
Hệ thống Giám sát của bạn không bỏ lỡ sự cố, nó chưa bao giờ được thiết kế để nhìn thấy nó
Bài viết phân tích sâu về sự khác biệt giữa Giám sát truyền thống và Observability (Khả năng quan sát) trong các hệ thống hiện đại. Thay vì chỉ chờ đợi các chỉ số vượt ngưỡng, các kỹ sư cần tập trung vào các tín hiệu hành vi tinh vi để phát hiện sự suy giảm hệ thống trước khi nó trở thành thảm họa.

Hệ thống Giám sát của bạn không bỏ lỡ sự cố, nó chưa bao giờ được thiết kế để nhìn thấy nó
Tôi đã chứng kiến cuộc tranh luận giữa Observability (Khả năng quan sát) và Monitoring (Giám sát) diễn ra thành một sự cố thực tế nhiều lần hơn tôi có thể đếm được.
Bảng điều khiển (dashboard) vẫn hiển thị màu xanh an toàn. Kỹ sư trực chiến (on-call engineer) không nhận được bất kỳ thông báo (page) nào. Hệ thống giám sát đã làm chính xác những gì nó được thiết kế để làm: giám sát các ngưỡng (thresholds), chờ đợi các chỉ số vượt qua chúng, và giữ im lặng khi chúng không làm vậy.
Vấn đề nằm ở chỗ: các hệ thống hiện đại không còn bị lỗi theo cách vượt qua các ngưỡng đó nữa.
Chúng thất bại bằng cách cư xử khác biệt.
Độ trễ (latency) không phóng vọt — nó trôi dạt đi. Tỷ lệ lỗi không bùng nổ — chúng phân tán rải rác. Chi phí không tăng vọt trong một sự kiện duy nhất — nó tích lũy qua hàng ngàn quyết định nhỏ.
Đến khi một cảnh báo truyền thống được kích hoạt, hệ thống không chỉ suy giảm mà nó đã vượt qua điểm mà việc khôi phục trở nên đơn giản.
Đây không phải là khoảng cách về công cụ. Đây là sự không khớp về mô hình.
Hệ thống giám sát của bạn được xây dựng cho các hệ thống hỏng hóc một cách "ồn ào". Các hệ thống của bạn hiện nay hỏng một cách "yên lặng".
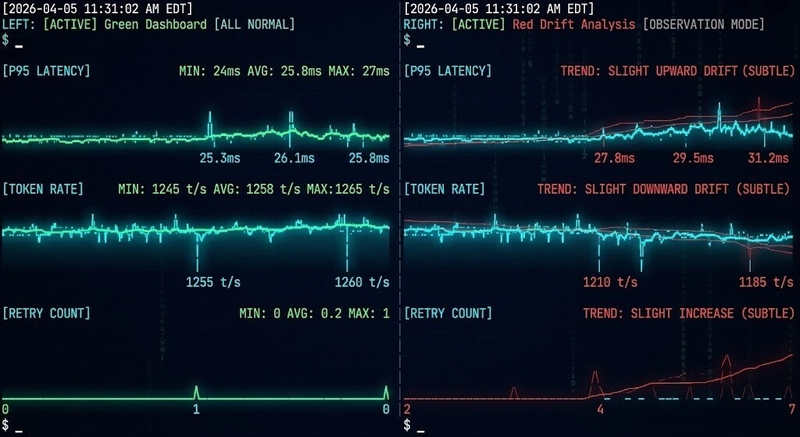 Observability so với Monitoring - Bảng điều khiển hiển thị các chỉ số khỏe mạnh trong khi hành vi hệ thống đang trôi dạt
Observability so với Monitoring - Bảng điều khiển hiển thị các chỉ số khỏe mạnh trong khi hành vi hệ thống đang trôi dạt
Observability so với Monitoring: Sự khác biệt về Mô hình
Giám sát trả lời một câu hỏi nhị phân: Có cái gì đó bị hỏng không?
Observability trả lời một câu hỏi khác: Có cái gì đó đang trở nên hỏng không?
Đó không phải là cùng một câu hỏi. Chúng yêu cầu các công cụ đo lường (instrumentation) khác nhau, thiết kế tín hiệu khác nhau và một mô hình tư duy khác nhau về ý nghĩa của sự "khỏe mạnh".
