
Học Word Vectors cho Phân tích Cảm xúc: Tái hiện nghiên cứu kinh điển bằng Python
Bài viết này khám phá việc tái hiện nghiên cứu của Maas et al. (2011) nhằm xây dựng các vector từ có khả năng nắm bắt cả ngữ nghĩa lẫn sắc thái cảm xúc từ dữ liệu đánh giá phim IMDb. Bằng cách kết hợp học không giám sát về ngữ nghĩa và học có giám sát về cảm xúc, phương pháp này giúp cải thiện đáng kể độ chính xác trong phân loại văn bản.
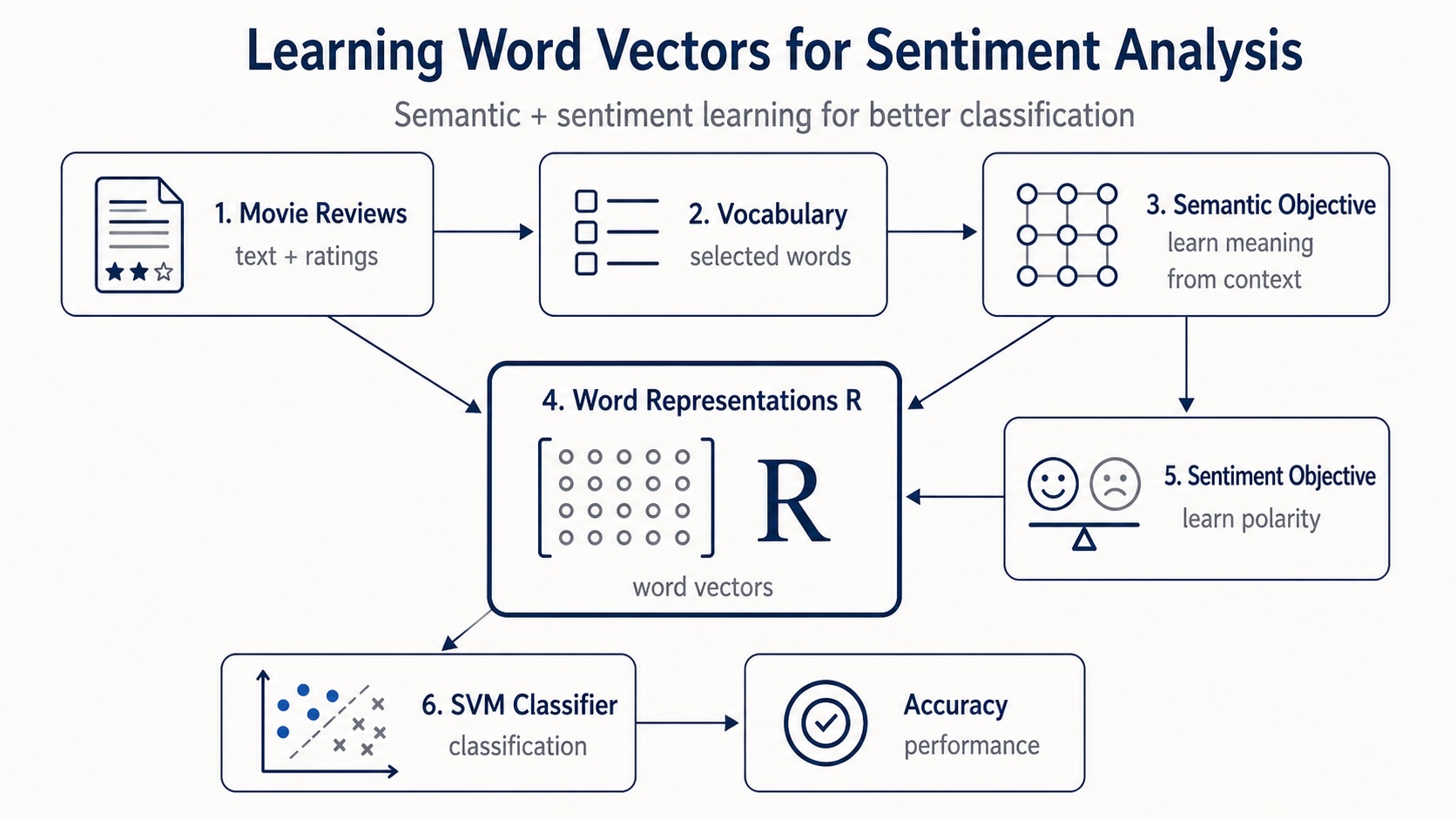
Trong lĩnh vực Xử lý ngôn ngữ tự nhiên (NLP), việc xây dựng các biểu diễn từ (word representations) không chỉ phản ánh ngữ nghĩa mà còn mang sắc thái cảm xúc luôn là một thách thức thú vị. Gần đây, tôi đã có cơ hội tái hiện bài báo nghiên cứu kinh điển "Learning Word Vectors for Sentiment Analysis" của Maas và cộng sự (2011) bằng Python. Điều khiến tôi ấn tượng nhất là sự đơn giản và tinh tế của phương pháp này: nó giống như hồi quy logistic trong chấm điểm tín dụng, đơn giản, dễ diễn giải nhưng lại cực kỳ mạnh mẽ khi được áp dụng đúng cách.
