
Hướng dẫn Survival Analysis với Python: Dự báo vòng đời khách hàng bằng mô hình Time-To-Event
Survival Analysis là một nhánh thống kê quan trọng giúp dự đoán thời gian cho đến khi một sự kiện cụ thể xảy ra. Bài viết này sẽ hướng dẫn bạn cách áp dụng các mô hình Kaplan-Meier và Cox Proportional Hazard trong Python để phân tích dữ liệu rời bỏ của khách hàng (churn).

Thống kê học có thể được áp dụng vào nhiều lĩnh vực khác nhau, giúp chúng ta xử lý sự không chắc chắn, tính toán xác suất và hỗ trợ ra quyết định. Một trong những lĩnh vực phụ thuộc nhiều vào thống kê là y tế, sử dụng các công cụ như T-Tests, A/B Tests hay Survival Analysis (Phân tích tồn tại). Và Survival Analysis chính là chủ đề chính của bài viết ngày hôm nay.
Survival Analysis ban đầu xuất phát từ các ngành y tế và sinh học, nơi mục tiêu chính là mô hình hóa thời gian tử vong của một bệnh nhân hoặc sinh vật. Đó cũng là lý do cho cái tên của nó. Tuy nhiên, các nhà thống kê đã nhận ra rằng phương pháp phân tích này quá mạnh mẽ để chỉ giới hạn trong y tế, và nó đã lan rộng sang lĩnh vực kinh doanh, đặc biệt là kể từ sự bùng nổ của Khoa học Dữ liệu (Data Science).
 Hàm Survival Function
Hàm Survival Function
Survival Analysis là gì?
Survival Analysis [SA] là một nhánh của thống kê được sử dụng để dự đoán khoảng thời gian cần thiết để một sự kiện cụ thể xảy ra. Còn được gọi là Time-to-event (Thời gian đến sự kiện), nghiên cứu này có thể xác định mất bao lâu để một việc gì đó xảy ra, đồng thời tính đến việc rằng một số sự kiện có thể chưa xảy ra vào thời điểm dữ liệu được thu thập.
Các ví dụ không chỉ nằm trong y tế mà xuất hiện ở khắp mọi nơi:
- Thời gian cho đến khi một máy móc bị hỏng.
- Thời gian cho đến khi khách hàng hủy đăng ký dịch vụ (Churn).
- Thời gian cho đến khi khách hàng mua hàng lại.
Vì chúng ta đang cố gắng ước tính một con số (thời gian) thay vì một nhóm hay lớp, nên đây về cơ bản là một bài toán hồi quy (regression). Vậy tại sao không sử dụng Hồi quy Tuyến tính OLS thông thường?
Tại sao nên sử dụng Survival Analysis?
Các mô hình hồi quy tiêu chuẩn như OLS hay Logistic Regression thường gặp khó khăn với dữ liệu tồn tại vì chúng được thiết kế để xử lý các sự kiện đã hoàn tất, không phải những câu chuyện "đang diễn ra".
Hãy tưởng tượng bạn muốn dự đoán ai sẽ hoàn thành một cuộc đua 10 dặm, nhưng dữ liệu đầu vào là một sự kiện vẫn đang diễn ra. Cuộc đua đã diễn ra được 2 giờ và bạn muốn sử dụng dữ liệu hiện có để ước tính điều gì đó. Các thuật toán hồi quy thông thường sẽ thất bại vì:
- OLS: Bạn chỉ có dữ liệu của những người đã về đích. Chỉ sử dụng dữ liệu của họ sẽ tạo ra một độ chệch lớn (bias) nghiêng về những người chạy nhanh hơn.
- Logistic Regression: Nó có thể cho biết liệu ai đó đã về đích hay chưa, nhưng nó coi những người về đích sau 30 phút giống hệt những người về đích sau 8 giờ.
Các khái niệm cơ bản của Survival Analysis
Để hiểu rõ về Survival Analysis, chúng ta cần đi qua một vài khái niệm quan trọng.
