
Hiểu sâu về Phân kỳ KL: Sáu rưỡi góc nhìn trực giác trong Học máy
Phân kỳ KL (KL Divergence) là một khái niệm cốt lõi trong lý thuyết thông tin và học máy, thường gây nhầm lẫn do tính không đối xứng của nó. Bài viết này tổng hợp sáu rưỡi cách tiếp cận trực giác khác nhau để giải thích khái niệm này, từ sự ngạc nhiên trong thống kê, mã hóa dữ liệu cho đến tối ưu hóa đặt cược. Việc hiểu rõ các khía cạnh này sẽ giúp người làm công nghệ nắm bắt sâu hơn về cách các mô hình đánh giá sự khác biệt giữa phân phối dự đoán và thực tế.
Phân kỳ Kullback-Leibler (KL Divergence) là một chủ đề xuất hiện ở rất nhiều nơi trong lý thuyết thông tin và học máy, vì vậy việc hiểu rõ nó là vô cùng quan trọng. Tuy nhiên, khái niệm này sở hữu những tính chất có vẻ khó hiểu ở cái nhìn đầu tiên, ví dụ như nó không đối xứng như các thước đo khoảng cách thông thường, và nó có thể không bị giới hạn khi xác suất tiến về 0.
Bài viết này sẽ tổng hợp sáu rưỡi cách trực giác khác nhau để giúp bạn hình dung về KL divergence, tìm ra những điểm chung tiềm ẩn giữa chúng. Hy vọng rằng dù bạn là nhà nghiên cứu hay kỹ sư, sẽ có ít nhất một góc nhìn mới mẻ giúp nâng cao sự hiểu biết của bạn.
 Minh họa trực quan về khái niệm toán học
Minh họa trực quan về khái niệm toán học
1. Sự ngạc nhiên (Surprise)
Đây có lẽ là trực giác gần gũi nhất. Hãy tưởng tượng bạn quan sát dữ liệu có phân phối thực tế là P, nhưng bạn lại lầm tưởng rằng nó tuân theo phân phối Q. KL divergence đo lường mức độ bạn "ngạc nhiên" nhiều hơn so với việc bạn biết đúng phân phối P.
Trong lý thuyết thông tin, "sự ngạc nhiên" (hay surprisal) của một sự kiện x có xác suất p_x được định nghĩa là $-\ln(p_x)$. Nếu một sự kiện xảy ra thường xuyên, sự ngạc nhiên sẽ thấp, và ngược lại.
Khi đó, KL divergence chính là sự khác biệt giữa sự ngạc nhiên trung bình mà mô hình sai lầm của bạn dự đoán và sự ngạc nhiên thực tế của thế giới. Điều này cũng giải thích tại sao KL divergence không đối xứng: Nếu mô hình Q gán xác suất rất thấp cho một sự kiện thường xuyên xảy ra trong P, bạn sẽ liên tục bị "sốc". Ngược lại, nếu Q gán xác suất cao cho một sự kiện hiếm khi xảy ra trong P, bạn không bị sốc thường xuyên vì sự kiện đó ít khi xuất hiện.
2. Kiểm định giả thuyết (Hypothesis Testing)
Trong bối cảnh thống kê, hãy tưởng tượng bạn có hai giả thuyết: giả thuyết null $H_0$ nói rằng dữ liệu tuân theo P, và giả thuyết thay thế $H_1$ nói rằng dữ liệu tuân theo Q. Nếu $H_0$ là đúng, KL divergence đại diện cho lượng bằng chứng (tính bằng bit) mà chúng ta mong đợi nhận được để ủng hộ $H_0$ hơn $H_1$.
Nói cách khác, nó đo lường khả năng chúng ta có thể phân biệt được hai phân phối P và Q dựa trên dữ liệu quan sát. Nếu P và Q càng gần nhau, chúng ta càng khó phân biệt và KL divergence sẽ càng thấp.
