
Khi "nghỉ ngơi" lại là ảo giác: Cách tối ưu hóa Linux Kernel tạo ra lỗi nghiêm trọng trong QUIC
Cloudflare đã phát hiện và khắc phục một lỗi phức tạp trong thư viện QUIC mã nguồn mở của họ, nơi thuật toán điều khiển tắc nghẽn CUBIC bị kẹt ở mức tối thiểu sau khi mất gói nghiêm trọng. Vấn đề bắt nguồn từ việc chuyển đổi một tối ưu hóa của Linux Kernel sang môi trường người dùng, khiến hệ thống nhầm lẫn trạng thái tắc nghẽn mạng với thời gian rảnh (idle).
Khi "nghỉ ngơi" lại là ảo giác: Cách tối ưu hóa Linux Kernel tạo ra lỗi nghiêm trọng trong QUIC
CUBIC, được tiêu chuẩn hóa trong RFC 9438, là bộ điều khiển tắc nghẽn mặc định trong Linux và chi phối cách hầu hết các kết nối TCP và QUIC trên Internet công cộng thăm dò băng thông có sẵn, giảm tốc khi phát hiện mất gói và phục hồi sau đó. Tại Cloudflare, việc triển khai QUIC mã nguồn mở của chúng tôi là quiche, sử dụng CUBIC làm bộ điều khiển tắc nghẽn mặc định, nghĩa là đoạn mã này nằm trên đường dẫn quan trọng đối với một phần lớn lưu lượng truy cập mà chúng tôi phục vụ.
Trong bài viết này, chúng tôi sẽ kể lại câu chuyện về một lỗi mà trong đó cửa sổ tắc nghẽn (cwnd) của CUBIC bị cố định ở mức tối thiểu và không bao giờ phục hồi sau một sự cố sụp đổ tắc nghẽn. Câu chuyện bắt đầu với một thay đổi nhân Linux nhằm đưa CUBIC phù hợp với việc loại trừ giới hạn ứng dụng được mô tả trong RFC 9438 — một bản sửa lỗi cho vấn đề thực trong TCP, khi được chuyển sang triển khai QUIC của chúng tôi, đã bộc lộ các hành vi bất ngờ trong quiche. May mắn thay, câu chuyện có kết thúc đẹp: một bản sửa lỗi thanh lịch (gần như) chỉ một dòng code đã phá vỡ vòng lặp này.
Logic của CUBIC tóm tắt trong một "vỏ nutshell"
Trước khi đi sâu vào vấn đề cốt lõi, một chút ôn tập nhanh về các thuật toán điều khiển tắc nghẽn (CCA) có thể giúp thiết lập bối cảnh. Nút điều khiển trung tâm của CCA là cửa sổ tắc nghẽn (cwnd): giới hạn phía người gửi về số lượng byte có thể đang "trên đường" (đã gửi nhưng chưa được xác nhận) tại bất kỳ thời điểm nào. Cwnd lớn hơn cho phép người gửi đẩy nhiều dữ liệu hơn mỗi chuyến khứ hồi; cwnd nhỏ hơn sẽ làm chậm nó. Mọi CCA dựa trên mất gói, bao gồm cả CUBIC, cuối cùng là một chính sách về cách tăng cwnd khi mạng trông khỏe mạnh và cách giảm cwnd khi không.
Về bản chất, các CCA nhằm mục đích tối đa hóa việc truyền dữ liệu bằng cách suy luận "băng thông khả dụng" của mạng; vì không ai muốn trả tiền cho thuê bao 1 Gbps mà chỉ sử dụng một phần nhỏ. Gia đình các thuật toán dựa trên mất gói, mà CUBIC là một thành viên, hoạt động dựa trên một giả định cơ bản: (1) nếu không có mất gói, hãy tăng tốc độ gửi (tức là tăng sử dụng băng thông); (2) nếu có mất gói, các thuật toán dựa trên mất gói giả định rằng dung lượng mạng đã bị vượt quá và người gửi phải lùi lại (tức là giảm sử dụng băng thông).