Trước hết, chúng ta phải hiểu về sự "sinh" và "tử" của một điểm dữ liệu.
- Sinh (Birth): Khoảnh khắc chúng ta bắt đầu đo lường điểm dữ liệu đó. Ví dụ: thời điểm một bệnh nhân được chẩn đoán ung thư, hoặc ngày một người được tuyển dụng bởi công ty. Lưu ý rằng các quan sát không cần bắt đầu cùng một lúc.
- Tử (Death): Xảy ra tại thời điểm sự kiện quan tâm diễn ra. Ví dụ: ngày nhân viên nghỉ việc tại công ty.
Điều thú vị của SA là nghiên cứu hoặc quan sát có thể kết thúc trước khi sự kiện xảy ra. Trong trường hợp này, chúng ta sẽ có một khái niệm quan trọng khác: điểm dữ liệu bị kiểm duyệt (censored data point).
Kiểm duyệt (Censoring - Non-death): Nếu nghiên cứu kết thúc hoặc một đối tượng rời bỏ trước khi sự kiện xảy ra, dữ liệu đó bị "kiểm duyệt", nghĩa là chúng ta chỉ biết họ tồn tại ít nhất đến thời điểm đó.
Dữ liệu có thể bị kiểm duyệt theo nhiều cách, nhưng phổ biến nhất là Right Censoring (Kiểm duyệt bên phải): Sự kiện xảy ra sau khi thời gian quan sát kết thúc hoặc đối tượng rời bỏ nghiên cứu.
Bằng cách coi sự tồn tại là một hàm của thời gian, chúng ta có thể trả lời những câu hỏi mà một điểm số xác suất đơn lẻ không thể làm được, chẳng hạn như: "Tháng cụ thể nào thì rủi ro khách hàng rời bỏ dịch vụ (churn) đạt đỉnh?"
Các hàm số trong Survival Analysis
Hàm Survival (Survival Function)
Hàm tồn tại S(t) biểu thị xác suất để sự kiện không xảy ra dưới dạng hàm của thời gian. Nó sẽ tự nhiên giảm dần theo thời gian, vì ngày càng nhiều cá nhân sẽ trải qua sự kiện.
Áp dụng vào ví dụ về nhân viên nghỉ việc, chúng ta sẽ thấy xác suất rằng một nhân viên vẫn còn làm việc tại công ty sau N năm.
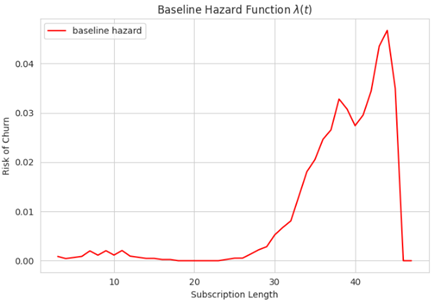
Hàm Hazard (Hazard Function)
Hàm rủi ro cho biết xác suất sự kiện xảy ra tại một thời điểm nhất định. Nó ngược với hàm tồn tại và đại diện cho rủi ro rời bỏ (thay vì xác suất ở lại công ty).
Hàm này sẽ tính toán xác suất rằng những nhân viên chưa rời bỏ cho đến nay sẽ làm như vậy từ thời điểm này trở đi.
 Hàm Hazard Function
Hàm Hazard Function
Lựa chọn mô hình cho Survival Analysis
Có hai mô hình chính được sử dụng khi thực hiện Survival Analysis:
- Kaplan-Meier: Đơn giản hơn nhưng không xem xét tác động của các biến dự báo bổ sung.
- Cox Proportional Hazard: Chuẩn công nghiệp vì có thể đưa các biến khác vào mô hình, ổn định hơn về mặt toán học.
Mô hình Kaplan-Meier
- Hoạt động tốt với dữ liệu bị kiểm duyệt bên phải.
- Mô hình trực quan, phi tham số (non-parametric).
- Trả về một hàm tồn tại trông giống như một bậc thang.