Giám sát dựa trên ngưỡng là mô hình đúng cho một lớp hệ thống cụ thể. Một máy chủ bị tắt — chỉ số vượt qua giới hạn, cảnh báo kích hoạt, kỹ sư phản hồi. Mô hình này hoạt động vì các hệ thống nó theo dõi thường hỏng theo cách đó.
Các hệ thống phân tán hiện đại thì không. Một microservice không bị tắt — nó chậm lại, một cách không nhất quán, đối với một tập hợp con các yêu cầu. Một đường ống suy luận AI (inference pipeline) không dừng lại — nó bắt đầu đưa ra các quyết định định tuyến tốn kém hơn, từng yêu cầu một. Một cụm Kubernetes không thất bại — nó bắt đầu lên lịch kém hiệu quả hơn khi áp lực tài nguyên tích tụ trên các node.
Không có điều kiện nào trong số đó vượt qua một ngưỡng. Chúng dịch chuyển một phân phối. Và một hệ thống giám sát được xây dựng dựa trên logic ngưỡng sẽ báo cáo màu xanh trên một hệ thống đang suy giảm tích cực — không phải vì công cụ bị hỏng, mà vì nó đang đo lường sai thứ.
Đây là hậu quả kiến trúc của khoảng cách giữa Observability và Monitoring: những hệ thống cần khả năng hiển thị nhất lại là những hệ thống được phục vụ kém nhất bởi cảnh báo truyền thống. Mô hình các hệ thống trôi dạt trước khi chúng bị hỏng là vô hình đối với logic ngưỡng — đó là một thay đổi theo hướng tích lũy theo thời gian cho đến khi việc khôi phục trở nên tốn kém.
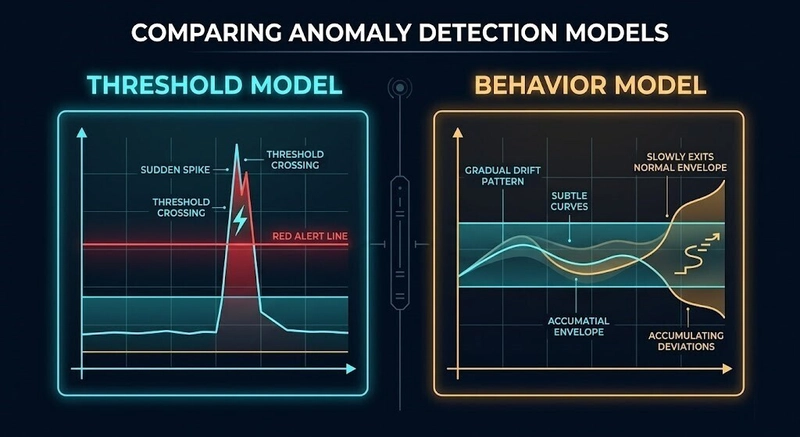 Observability so với Monitoring - Mô hình ngưỡng so với phát hiện trôi dạt hành vi
Observability so với Monitoring - Mô hình ngưỡng so với phát hiện trôi dạt hành vi
Sự hỏng hóc hiện đại trông như thế nào
Cách rõ ràng nhất để hiểu khoảng cách giữa Observability và Monitoring là nhìn vào việc sự hỏng hóc thực sự diễn ra như thế nào trong môi trường sản xuất (production) ngày nay.
Trong các hệ thống suy luận AI, sự hỏng hóc hiếm khi tự công bố. Việc tiêu thụ token tăng dần khi các bước truy xuất (retrieval steps) được thêm vào mà không có việc dọn dẹp tương ứng. Định tuyến mô hình chuyển sang các đường đắt tiền hơn khi các ngưỡng độ tin cậy (confidence thresholds) trôi dạt. Logic thử lại (retry logic) kích hoạt thường xuyên hơn khi độ trễ thượng nguồn tăng, khuếch đại tải trên các thành phần đang bị áp lực. Không có cái nào tạo ra cảnh báo. Tất cả đều tạo ra chi phí. Chi phí suy luận xuất phát từ hành vi, không phải việc cung cấp (provisioning) — và chi phí driven bởi hành vi là vô hình đối với các hệ thống chỉ theo dõi tài nguyên được cung cấp.