Triệu chứng: Một bài kiểm tra thất bại 61% thời gian
Cuộc điều tra của chúng tôi bắt đầu với báo cáo về các lỗi thất bại bất ngờ trong pipeline kiểm tra tích hợp proxy nhập của chúng tôi. Hành vi thất thường này xuất hiện trong các bài kiểm tra nơi CUBIC được đánh giá trong kịch bản mất gói nặng trong phần đầu của kết nối. Việc phục hồi sau sự sụp đổ tắc nghẽn là một chế độ hoạt động hiếm gặp, nhưng chính là chế độ mà bộ điều khiển tắc nghẽn tồn tại để xử lý. Hầu hết các bài kiểm tra điều khiển tắc nghẽn đều kiểm tra các giai đoạn trạng thái ổn định và tăng trưởng của thuật toán; rất ít bài kiểm tra xem điều gì sẽ xảy ra ở cwnd tối thiểu, sau khi kết nối bị "đánh bại". Các lỗi trong góc khuất của không gian trạng thái này vô hình trên các bảng điều khiển throughput, không thể phát hiện bằng kiểm tra tĩnh, và chỉ xuất hiện khi bạn cố tình đẩy một CCA vào trạng thái đó và xem liệu nó có thể leo ra ngoài hay không — chính xác là những gì bài kiểm tra này đã làm.
Thiết lập kiểm tra mô phỏng bao gồm các chi tiết sau:
- Máy khách và máy chủ Quiche HTTP/3 chạy cục bộ (localhost).
- RTT = 10ms (được thiết lập trong cấu hình).
- Tải xuống tệp 10 MB qua HTTP/3.
- Sử dụng điều khiển tắc nghẽn CUBIC.
- Tỷ lệ mất gói ngẫu nhiên 30% được chèn vào trong hai giây đầu tiên.
- Sau hai giây, mất gói dừng hoàn toàn.
Bài kiểm tra có thời gian chờ hào phóng là 10 giây để hoàn tất việc tải xuống, dự kiến sẽ hoàn thành trong bốn hoặc năm giây. Hành vi mong đợi rất đơn giản: CUBIC nên chịu một số thiệt hại trong giai đoạn mất gói, giảm cửa sổ tắc nghẽn của nó, và khi mất gói dừng lại, tăng tốc đều đặn và hoàn tất việc tải xuống tốt trong thời gian chờ. Thay vào đó, chúng tôi quan sát thấy trong nhiều lần chạy 100 lần rằng khoảng 60% bài kiểm tra của chúng tôi không thể hoàn tất việc tải xuống trong thời gian chờ 10 giây hào phóng đó.
