
Huấn luyện mô hình chấm điểm trong kỷ nguyên AI: Phương pháp luận lựa chọn mô hình tối ưu
Bài viết chia sẻ quy trình chi tiết để huấn luyện và đánh giá các mô hình chấm điểm tín dụng, kết hợp sức mạnh của AI trong việc viết code nhưng vẫn đảm bảo các tiêu chuẩn khắt khe về thống kê và độ ổn định. Mục tiêu là tìm ra mô hình cân bằng tốt nhất giữa hiệu suất, khả năng giải thích và tính nhất quán theo thời gian.

Trong thời đại Trí tuệ nhân tạo (AI) bùng nổ, việc tạo ra mã nguồn, tự động hóa việc huấn luyện mô hình và so sánh các chỉ số hiệu suất chưa bao giờ dễ dàng đến thế. Chỉ với một vài câu lệnh được cấu trúc tốt, các nhà khoa học dữ liệu có thể nhờ AI viết script Python, ước tính hồi quy logistic, tính toán AUC, Gini và tạo ra các bảng báo cáo.
Tuy nhiên, tốc độ này cũng đi kèm với những rủi ro tiềm ẩn. Một mô hình chấm điểm (scoring model) chuyên nghiệp không đơn thuần là một thuật toán chạy thành công hay có chỉ số cao nhất trên tập huấn luyện. Trong môi trường rủi ro tín dụng, mô hình phải đảm bảo tính hợp lệ về thống kê, sự ổn định theo thời gian, khả năng giải thích và nhất quán với kỳ vọng kinh doanh.
 AI và Data Science
AI và Data Science
Bài viết này sẽ đi sâu vào quy trình huấn luyện các mô hình ứng viên và lựa chọn mô hình cuối cùng, sử dụng bộ dữ liệu Credit Scoring từ Kaggle làm ví dụ minh họa. Chúng ta sẽ xem xét cách các công cụ AI như Codex hỗ trợ quy trình này và tại sao sự phán xét của con người vẫn là yếu tố then chốt.
Dữ liệu và bài toán chấm điểm
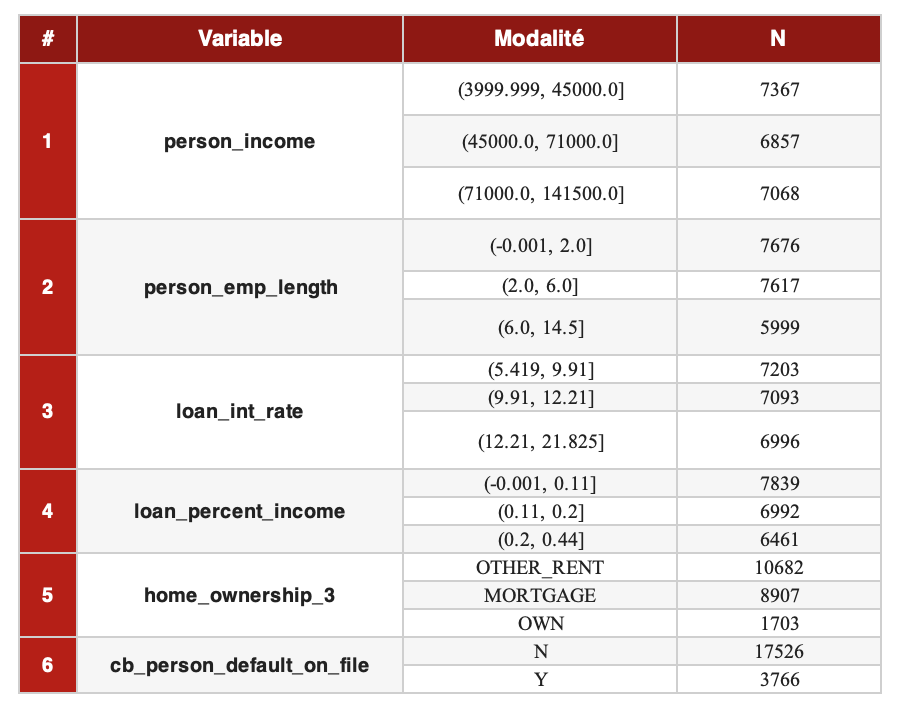
Bộ dữ liệu sử dụng bao gồm 32.581 quan sát và 12 biến mô tả các khoản vay. Sau các bước xử lý trước, chúng ta giữ lại 6 biến giải thích dạng phân loại (X1...X6) và một biến mục tiêu Y đại diện cho trạng thái vỡ nợ (loan_status).