3. Ước lượng hợp lý tối đa (Maximum Likelihood)
Nếu P là phân phối thực nghiệm của dữ liệu và Q là một mô hình thống kê, thì việc tối thiểu hóa KL divergence giữa P và Q tương đương với việc tìm ra bộ tham số cho Ước lượng hợp lý tối đa (Maximum Likelihood Estimation - MLE).
Đây là lý do tại sao chúng ta thường sử dụng cross-entropy làm hàm mất mát (loss function) trong các mạng nơ-ron học sâu. Việc tối thiểu hóa cross-entropy chính là tối thiểu hóa KL divergence, giúp mô hình Q bắt chước càng sát càng tốt phân phối dữ liệu thực tế P.
4. Mã hóa nguồn (Source Coding)
Trong lý thuyết mã hóa, nếu bạn muốn nén một nguồn dữ liệu có phân phối P, bạn sẽ sử dụng các mã ngắn cho các sự kiện thường xuyên và mã dài cho các sự kiện hiếm. Độ dài mã tối ưu cho sự kiện x là $-\log_2(p_x)$.
KL divergence trong trường hợp này đo lường số bit mà bạn đang "lãng phí" nếu cố gắng nén dữ liệu thực tế là P bằng cách sử dụng một mã hóa được tối ưu hóa cho phân phối sai Q. Nếu P và Q rất khác nhau, bạn sẽ lãng phí rất nhiều dung lượng lưu trữ hoặc băng thông.
5. Cá cược tại sòng bạc (Casino Betting)
Hãy tưởng tượng một trò chơi may rủi nơi nhà cái (sòng bạc) tin rằng xác suất kết quả là Q, nhưng bạn biết chắc chắn xác suất thực tế là P. Nhà cái sẽ trả thưởng dựa trên niềm tin sai lầm Q của họ.
KL divergence đại diện cho lượng tiền (trong không gian logarit) mà bạn có thể kiếm được từ sòng bạc bằng cách khai thác sự khác biệt giữa P và Q. Nếu bạn đặt cược theo chiến lược tối ưu (tỷ lệ cược đúng bằng P), lợi nhuận kỳ vọng của bạn sẽ chính bằng KL divergence. Điều này một lần nữa giải thích tính không đối xứng: Bạn chỉ có thể khai thác khi nhà cái đánh giá thấp xác suất của một sự kiện thường xuyên xảy ra ($p_x \gg q_x$).
6. Xổ số (Lottery)
Tương tự như cá cược, hãy xem xét một trò xổ số nơi tiền thưởng được chia đều cho những người trúng giải. Nếu mọi người mua vé theo phân phối Q (ví dụ: thích các số tròn trĩnh, lặp lại), nhưng bạn biết phân phối trúng giải thực tế là P (ví dụ: hoàn toàn ngẫu nhiên), bạn có thể kiếm lời bằng cách mua các vé mà ít người khác mua.
KL divergence ở đây đo lường lợi nhuận kỳ vọng của bạn khi biết phân phối trúng giải P và phân phối mua vé của đám đông Q.