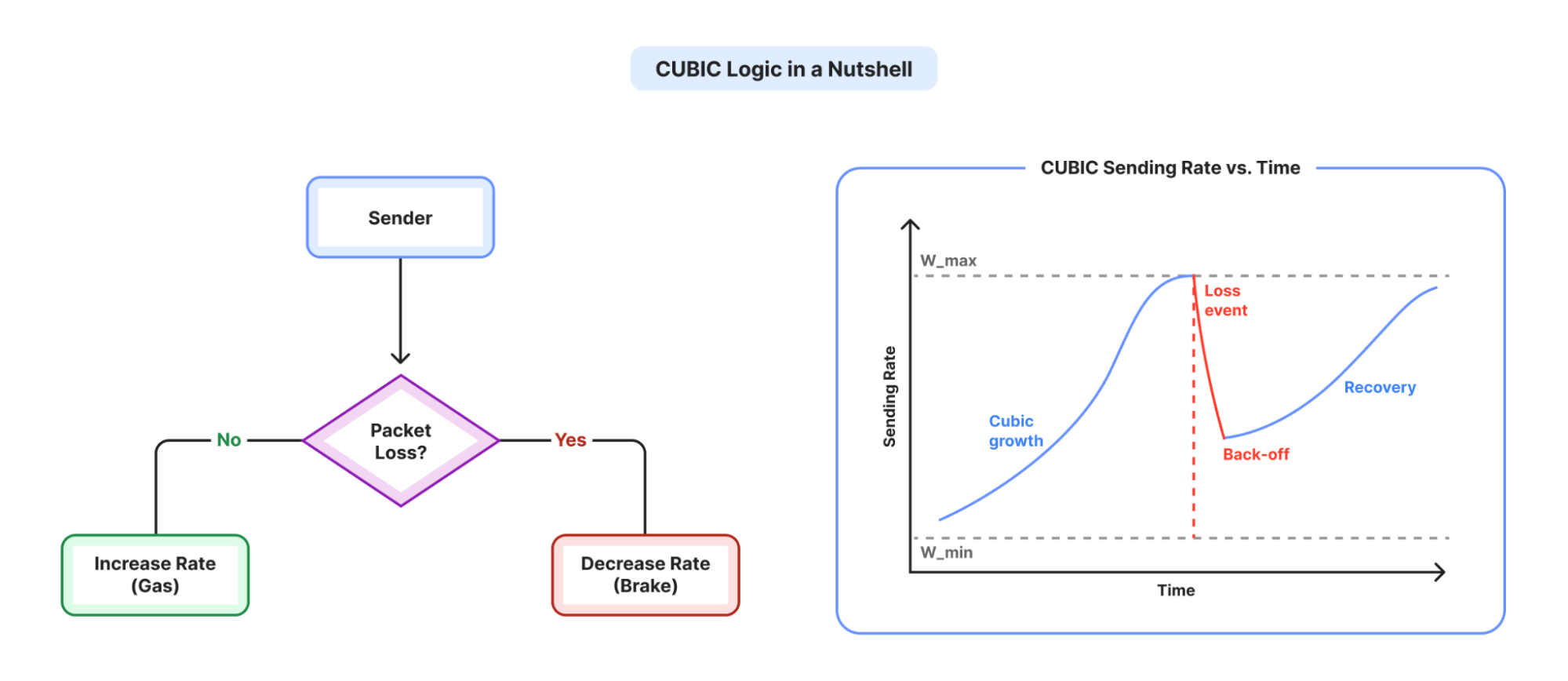
 Tổng quan kết nối của một bài kiểm tra thất bại. Sau T=2s, mất gói dừng hoàn toàn — nhưng cwnd vẫn bị cố định ở mức sàn tối thiểu và trạng thái tắc nghẽn dao động giữa phục hồi và tránh tắc nghẽn mỗi ~14ms.
Tổng quan kết nối của một bài kiểm tra thất bại. Sau T=2s, mất gói dừng hoàn toàn — nhưng cwnd vẫn bị cố định ở mức sàn tối thiểu và trạng thái tắc nghẽn dao động giữa phục hồi và tránh tắc nghẽn mỗi ~14ms.
Bất thường: 999 lần chuyển đổi trạng thái với mất gói bằng không
Chúng tôi đã trang bị đầu ra qlog của quiche với các sự kiện mất gói và xây dựng các hình ảnh trực quan để hiểu điều gì đang xảy ra bên trong bộ điều khiển tắc nghẽn. Sau mốc hai giây (2000 ms), mất gói dừng hoàn toàn. Tuy nhiên, số byte đang trên đường vẫn phẳng, điều này mâu thuẫn với logic cốt lõi của thuật toán CUBIC: nếu không có mất gói, hãy thêm ga để tăng ga (nhiều byte hơn trong thế giới của chúng ta). Điều này đặt ra câu hỏi: nếu mạng không còn bỏ gói nữa, tại sao cửa sổ tắc nghẽn lại không tăng trưởng?
Khi phóng to vào khu vực đó, phân tích của chúng tôi cho thấy CUBIC đi vào dao động nhanh, được hiển thị trong biểu đồ của chúng tôi dưới dạng giai đoạn phục hồi kéo dài, giữa trạng thái tránh tắc nghẽn (giai đoạn hoạt động) và trạng thái phục hồi (giai đoạn phục hồi mất gói) — 999 lần chuyển đổi trong khoảng 6,7 giây. Đó là một lần chuyển đổi mỗi ~14ms — đáng ngờ gần với RTT của kết nối (10ms). Trong suốt giai đoạn này, cwnd bị khóa ở mức sàn tối thiểu: 2700 byte, hoặc hai gói kích thước đầy đủ.
