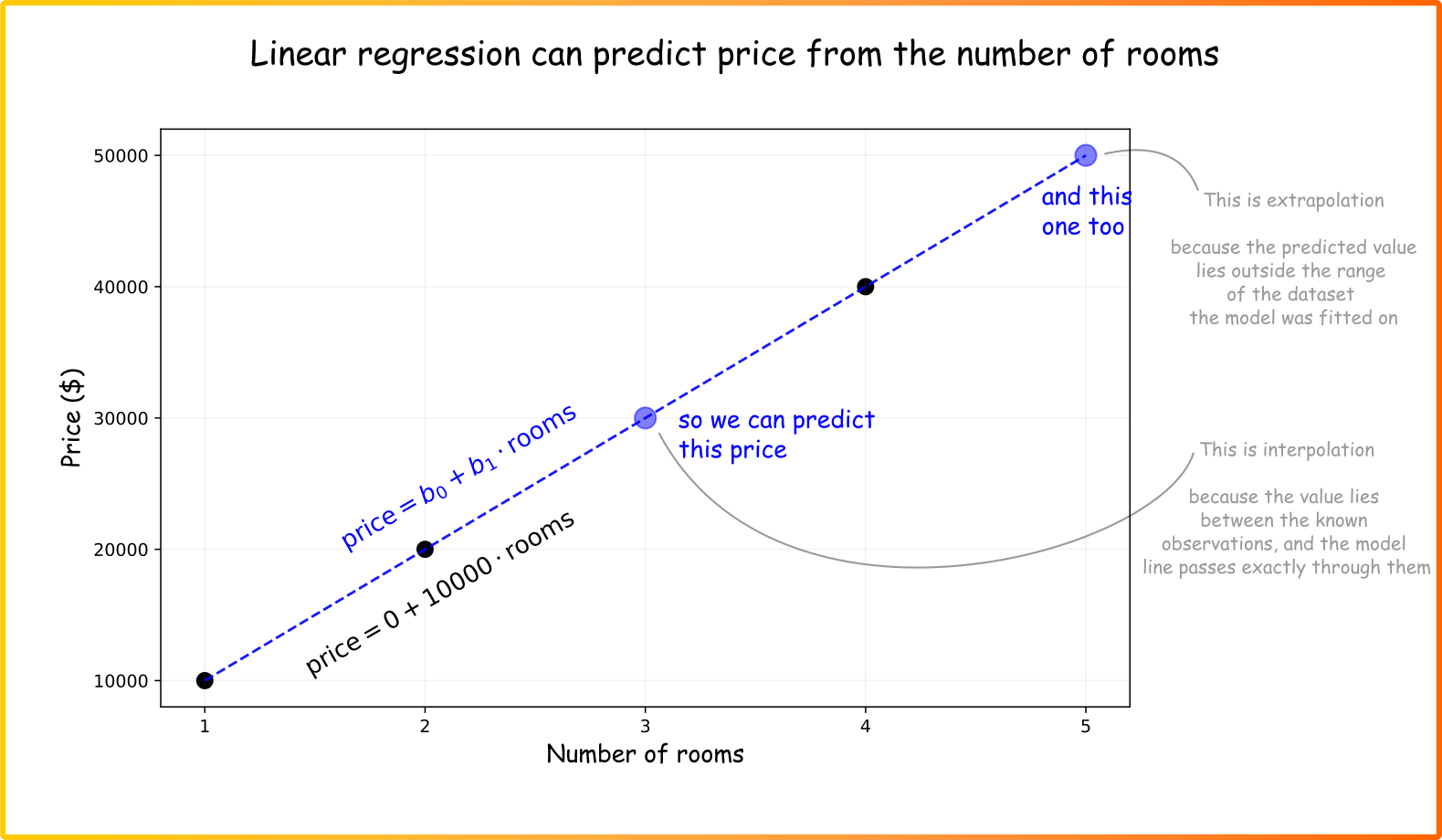
Mục tiêu của chúng ta là tìm ra một mô hình toán học để mô tả mối quan hệ giữa số phòng (đặc tính - feature) và giá nhà (biến mục tiêu - target). Trong hồi quy tuyến tính đơn giản, mối quan hệ này được biểu diễn bằng một đường thẳng có phương trình:
y = b0 + b1 * x
Trong đó:
- y là giá trị dự đoán (giá nhà).
- x là đặc tính đầu vào (số phòng).
- b0 là hệ số chặn (intercept) - điểm cắt trên trục tung.
- b1 là hệ số góc (slope) - độ thay đổi của y khi x thay đổi.
Tại sao chúng ta cần mô hình?