Bài viết dưới đây sẽ đi sâu vào quy trình tái hiện mô hình này, từ việc xây dựng từ vựng, tích hợp thông tin cảm xúc đến việc đánh giá kết quả bằng máy vector hỗ trợ tuyến tính (Linear SVM).
 Cấu trúc dữ liệu và quy trình xử lý
Cấu trúc dữ liệu và quy trình xử lý
Vấn đề cốt lõi của mô hình túi từ truyền thống
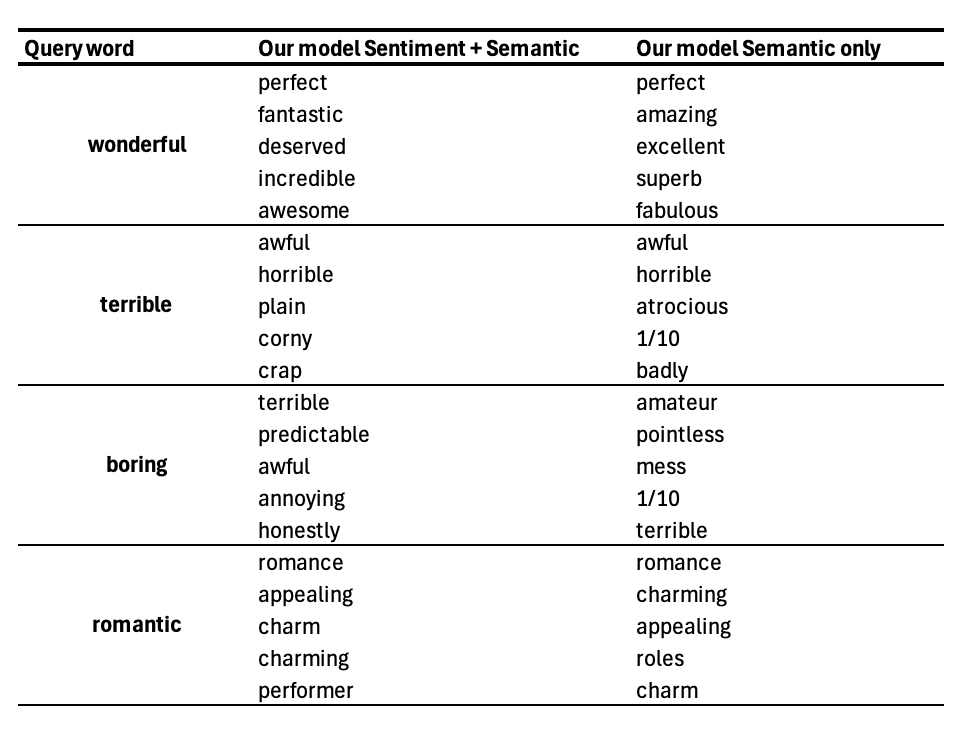
Các mô hình túi từ (Bag of Words) truyền thống rất hữu ích cho bài toán phân loại, nhưng chúng không học được các mối quan hệ có ý nghĩa giữa các từ. Ví dụ, các từ như "wonderful" (tuyệt vời) và "amazing" (kinh ngạc) nên nằm gần nhau vì chúng diễn đạt ý nghĩa và cảm xúc tương tự. Ngược lại, "wonderful" và "terrible" (khủng khiếp) có thể xuất hiện trong cùng ngữ cảnh đánh giá phim, nhưng chúng lại mang sắc thái cảm xúc đối lập.