Rõ ràng có gì đó trong logic của CUBIC đang hiểu sai trạng thái của kết nối. Manh mối chính là chu kỳ dao động: ~14ms khớp với RTT. Bất cứ điều gì kích hoạt sự lật đổ phục hồi/tránh tắc nghẽn đều đang xảy ra một lần mỗi chuyến khứ hồi, đồng bộ với đồng hồ ACK của kết nối; nhịp tự đồng hồ mà trong đó các ACK của mỗi chuyến khứ hồi từ máy khách kích hoạt lần gửi tiếp theo của máy chủ. Vì đây là tải xuống (từ máy chủ đến máy khách), các ACK có vấn đề đi từ máy khách đến máy chủ, và máy trạng thái CUBIC chạy ở phía máy chủ: mỗi khi các ACK đó hạ cánh, bytes_in_flight giảm xuống bằng không và máy chủ gửi burst hai gói tiếp theo, chính là thứ kích hoạt lỗi.
Để xác nhận hành vi này là đặc trưng của CUBIC, chúng tôi đã chạy cùng một bài kiểm tra với Reno, một thành viên khác của gia đình dựa trên mất gói nhưng với tốc độ tăng trưởng khác. Kết quả là quyết đoán: tỷ lệ vượt qua 100%, cho thấy Reno phục hồi sạch sẽ sau giai đoạn mất gói, và tiết lộ rằng đây là một lỗi liên quan đến CUBIC.
 Reno phục hồi sạch sẽ sau khi giai đoạn mất gói kết thúc tại T=2s và hoàn tất việc tải xuống vào khoảng ~5s.
Reno phục hồi sạch sẽ sau khi giai đoạn mất gói kết thúc tại T=2s và hoàn tất việc tải xuống vào khoảng ~5s.
Truy tìm nguyên nhân gốc rễ
Để hiểu lỗi này, trước hết chúng ta cần hiểu tối ưu hóa mà nó bắt nguồn từ đó. Vào năm 2017, một vấn đề đã được tìm thấy trong triển khai CUBIC của nhân Linux. Thông báo commit giải thích rằng epoch (tham chiếu thời gian) chỉ được cập nhật/đặt lại ban đầu và khi trải qua mất gói. Delta "t" của now - epoch_start có thể tùy ý lớn sau khi ứng dụng rảnh rỗi cũng như bic_target. Hậu quả là độ dốc (nghịch đảo của ca->cnt) sẽ thực sự lớn, và cuối cùng ca->cnt sẽ bị giới hạn dưới ở mức 2 để có hành vi khởi động chậm delayed-ACK.
Điều này đặc biệt hiển thị khi slow_start_after_idle bị tắt dưới dạng sự phồng cwnd nguy hiểm (1,5 x RTT) sau vài giây thời gian rảnh.
Giải pháp thanh lịch, được viết bởi Eric Dumazet, Yuchung Cheng và Neal Cardwell, là dịch chuyển epoch tiến lên theo thời gian rảnh thay vì đặt lại nó. Điều này bảo toàn hình dạng của đường cong tăng trưởng CUBIC — chỉ trượt nó theo thời gian để thuật toán tiếp tục từ nơi nó dừng lại.
Cái bẫy: Sự khác biệt của QUIC
Khi CUBIC được triển khai lần đầu trong quiche, điều chỉnh thời gian rảnh này đã được chuyển đổi. Tuy nhiên, QUIC, chạy trong không gian người dùng, không có callback CA_EVENT_TX_START cấp kernel của TCP. Thay vào đó, triển khai quiche kiểm tra điều kiện rảnh bên trong on_packet_sent():
// cubic.rs — on_packet_sent() (đơn giản hóa)
/// Cập nhật trạng thái khi một gói được gửi.