Như nhà thống kê George Box đã nói: "Mọi mô hình đều sai, nhưng một số mô hình lại hữu ích". Mô hình giúp chúng ta phát hiện các mẫu ẩn trong dữ liệu và sử dụng chúng để dự đoán tương lai. Tuy nhiên, cần lưu ý rằng hồi quy tuyến tính là một phương pháp xấp xỉ (approximation). Đường thẳng của mô hình không nhất thiết phải đi qua chính xác từng điểm dữ liệu, vì dữ liệu thực tế luôn chứa nhiễu và các yếu tố không thể quan sát được.
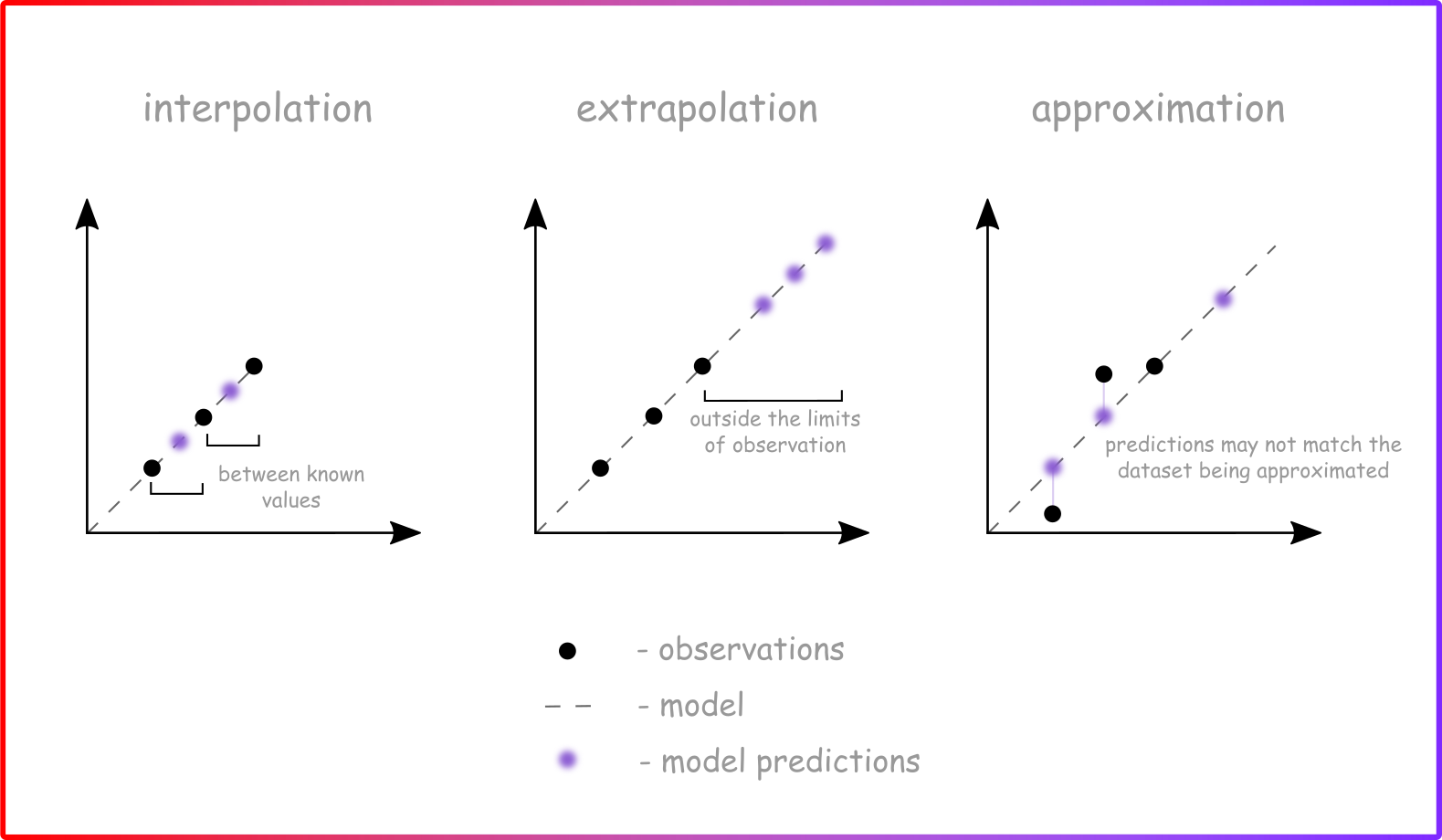 Sự khác biệt giữa nội suy, ngoại suy và xấp xỉ
Sự khác biệt giữa nội suy, ngoại suy và xấp xỉ
Hình ảnh trên minh họa rõ sự khác biệt giữa nội suy (interpolation), ngoại suy (extrapolation) và xấp xỉ (approximation). Trong hồi quy, chúng ta tìm kiếm sự xấp xỉ tốt nhất để tổng quát hóa dữ liệu.