Mục tiêu là ước tính xác suất vỡ nợ có điều kiện dựa trên các đặc điểm quan sát được: P(Y=1|X1=x1, X2=x2, ..., X6=x6)
Để đảm bảo độ tin cậy, dữ liệu được chia thành ba tập chính:
- Tập huấn luyện (Training sample): Dùng để ước tính tham số.
- Tập kiểm tra (Test sample): Đánh giá khả năng tổng quát hóa.
- Tập ngoài thời gian (Out-of-time sample): Đánh giá sự ổn định theo thời gian – yếu tố cực kỳ quan trọng trong chấm điểm tín dụng.
Tại sao Hồi quy Logistic vẫn là mô hình tham chiếu?
Mặc dù AI mang đến nhiều mô hình phức tạp như Random Forest hay Neural Network, hồi quy logistic vẫn là mô hình tham chiếu trong chấm điểm tín dụng.
Lý do nằm ở tính có thể giải thích (interpretability). Hồi quy logistic mô hình hóa log-odds của vỡ nợ là một tổ hợp tuyến tính của các biến giải thích. Các hệ số cho thấy rõ ràng hướng tác động của từng biến đến rủi ro. Điều này không chỉ giúp các đội ngũ thống kê hiểu rõ mô hình mà còn giúp các bộ phận kinh doanh và quản trị dễ dàng chấp nhận và giám sát sau khi triển khai.
Chuẩn bị biến và Huấn luyện mô hình ứng viên
Vì các biến giải thích là dạng phân loại, chúng cần được chuyển đổi thành các biến giả (dummy variables). Một nhóm sẽ được chọn làm tham chiếu (thường là nhóm có rủi ro thấp nhất) để dễ dàng diễn giải hệ số: hệ số dương cho thấy rủi ro cao hơn so với nhóm tham chiếu.
Quá trình huấn luyện bao gồm việc thử nghiệm tất cả các tổ hợp hợp lý của các biến ứng viên. Mục tiêu không chỉ là tìm mô hình có hiệu suất cao nhất trên tập huấn luyện, mà là mô hình thỏa mãn đồng thời các tiêu chí:
- Tính hợp lệ về thống kê.
- Nhất quán với logic kinh doanh.
- Khả năng phân biệt rủi ro tốt.
- Ổn định trên các mẫu khác nhau.
- Đa cộng tuyến thấp (VIF < 10).
 Quy trình đánh giá mô hình
Quy trình đánh giá mô hình
Tiêu chí đánh giá: Thống kê, Hiệu suất và Ổn định
1. Đánh giá thống kê
Sử dụng các kiểm định như Likelihood Ratio test để đánh giá ý nghĩa toàn cầu, và kiểm định Wald hay p-value để đánh giá ý nghĩa riêng lẻ của từng biến. Hướng của rủi ro cũng phải hợp lý; ví dụ, một biến được kỳ vọng làm tăng rủi ro thì phải có hệ số dương.
2. Hiệu suất phân biệt (Performance Metrics)
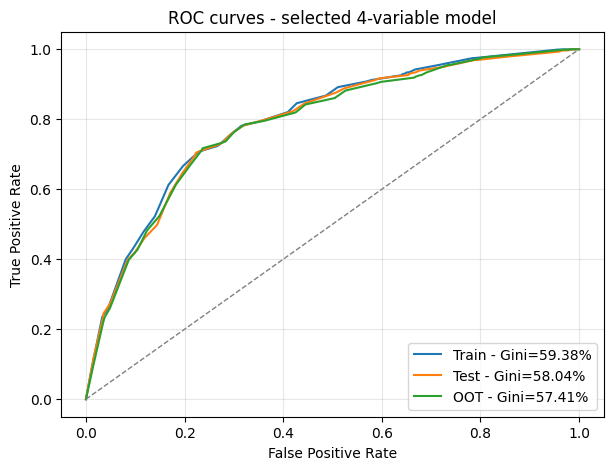
- AUC & Gini: Đo lường khả năng xếp hạng rủi ro. Gini = 2 x AUC - 1. Chỉ số càng cao càng tốt.
- Recall & Precision: Quan trọng khi dữ liệu mất cân bằng. Recall đo khả năng phát hiện vỡ nợ, Precision đo độ chính xác của các dự báo vỡ nợ.
- F1-score & PR-AUC: Kết hợp hài hòa giữa Recall và Precision.