Mục tiêu của bài báo là học các vector từ có khả năng nắm bắt cả sự tương đồng về ngữ nghĩa (semantic similarity) và định hướng về cảm xúc (sentiment orientation).
Cấu trúc dữ liệu IMDb
Bộ dữ liệu được sử dụng là bộ dữ liệu đánh giá phim lớn của IMDb, bao gồm:
- 25.000 đánh giá được gán nhãn用于 huấn luyện.
- 50.000 đánh giá không có nhãn用于 huấn luyện.
- 25.000 đánh giá được gán nhãn用于 kiểm thử.
Các đánh giá được gán nhãn được phân cực rõ ràng:
- Đánh giá tiêu cực có xếp hạng từ 1 đến 4 sao.
- Đánh giá tích cực có xếp hạng từ 7 đến 10 sao.
Các xếp hạng này được ánh xạ tuyến tính về khoảng [0, 1], cho phép mô hình xử lý cảm xúc như một xác suất liên tục của tính tích cực.
Xây dựng từ vựng
Một chi tiết quan trọng trong bài báo là cách xây dựng từ vựng. Các tác giả xây dựng một từ vựng cố định bằng cách bỏ qua 50 thuật ngữ xuất hiện thường nhất, sau đó giữ lại 5.000 thuật ngữ phổ biến tiếp theo.
Không có thuật toán stemming (trích xuất gốc từ) nào được áp dụng, và cũng không loại bỏ các từ dừng (stopwords) tiêu chuẩn. Điều này rất quan trọng vì một số từ dừng, đặc biệt là các từ phủ định, có thể mang thông tin cảm xúc quan trọng.
Trước khi xây dựng từ vựng, dữ liệu thô cần được làm sạch. Chúng tôi nhận thấy các đánh giá chứa các thẻ HTML, nên chúng đã được loại bỏ trong quá trình tải dữ liệu. Dấu câu gắn liền với từ như ".", ",", "!", "?" cũng được xử lý.
Mô hình học ngữ nghĩa (Semantic Component)
Phần đầu tiên của mô hình là không giám sát. Nó học các biểu diễn từ ngữ nghĩa từ cả đánh giá có nhãn và không có nhãn.
Mỗi tài liệu được liên kết với một vector tiềm ẩn theta, đại diện cho hướng ngữ nghĩa của tài liệu đó. Mỗi từ có một biểu diễn vector phi_w được lưu trữ dưới dạng một cột của ma trận R. Xác suất quan sát một từ w trong một tài liệu được cho bởi mô hình softmax:
p(w|θ;R,b) = exp(θ^T * phi_w + b_w) / sum(exp(θ^T * phi_w' + b_w'))
Về mặt trực quan, một từ trở nên có khả năng xuất hiện cao khi vector của nó được căn chỉnh tốt với vector tài liệu theta.
Tích hợp yếu tố cảm xúc (Sentiment Component)
Mô hình ngữ nghĩa một mình có thể học được rằng các từ xuất hiện trong các ngữ cảnh tương tự, nhưng điều này là chưa đủ để nắm bắt cảm xúc. Ví dụ, "wonderful" và "terrible" đều xuất hiện trong đánh giá phim nhưng lại biểu thị ý kiến trái ngược.
Để giải quyết vấn đề này, bài báo thêm một mục tiêu cảm xúc có giám sát sử dụng các xếp hạng sao để đưa thông tin polarity vào cùng một không gian vector. Vector psi xác định một hướng cảm xúc trong không gian vector từ. Nếu vector từ nằm ở một phía của siêu phẳng, nó được coi là tích cực, và ngược lại.