Cách xây dựng mô hình đơn giản
Để xây dựng mô hình, chúng ta cần xác định các hệ số b0 và b1 sao cho đường thẳng khớp với dữ liệu thực tế tốt nhất. Phương pháp phổ biến nhất là sử dụng phương pháp bình phương tối thiểu (Ordinary Least Squares - OLS).
Ý tưởng cốt lõi của phương pháp này là tìm các hệ số sao cho tổng bình phương của các sai số (residuals) - tức là khoảng cách giữa điểm dữ liệu thực tế và đường thẳng mô hình - là nhỏ nhất. Đây là một giải pháp phân tích (analytical solution) kinh điển, thường được tính toán tự động bởi các thư viện lập trình.
 Đường hồi quy tuyến tính khớp với dữ liệu
Đường hồi quy tuyến tính khớp với dữ liệu
Đánh giá chất lượng mô hình
Sau khi có mô hình, làm thế nào để biết nó có tốt không? Chúng ta có hai cách tiếp cận chính: đánh giá bằng thị giác và đánh giá bằng các chỉ số (metrics).
Đánh giá thị giác
- Biểu đồ phân tán (Scatter plot): Vẽ các điểm dữ liệu thực tế và đường dự đoán trên cùng một biểu đồ. Đường càng gần các điểm thì mô hình càng tốt.
- Biểu đồ phần dư (Residual plot): Vẽ sai số (giá trị thực - giá trị dự đoán) trên trục tung và giá trị dự đoán trên trục hoành. Một mô hình tốt sẽ có các phần dư phân bố ngẫu nhiên quanh đường 0, không có mẫu hình rõ ràng nào.
Các giả định quan trọng
Để hồi quy tuyến tính hoạt động hiệu quả, dữ liệu cần thỏa mãn một số giả định:
- Tính tuyến tính: Mối quan hệ giữa biến độc lập và phụ thuộc là tuyến tính.
- Phần dư có phân phối chuẩn: Các sai số nên tuân theo phân phối Gauss (đối xứng quanh 0).
- Đồng phương sai (Homoscedasticity): Độ lệch của sai số là không đổi xuyên suốt các mức giá trị dự đoán.
Các chỉ số đánh giá (Metrics)
Ngoài thị giác, chúng ta cần các con số cụ thể để so sánh các mô hình:
- R-squared (Hệ số xác định): Cho biết mô hình giải thích được bao nhiêu phần trăm phương sai của dữ liệu. Gần 1 là tốt.
- RMSE (Root Mean Square Error): Trung bình bình phương của sai số. Chỉ số này nhạy cảm với các điểm ngoại lai (outliers) lớn.
- MAE (Mean Absolute Error): Trung bình trị tuyệt đối của sai số. Dễ hiểu hơn RMSE nhưng không trừng phạt các lỗi lớn quá mạnh.
Cải thiện chất lượng mô hình
Nếu mô hình chưa đạt yêu cầu, có nhiều cách để cải thiện:
- Mở rộng bộ dữ liệu: Thêm nhiều mẫu dữ liệu hơn để mô hình học được tổng quát tốt hơn.
- Xử lý điểm ngoại lai: Loại bỏ hoặc điều chỉnh các giá trị bất thường làm sai lệch đường hồi quy.
- Kỹ thuật đặc tính (Feature Engineering): Tạo ra các đặc tính mới từ dữ liệu cũ hoặc thêm các biến độc lập khác (Hồi quy đa tuyến tính - Multiple Linear Regression).
- Chính quy hóa (Regularization): Sử dụng các kỹ thuật như L1 (Lasso) hoặc L2 (Ridge) để ngăn chặn tình trạng quá khớp (overfitting), đặc biệt khi mô hình quá phức tạp.
Kết luận
Hồi quy tuyến tính là nền tảng vững chắc cho bất kỳ ai muốn bước vào lĩnh vực Khoa học dữ liệu. Thông qua việc hiểu rõ cách xây dựng, đánh giá và cải thiện mô hình, bạn không chỉ nắm được một thuật toán cụ thể mà còn tư duy tốt hơn về cách giải quyết các vấn đề dự đoán trong thực tế. Hãy nhớ rằng, không có mô hình nào hoàn hảo, nhưng việc hiểu sâu sắc về dữ liệu và sai số sẽ giúp bạn tạo ra những công cụ hữu ích.
Bài viết liên quan

Công nghệ
Các tác nhân AI đã khiến thế giới công nghệ chao đảo: Câu chuyện đằng sau cuộc cách mạng Claude Code và OpenClaw
26 tháng 5, 2026

Công nghệ
Threads cán mốc 500 triệu người dùng hoạt động hàng tháng
16 tháng 6, 2026

Công nghệ
Alienware 15 mới: Dell đang làm loãng thương hiệu cao cấp vì khủng hoảng RAM?
14 tháng 5, 2026