3. Tiêu chí ổn định (Stability)
Một mô hình tốt phải hoạt động ổn định không chỉ trên tập huấn luyện mà còn trên tập kiểm tra và tập ngoài thời gian. Chúng tôi sử dụng Gini bị phạt (Penalized Gini) để khuyến khích các mô hình có sự suy giảm hiệu suất ít nhất giữa các tập dữ liệu:
Gini_penalized = mean(Gini_folds) - |Gini_train - Gini_test| - |Gini_train - Gini_OOT|
Vai trò của AI trong quy trình
Trong nghiên cứu này, chúng tôi sử dụng Codex (một công cụ AI lập trình) để hỗ trợ viết mã, tự động hóa các vòng lặp biến, tính toán chỉ số và tạo bảng báo cáo.
 AI hỗ trợ lập trình
AI hỗ trợ lập trình
AI đóng vai trò là một trợ lý phương pháp luận mạnh mẽ, giúp tăng tốc các tác vụ lặp lại và kỹ thuật. Tuy nhiên, kết quả cuối cùng vẫn phải được con người xem xét. Các kiểm định thống kê cần được diễn thích đúng, tính nhất quán với kinh doanh cần được xác thực, và mô hình cuối cùng phải do chuyên gia lựa chọn.
Kết quả và Lựa chọn mô hình cuối cùng
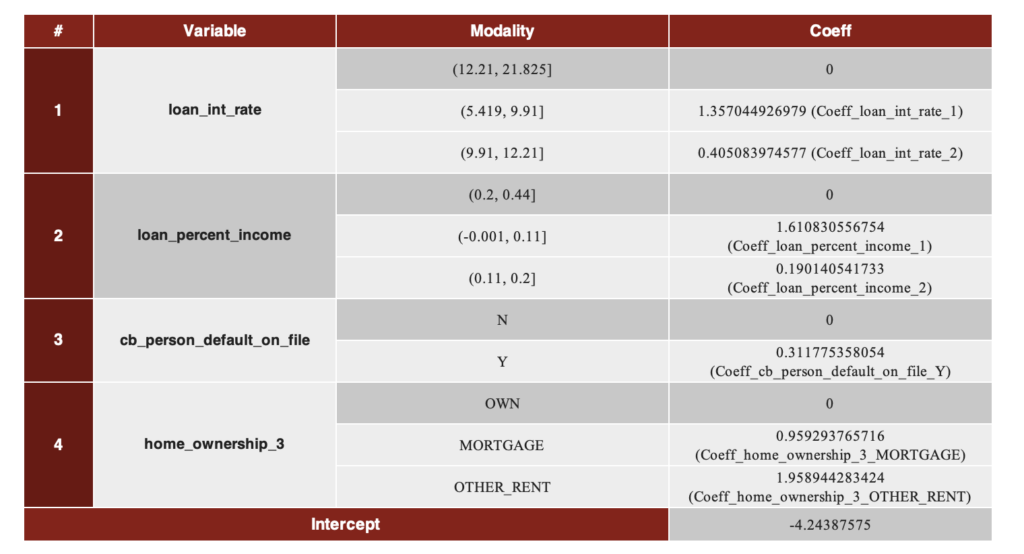
Sau khi đánh giá nhiều mô hình, Mô hình 4 đã được chọn làm mô hình chấm điểm cuối cùng với các lý do sau:
- Cung cấp sự cân bằng tốt nhất giữa hiệu suất và độ ổn định với Penalized Gini là 56,01%.
- Chỉ sử dụng 4 biến, giúp mô hình đơn giản, dễ diễn giải và dễ giám sát.
- PR-AUC đạt 48,44%, cao hơn đáng kể so với tỷ lệ vỡ nợ cơ bản 22%, xác nhận khả năng nhận diện khách hàng xấu tốt.
Mô hình này đã được lưu trữ để sử dụng trong tương lai, chứng minh rằng sự kết hợp giữa phương pháp thống kê cổ điển và công cụ AI hiện đại có thể tạo ra những giải pháp tài chính vững chắc và hiệu quả.
Bài viết liên quan

Công nghệ
Anthropic và OpenAI mang cuộc chiến công nghệ sang chính trường Mỹ
20 tháng 5, 2026

Công nghệ
Threads cán mốc 500 triệu người dùng, ra mắt tính năng cá nhân hóa thuật toán mới
16 tháng 6, 2026

Công nghệ
Tấn công mạng làm tê liệt nhà máy đường lớn tại Australia, nông dân không thể thu hoạch
17 tháng 6, 2026