fn on_packet_sent(&mut self, bytes_in_flight: usize, now: Instant, ...) {
// Nếu burst gửi đang khởi động lại (tức là bytes_in_flight bằng 0 trước lần gửi này),
// điều chỉnh thời gian bắt đầu phục hồi tắc nghẽn để tính đến khoảng trống trong việc gửi.
if bytes_in_flight == 0 {
let delta = now - self.last_sent_time;
self.congestion_recovery_start_time += delta;
}
// Ghi lại thời gian của sự kiện gửi này.
self.last_sent_time = now;
}
Bản sửa lỗi được chuyển sang quiche bao gồm một lỗi trong thay đổi nhân ban đầu đã được sửa bởi một thay đổi tiếp theo cho mô-đun cubic kernel khoảng một tuần sau đó. Thông báo commit cho bản sửa lỗi thứ hai giải thích: Theo dõi thời gian rảnh trong bictcp_cwnd_event() không chính xác, vì epoch_start thường được đặt tại thời gian xử lý ACK, không phải tại thời gian gửi. Việc thực hiện bản sửa lỗi thích hợp sẽ cần thêm một biến trạng thái bổ sung, và có vẻ không đáng bother, vì lỗi CUBIC đã tồn tại mãi mãi trước khi Jana nhận thấy. Hãy đơn giản là không đặt epoch_start trong tương lai, nếu không bictcp_update() có thể tràn và CUBIC sẽ lại tăng cwnd quá nhanh.
Như đã đề cập trong thông báo commit, thời gian bắt đầu phục hồi được đặt trong quá trình xử lý ACK, và tính toán điều chỉnh dựa trên thời gian gửi có thể đẩy thời gian bắt đầu phục hồi vào tương lai. Điều này giải thích sự dao động giữa phục hồi và tránh tắc nghẽn được thấy trong bài kiểm tra của chúng tôi. Cái bẫy chỉ kích hoạt nhất quán khi mọi ACK đến đẩy bytes_in_flight xuống bằng không — trong thực tế điều này có nghĩa là cwnd đã sụp đổ xuống mức tối thiểu (hai gói) và ứng dụng có dữ liệu sẵn sàng để gửi một cửa sổ đầy đủ ngay khi ACK đến. Ngoài chế độ này, bytes_in_flight == 0 ít khả năng giữ trên mọi lần gửi, do đó ít khả năng kích hoạt lỗi hơn.
Vòng lặp tử thần tự duy trì
Ở cwnd tối thiểu (hai gói), động lực của kết nối chuyển sang một "vòng xoáy tử thần" nơi tối ưu hóa thời gian rảnh trở thành một lời tiên tri tự ứng nghiệm. Cái bẫy này hoạt động trong một vòng lặp liên tục:
- Gửi và ACK gói: Người gửi truyền toàn bộ cửa sổ hai gói. Sau một RTT (~14ms), cả hai gói đều được ACK, khiến bytes_in_flight giảm xuống bằng không.
- Phát hiện rảnh giả: Khi burst tiếp theo được gửi, on_packet_sent() thấy bytes_in_flight == 0 và giả định kết nối đã rảnh, nhưng thực tế nó bị giới hạn bởi tắc nghẽn.
- Delta phồng: Tính toán sử dụng now - last_sent_time để xác định thời gian rảnh. Khi cửa sổ tắc nghẽn (cwnd) ở mức tối thiểu, last_sent_time là dấu thời gian của bắt đầu chu kỳ RTT trước đó. Do đó, delta kết quả là khoảng 14ms (RTT của kết nối + lỗi làm tròn thêm). Delta kích thước RTT này được áp dụng sai làm thời gian "rảnh". Thời gian thực tế kết nối rảnh (khoảng trống xử lý giữa ACK cuối cùng đến và gói tiếp theo được gửi) thực tế là 0. Bằng cách đo toàn bộ RTT thay vì khoảng trống thực, delta bị phồng lên đáng kể, đẩy mạnh thời gian bắt đầu phục hồi tiến lên, có thể vào tương lai.