Trong môi trường Kubernetes, lớp hạ tầng vẫn đánh lừa là khỏe mạnh trong khi lớp workload suy giảm. Việc sử dụng CPU và bộ nhớ trông bình thường. Việc khởi động lại Pod nằm trong dung sai. Kiểm tra sức khỏe cụm trả về màu xanh. Trong khi đó, độ trễ P95 đang leo thang, sự phân tán yêu cầu (request fan-out) tăng lên, và một tập con cụ thể các dịch vụ đang tiếp cận mức bão hòa. Kubernetes hiển thị trạng thái hạ tầng, không phải sự trôi dạt hành vi — khoảng cách giữa "cụm khỏe mạnh" và "ứng dụng đang suy giảm" chính là nơi các sự cố hiện đại tồn tại.
Trong các hệ thống phân tán nói chung, mô hình hỏng hóc là sự lệch pha tích lũy (compounding deviation). Tỷ lệ cache miss tăng hai phần trăm mỗi tuần. Tỷ lệ thử lại tăng nhẹ sau mỗi lần triển khai. Một đường ống lô (batch pipeline) mất thêm vài giây mỗi lần chạy. Riêng lẻ, không có cái nào đăng ký. Cùng nhau, chúng mô tả một hệ thống di chuyển đều đặn đến trạng thái hỏng hóc — các chỉ số cấp hạ tầng có thể vẫn ổn định trong khi hành vi hệ thống suy giảm.
Chung quy lại: hệ thống trông khỏe mạnh cho đến khi không còn. Và khi nó không còn, sự hỏng hóc không phải mới — đó là kết quả tích lũy của một sự trôi dạt bắt đầu từ vài tuần trước.
Tại sao tầm nhìn về Chi phí bị phá vỡ
Chi phí là một trong những tín hiệu rõ ràng nhất của sự trôi dạt hành vi — và cũng là một trong những tín hiệu thường xuyên bị hiểu sai nhất.
Giám sát chi phí truyền thống theo dõi số tiền chi tiêu. Khi hóa đơn tăng, cảnh báo kích hoạt. Vấn đề là chi phí là một chỉ báo độ trễ (lagging indicator). Đến khi nó xuất hiện trên bảng điều khiển thanh toán, hành vi tạo ra nó đã chạy trong nhiều ngày, đôi khi là nhiều tuần.
Hầu hết các stack không có lớp đo lường nào giữa hành vi tạo ra chi phí và hóa đơn báo cáo nó.
Đối với các hệ thống AI, khoảng cách này tồi tệ hơn về mặt cấu trúc. Ngân sách thực thi áp đặt giới hạn tại thời gian chạy — nhưng một ngân sách bạn không thể thấy đang được tiêu thụ là một ngân sách sẽ bị vượt qua trước khi bạn biết nó có rủi ro. Tốc độ đốt token, tần suất lựa chọn mô hình, sự khuếch đại thử lại trên các lệnh gọi suy luận — đây là các tín hiệu hành vi dự đoán quỹ đạo chi phí. Không cái nào xuất hiện trong cảnh báo thanh toán.
Giải pháp không phải là các cảnh báo thanh toán tốt hơn. Đó là các công cụ đo lường nắm bắt hành vi tạo ra chi phí tại điểm nó xảy ra — trước khi nó tổng hợp thành một khoản phí.
Tại sao hệ thống AI làm rộng khoảng cách Observability vs Monitoring
Các hệ thống suy luận AI không chỉ phơi bày khoảng cách — chúng làm rộng nó.
Lý do cốt lõi là các quyết định định tuyến mô hình phụ thuộc vào tín hiệu thời gian chạy. Một lớp định tuyến được thiết kế tốt hướng các yêu cầu đơn giản đến các mô hình nhẹ và nâng cấp các yêu cầu phức tạp. Nhưng logic định tuyến đó phụ thuộc vào các tín hiệu thời gian chạy — điểm số độ tin cậy, độ phức tạp truy vấn, độ dài ngữ cảnh — vốn vô hình đối với hạ tầng giám sát truyền thống.
Khi định tuyến bắt đầu chuyển dịch — nhiều yêu cầu hơn được nâng cấp lên các mô hình đắt tiền, đường dự phòng (fallback paths) kích hoạt thường xuyên hơn, các ngưỡng độ tin cậy trôi dạt — stack giám sát không thấy cái nào. Việc sử dụng CPU vẫn phẳng. Áp lực bộ nhớ vẫn bình thường. Tín hiệu duy nhất nằm trong các quyết định định tuyến chính nó, và hầu hết các đội ngũ hạ tầng không có công cụ đo lường ở lớp đó.