- Khi nào dùng: Phân tích tồn tại đơn giản không có các biến đồng biến (covariates) khác, tuyệt vời để trực quan hóa nhanh.
Mô hình Cox Proportional Hazard
- Chuẩn công nghiệp.
- Chấp nhận các biến dự báo hoặc đồng biến bổ sung.
- Hoạt động tốt ngay cả khi một số giả định bị vi phạm.
- Ước lượng hàm rủi ro, thường ổn định hơn hàm tồn tại.
- Khi nào dùng: Ước lượng trên dữ liệu có nhiều biến dự báo.
Thực hành với Python
Trong phần này, chúng ta sẽ học cách mô hình hóa SA sử dụng cả hai mô hình trên với tập dữ liệu Telco Customer Churn (Khách hàng rời bỏ dịch vụ viễn thông).
Triển khai Kaplan-Meier
Mô hình Kaplan-Meier [KM] rất đơn giản và trực quan. Chúng ta cần hai biến: một biến dự báo (thời gian) và một nhãn (sự kiện).
from lifelines import KaplanMeierFitter
import matplotlib.pyplot as plt
# Khởi tạo mô hình KM
kmf = KaplanMeierFitter()
# Fit mô hình với dữ liệu
# 'Subscription Length': Tổng tháng đăng ký
# 'Churn': Sự kiện quan sát (1 là rời bỏ, 0 là còn lại)
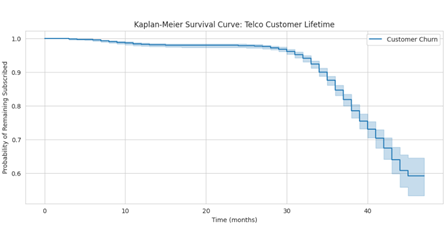
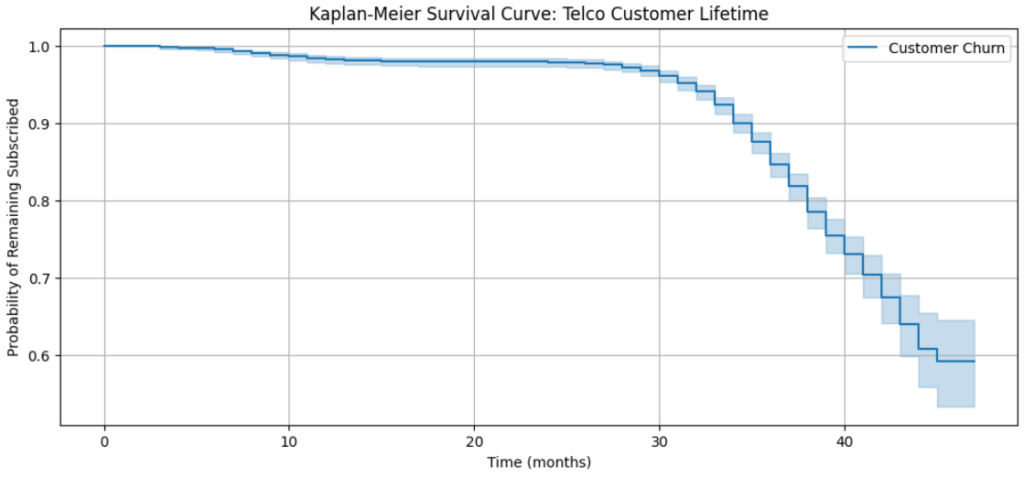
kmf.fit(df['Subscription Length'], event_observed=df['Churn'], label='Customer Churn')
# Vẽ đường cong tồn tại
plt.figure(figsize=(12, 5))
kmf.plot_survival_function()
plt.title('Đường cong Kaplan-Meier: Vòng đời khách hàng Telco')
plt.xlabel('Thời gian (tháng)')
plt.ylabel('Xác suất giữ chân đăng ký')
plt.grid(True)
plt.show()
Kết quả cho thấy hơn 90% khách hàng gắn bó với công ty viễn thông khoảng 35 tháng. Chúng ta có thể kiểm tra xác suất cụ thể tại tháng thứ 34:
# Kiểm tra tỷ lệ tồn tại tại tháng 34
print(kmf.survival_function_at_times(34))
# Kết quả: 0.900613 (khoảng 90%)
Chúng ta cũng có thể so sánh giữa các nhóm, ví dụ: người dùng thường xuyên (Heavy-users) và người dùng ít (Soft-users).