Mục tiêu học tập cuối cùng là sự kết hợp giữa hai phần này: phần đầu học sự tương đồng ngữ nghĩa, phần thứ hai đưa thông tin cảm xúc, cùng với các điều khoản chuẩn hóa để ngăn các vector trở nên quá lớn.
 So sánh kết quả các mô hình
So sánh kết quả các mô hình
Phân loại và Kết quả
Sau khi ma trận biểu diễn từ R được học, chúng ta có thể sử dụng nó để xây dựng các đặc trưng ở cấp độ tài liệu. Nhiệm vụ là phân loại mỗi đánh giá phim là tích cực hay tiêu cực bằng cách sử dụng Linear SVM.
Chúng ta đã đánh giá several cách biểu diễn tài liệu khác nhau:
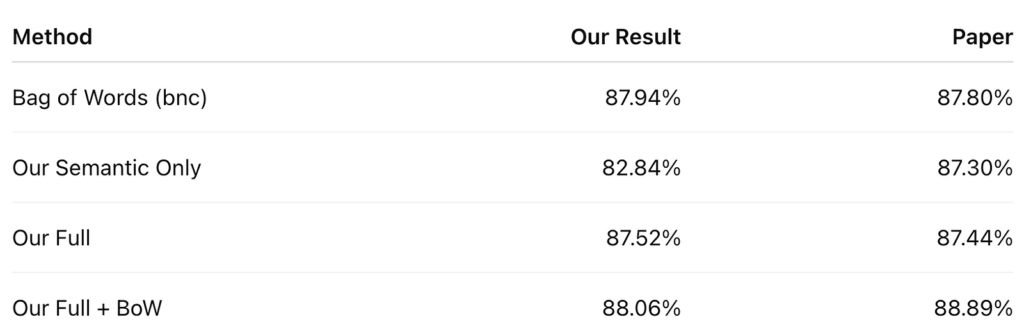
- Bag of Words cơ sở: Chỉ ghi nhận sự xuất hiện của từ.
- Biểu diễn vector từ ngữ nghĩa: Sử dụng vector từ học được từ mô hình không giám sát.
- Biểu diễn ngữ nghĩa + cảm xúc đầy đủ: Sử dụng ma trận R được học từ cả hai mục tiêu.
- Kết hợp: Nối biểu diễn vector từ dày đặc với biểu diễn Bag of Words thưa thớt.
Kết quả cho thấy mô hình đầy đủ (kết hợp ngữ nghĩa và cảm xúc) cho hiệu suất tốt nhất. Điều này khẳng định rằng việc đưa thông tin cảm xúc vào các vector từ thực sự giúp cải thiện khả năng phân loại so với việc chỉ dựa vào ngữ nghĩa thuần túy.
Kết luận
Quá trình tái hiện này cho thấy một ý tưởng đơn giản nhưng mạnh mẽ: các vector từ không chỉ nên nắm bắt từ đó có ý nghĩa gì, mà còn cả cảm xúc mà nó mang lại. Mô hình cho thấy cách dữ liệu không có nhãn có thể giúp học cấu trúc ngữ nghĩa, trong khi dữ liệu có nhãn có thể đưa thông tin cảm xúc vào cùng một không gian vector.
Đây là một bài học quý giá cho các lập trình viên và kỹ sư AI đang làm việc với NLP: đôi khi những phương pháp cổ điển, khi được hiểu rõ và áp dụng đúng cách, vẫn mang lại hiệu quả vượt trội.
Bài viết liên quan

Công nghệ
Anthropic bắt tay TCS để thúc đẩy triển khai AI trong doanh nghiệp
11 tháng 6, 2026
Công nghệ
Người Mỹ không thể nhận diện deepfake: Đây là cuộc khủng hoảng doanh nghiệp chứ không chỉ là vấn đề truyền thông
21 tháng 5, 2026
AI & ML
TrustCloud: Giải pháp thay thế bảng câu hỏi thủ công bằng tự động hóa đánh giá ứng dụng cho CISO
16 tháng 6, 2026