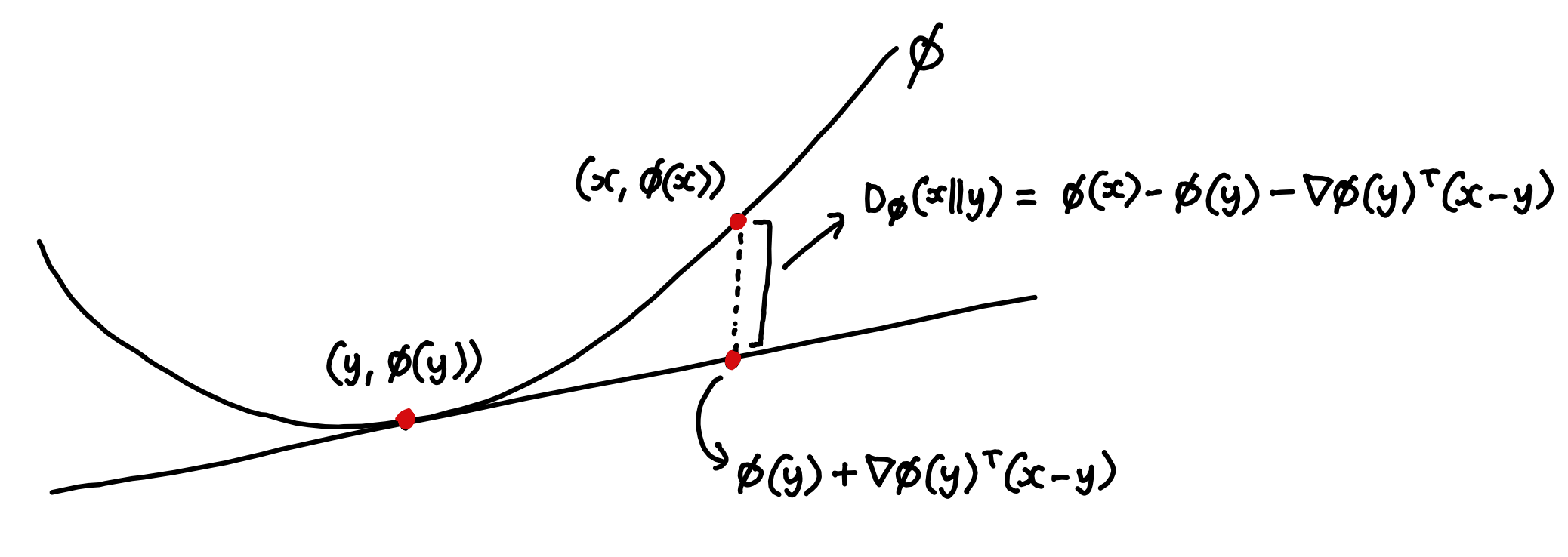
6.5. Phân kỳ Bregman (Bregman Divergence)
Đây là một góc nhìn toán học trừu tượng hơn. Trong không gian vector, khoảng cách Euclide (chuẩn L2) là cách tự nhiên để đo độ lệch giữa hai điểm. Tuy nhiên, trong không gian xác suất (simplex), thước đo tự nhiên để xem một phân phối "xa" mức 0 (độ bất ngờ) đến mức nào là Entropy.
Phân kỳ KL thực chất là một trường hợp đặc biệt của Phân kỳ Bregman khi áp dụng hàm âm của Entropy. Nó cho thấy rằng KL divergence là cách đo "khoảng cách" tự nhiên nhất khi chúng ta quan tâm đến Entropy thay vì khoảng cách hình học đơn thuần.
Tổng kết
Tất cả các trực giác trên đều xoay quanh một ý tưởng cốt lõi: KL divergence đo lường mức độ mô hình Q của chúng ta sai lệch so với phân phối thực tế P, trong thế giới nơi P là sự thật.
Nó không quan tâm đến việc mô hình Q dự đoán quá cao một sự kiện hiếm gặp ($q_x \gg p_x$), vì thực tế hiếm khi "trừng phạt" chúng ta cho sai lầm đó. Nhưng nếu Q dự đoán quá thấp một sự kiện thường xuyên ($p_x \gg q_x$), mô hình sẽ liên tục bị bất ngờ và chứng tỏ sự kém cỏi của mình. Hiểu được điều này giúp bạn nắm bắt bản chất của việc đánh giá hiệu suất mô hình và tối ưu hóa trong học máy.
Bài viết liên quan

Công nghệ
Các tác nhân AI đã khiến thế giới công nghệ chao đảo: Câu chuyện đằng sau cuộc cách mạng Claude Code và OpenClaw
26 tháng 5, 2026

Công nghệ
Threads cán mốc 500 triệu người dùng hoạt động hàng tháng
16 tháng 6, 2026

Công nghệ
Alienware 15 mới: Dell đang làm loãng thương hiệu cao cấp vì khủng hoảng RAM?
14 tháng 5, 2026