Điều này tạo ra một chế độ hỏng hóc cụ thể: hệ thống về mặt kỹ thuật là khỏe mạnh, về mặt vận hành đang suy giảm, và tạo ra chi phí ngày càng tăng — và stack không thể thấy cái nào vì nó không bao giờ được thiết kế để theo dõi các mẫu quyết định, chỉ có mức tiêu thụ tài nguyên.
5 Tín hiệu dự đoán sự hỏng hóc trước khi nó xảy ra
 Năm tín hiệu hạ tầng dự đoán sự cố trước khi cảnh báo kích hoạt
Năm tín hiệu hạ tầng dự đoán sự cố trước khi cảnh báo kích hoạt
Các hệ thống hiện đại không cung cấp cho bạn một tín hiệu hỏng hóc duy nhất. Chúng cung cấp các mẫu — những sự lệch lạc tinh vi, tích lũy khỏi hành vi mong đợi. Đây là các tín hiệu xuất hiện trước sự cố, không phải trong khi nó diễn ra.
Tín hiệu 01: Tốc độ tiêu thụ (Consumption Velocity)
Không phải là hệ thống tiêu thụ bao nhiêu — mà là mức tiêu thụ thay đổi nhanh như thế nào. Tốc độ đốt token, tần suất gọi API và xử lý nền tăng chậm trước khi bất kỳ ngưỡng nào bị vượt qua. Hệ thống không hỏng khi nó tiêu thụ quá nhiều. Nó hỏng khi tiêu thụ tăng tốc mà không có phản hồi kiểm soát tương ứng.
Tín hiệu 02: Sự trôi dạt phân phối (Distribution Drift)
Giá trị trung bình (average) nói dối. Hầu hết các bảng điều khiển hiển thị độ trễ trung bình, thời gian phản hồi trung bình, chi phí trung bình cho mỗi yêu cầu. Sự hỏng hóc sống trong phân phối — P95 leo thang trong khi trung bình vẫn phẳng, một tập hợp con các yêu cầu trở nên chậm và nặng hơn. Hệ thống trung bình trông khỏe mạnh. Phần đuôi (tail) đã hỏng rồi.
Tín hiệu 03: Thay đổi mẫu quyết định
Các hệ thống hiện đại đưa ra quyết định — định tuyến mô hình, thử lại, dự phòng, kích hoạt mở rộng (scaling). Khi những quyết định đó thay đổi, cái gì đó ở thượng nguồn đã thay đổi rồi. Nhiều yêu cầu hơn định tuyến đến mô hình đắt tiền. Đường dự phòng kích hoạt thường xuyên hơn. Thử lại tăng mà không có các đỉnh lỗi tương ứng. Khi hệ thống bắt đầu chọn khác đi, nó đã chịu áp lực rồi.
Tín hiệu 04: Sự khuếch đại thử lại (Retry Amplification)
Thử lại không xuất hiện dưới dạng thất bại — chúng xuất hiện dưới dạng nhiều công việc hơn. Một thất bại tạo ra ba lần thử lại. Ba lần thử lại tạo ra áp lực hạ lưu. Áp lực hạ lưu tạo ra nhiều lần thử lại hơn. Vòng lặp tích lũy: thất bại → thử lại → khuếch đại → suy giảm hệ thống. Đến khi tỷ lệ lỗi tăng vọt, hệ thống đã bão hòa rồi. Thử lại không chỉ phản hồi thất bại ở quy mô. Chúng tạo ra nó.
Tín hiệu 05: Tỷ lệ Cache Miss
Cache là lớp hiệu quả của hệ thống bạn. Khi tỷ lệ hit giảm — cache KV trong suy luận LLM, cache ngữ nghĩa trong các đường ống RAG, cache CDN hoặc đối tượng — tính toán, độ trễ và chi phí đều tăng. Không cái nào tăng vọt ngay lập tức. Chúng tăng dần khi hệ thống mất khả năng tái sử dụng công việc. Hệ thống không chậm trước. Chúng kém hiệu quả trước.
Cần đo lường những gì
Biết các tín hiệu là cần thiết. Biết nơi nắm bắt chúng là câu hỏi vận hành. Bốn điểm đo lường sau sẽ đóng phần lớn khoảng cách Observability và Monitoring cho các hệ thống AI và phân tán hiện đại.
OpenTelemetry Collector — đường cơ sở để nắm bắt dữ liệu hành vi cấp trace trên các dịch vụ. Without distributed tracing, sự trôi dạt phân phối và thay đổi mẫu quyết định là vô hình. OTEL cung cấp cho bạn tín hiệu cấp yêu cầu mà các chỉ số một mình không thể cung cấp.