 So sánh Survival giữa các nhóm
So sánh Survival giữa các nhóm
Biểu đồ cho thấy người dùng "Soft" có xu hướng rời đi nhanh hơn sau tháng thứ 30. Để đảm bảo sự khác biệt này có ý nghĩa thống kê, chúng ta sử dụng Log-Rank Test.
Triển khai Cox Proportional Hazard
Mô hình Cox cho phép chúng ta đưa vào các biến số khác để xem xét tác động của chúng lên rủi ro.
from lifelines import CoxPHFitter
# Chọn các cột số để mô hình hóa
df_model = df[['Subscription Length', 'Churn', 'Frequency of use', 'Charge Amount', 'Complains']]
# Khởi tạo và fit mô hình
cph = CoxPHFitter()
cph.fit(df_model, duration_col='Subscription Length', event_col='Churn')
# In bảng kết quả
cph.print_summary()
Trong bảng kết quả, cột quan trọng nhất với các bên liên quan kinh doanh là Hazard Ratio (exp(coef)). Nó cho biết tác nhân nhân lên rủi ro rời bỏ.
- Complains (5.36): Khách hàng có khiếu nại có khả năng rời bỏ cao hơn 5.36 lần (tăng 436%) so với người không khiếu nại. Đây là tác động cực lớn.
- Frequency of use (0.99): Tác động không đáng kể.
- Charge Amount (0.83): Mỗi đơn vị tăng thêm trong phí thanh toán, rủi ro rời bỏ giảm 17%. Khách hàng trả phí cao hơn thường ổn định hơn.
Chúng ta có thể so sánh xác suất tồn tại của hai khách hàng cụ thể: một người không khiếu nại và một người có khiếu nại tại tháng thứ 34:
- Khách hàng 110 (Không khiếu nại): Xác suất tồn tại 93.94%.
- Khách hàng 111 (Có khiếu nại): Xác suất tồn tại chỉ còn 61.68%.
Sự khác biệt là rất rõ rệt. Chúng ta cũng có thể tính toán thời gian dự kiến mỗi khách hàng sẽ rời đi:
- Khách hàng không khiếu nại: Dự kiến rời đi ở tháng thứ 41.
- Khách hàng có khiếu nại: Dự kiến rời đi ở tháng thứ 31.
Kết luận
Survival Analysis không chỉ là một hàm thống kê đơn thuần. Các công ty có thể sử dụng nó để hiểu rõ hành vi khách hàng. Các mô hình Kaplan-Meier và Cox Proportional Hazard cung cấp những thông tin chi tiết có thể hành động được về tuổi thọ của người đăng ký. Chúng ta đã thấy cách các biến như giá trị khách hàng và khiếu nại dịch vụ ảnh hưởng trực tiếp đến tỷ lệ rời bỏ, cho phép các nhà ra quyết định theo đuổi các chiến lược giữ chân khách hàng nhắm mục tiêu hơn hiệu quả.
Bài viết liên quan

Phần cứng
Gemma 4 áp dụng Multi-Token Prediction, tăng tốc độ suy luận lên tới 3 lần
25 tháng 5, 2026

Công nghệ
Các tác nhân AI đã khiến thế giới công nghệ chao đảo: Câu chuyện đằng sau cuộc cách mạng Claude Code và OpenClaw
26 tháng 5, 2026

Phần cứng
Nvidia chính thức đưa siêu vi xử lý Grace Blackwell lên PC với dòng notebook RTX Spark
01 tháng 6, 2026