- Phục hồi được cảm nhận: Vì thời gian bắt đầu phục hồi hiện ở tương lai, kiểm tra in_congestion_recovery() trả về true cho mọi ACK đến. Xử lý ACK tiếp theo thoát khỏi phục hồi và đặt thời gian bắt đầu phục hồi thành thời gian ACK lớn hơn last_sent_time, làm cho bộ điều khiển tắc nghẽn có khả năng đẩy thời gian phục hồi vào tương lai khi thực hiện lần gửi tiếp theo.
- Đứng yên: Vì CUBIC bỏ qua tăng trưởng cwnd cho bất kỳ gói nào được cảm nhận là trong giai đoạn phục hồi, cửa sổ vẫn bị cố định ở hai gói — đảm bảo đường ống cạn kiệt hoàn toàn vào ACK tiếp theo và khởi động lại chu kỳ.
Bản sửa lỗi: Đo lường thời gian rảnh từ đúng thời điểm
Sửa chữa vòng xoáy tử thần liên quan đến việc đo thời gian rảnh từ thời điểm bytes_in_flight thực sự chuyển sang bằng không (ACK cuối cùng được xử lý) thay vì gói cuối cùng được gửi.
Thay đổi mã bao gồm việc thêm dấu thời gian last_ack_time vào trạng thái CUBIC, cập nhật dấu thời gian đó khi ACK đến và sử dụng nó cho tính toán delta rảnh.
 Mã cũ: ranh giới tiến lên một RTT mỗi chu kỳ, luôn hạ cánh hoặc trước lần gửi tiếp theo. Bản sửa lỗi: ranh giới hầu như không di chuyển; lần gửi tiếp theo hạ cánh trước nó và cwnd tăng trưởng.
Mã cũ: ranh giới tiến lên một RTT mỗi chu kỳ, luôn hạ cánh hoặc trước lần gửi tiếp theo. Bản sửa lỗi: ranh giới hầu như không di chuyển; lần gửi tiếp theo hạ cánh trước nó và cwnd tăng trưởng.
Với delta giờ phản ánh khoảng trống thực tế kể từ ACK cuối cùng, ranh giới phục hồi ngừng đuổi theo thời gian gửi. Đối với các kết nối thực sự rảnh, last_ack_time ở quá khứ xa và cùng một biểu thức nắm bắt toàn bộ thời gian rảnh, hành vi dịch chuyển epoch ban đầu được bảo tồn.
Bài học rút ra
- "Rảnh" (Idle) khó định nghĩa hơn âm thanh của nó. Các độ trễ đường ống thông thường ở các cửa sổ nhỏ có thể trông giống như sự rảnh rỗi đối với các kiểm tra đơn giản.
- Động thái cwnd tối thiểu là một trường hợp góc độc đáo. Lỗi này vô hình ở tốc độ cao và chỉ kích hoạt sau khi mất gói nghiêm trọng.
- Bản sửa lỗi nhỏ một cách đáng ngạc nhiên so với sự phức tạp của hành vi. Sau nhiều tuần trang bị qlogs và phân tích hình ảnh trực quan để tìm nguyên nhân gốc rễ, giải pháp chỉ yêu cầu thay đổi ba dòng code. Như chúng tôi đã lưu ý trong quá trình điều tra: nỗ lực để tìm lỗi là rất lớn, nhưng bản sửa lỗi về cơ bản chỉ là một dòng logic.
Bản sửa lỗi được mô tả trong bài viết này đã được đóng góp cho cloudflare/quiche, triển khai QUIC và HTTP/3 mã nguồn mở của Cloudflare. Các nỗ lực CCA của chúng tôi vượt ra ngoài các thuật toán dựa trên mất gói: chúng tôi cũng sử dụng thiết kế điều khiển tắc nghẽn mô-đun của quiche để thử nghiệm và tinh chỉnh triển khai BBRv3 dựa trên mô hình của mình, hiện đã được bật cho một tỷ lệ phần trăm ngày càng tăng trong các triển khai QUIC của chúng tôi. Hãy theo dõi để cập nhật thêm về việc triển khai và hiệu suất điều khiển tắc nghẽn QUIC.