Lớp Middleware Suy luận — tốc độ tiêu thụ token, tần suất lựa chọn mô hình, phân phối điểm số độ tin cậy và tỷ lệ thử lại nên được nắm bắt tại lớp suy luận — không suy ra từ các chỉ số hạ tầng. Nếu khung LLM của bạn không hiển thị chúng một cách nguyên bản, một lớp sidecar hoặc proxy nhẹ có thể đo lường chúng mà không cần sửa đổi mã ứng dụng.
Observability Hệ thống dựa trên eBPF — đối với môi trường Kubernetes, eBPF cung cấp khả năng hiển thị cấp hạt nhân vào hành vi mạng, mẫu lời gọi hệ thống và giao tiếp liên dịch vụ mà không có chi phí đo lường. Tỷ lệ cache miss và mẫu khuếch đại thử lại thường được nắm bắt chính xác nhất tại lớp này.
Cost Telemetry ở cấp Lời gọi — chi phí nên được đo tại điểm lời gọi API hoặc lệnh gọi suy luận — không tổng hợp tại thời gian thanh toán. Số lượng token, phân cấp mô hình và quyết định định tuyến nên được phát ra dưới dạng các sự kiện có cấu trúc và tương quan với dữ liệu trace. Đây là lớp đo lường đóng khoảng cách giữa hành vi và chi phí.
Hạ tầng trông có vẻ Khỏe mạnh
Đây là trạng thái nguy hiểm về mặt vận hành nhất mà một hệ thống có thể gặp phải.
Mọi chỉ số hạ tầng đều nằm trong dung sai. Kiểm tra sức khỏe cụm trả về màu xanh. Bảng điều khiển hiển thị mức sử dụng bình thường trên tính toán, bộ nhớ và mạng. Không có sự cố nào đang mở.
Trong khi đó, độ trễ P95 đã tăng 40% trong hai tuần qua. Tốc độ đốt token đã tăng 22%. Đường định tuyến dự phòng đang kích hoạt thường xuyên hơn gấp ba lần so với tháng trước. Một lớp cache đang hoạt động ở tỷ lệ hit 61%, giảm từ 89%.
Không có điều kiện nào trong số đó vượt qua một ngưỡng. Tất cả chúng đều là tín hiệu.
Sự hỏng hóc không sắp tới. Nó đang diễn ra rồi. Hệ thống giám sát chỉ không có lớp Observability để làm nổi bật nó.
Phán quyết của Kiến trúc sư
Khoảng cách giữa Observability và Monitoring trong các hệ thống AI và phân tán hiện đại không phải là thất bại của công cụ — đó là thất bại của mô hình. Giám sát dựa trên ngưỡng được thiết kế cho các hệ thống hỏng rời rạc và ồn ào. Các hệ thống hiện đại suy giảm liên tục và âm thầm. Năm tín hiệu được đề cập ở đây — tốc độ tiêu thụ, trôi dạt phân phối, thay đổi mẫu quyết định, khuếch đại thử lại và tỷ lệ cache miss — không phải là telemetry lạ lùng. Chúng là lớp hành vi nằm giữa "hạ tầng trông khỏe mạnh" và "hệ thống đang suy giảm". Đóng lại khoảng cách này yêu cầu mở rộng vượt ra ngoài các chỉ số tài nguyên sang dữ liệu trace, middleware suy luận và cost telemetry cấp lời gọi. Những kiến trúc sư xây dựng lớp đo lường đó trước một sự cố là những người sẽ nắm bắt sự trôi dạt trước khi nó tích lũy thành một cuộc khủng hoảng. Những người chờ đợi một ngưỡng bị vượt qua sẽ tiếp tục giải thích tại sao bảng điều khiển màu xanh khi hệ thống đã thất bại rồi. Bạn không cần thêm cảnh báo. Bạn cần các tín hiệu khác nhau.
Bài viết liên quan

Phần cứng
Gemma 4 áp dụng Multi-Token Prediction, tăng tốc độ suy luận lên tới 3 lần
25 tháng 5, 2026

Công nghệ
Các tác nhân AI đã khiến thế giới công nghệ chao đảo: Câu chuyện đằng sau cuộc cách mạng Claude Code và OpenClaw
26 tháng 5, 2026

Phần cứng
Nvidia chính thức đưa siêu vi xử lý Grace Blackwell lên PC với dòng notebook RTX Spark
01 tháng 6, 2026