
Kog đạt tốc độ suy luận 3.000 token/giây trên GPU tiêu chuẩn, thách thức phần cứng chuyên dụng
Startup Kog đã chứng minh khả năng đạt tốc độ suy luận 3.000 token mỗi giây trên các GPU trung tâm dữ liệu phổ thông nhờ tối ưu hóa toàn diện phần mềm. Đột phá này giúp các tác nhân AI hoạt động gần như thời gian thực mà không phụ thuộc vào phần cứng độc quyền đắt đỏ.
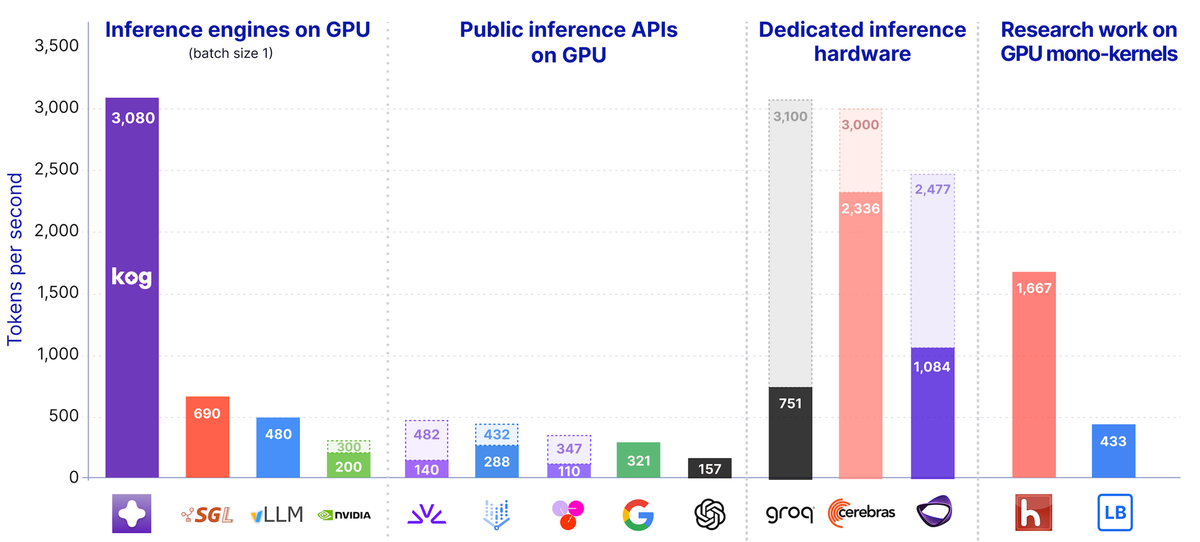
Kog, một startup công nghệ có trụ sở tại Paris, vừa công bố một bước đột phá đáng chú ý trong lĩnh vực hạ tầng trí tuệ nhân tạo: họ đã chứng minh rằng các GPU tiêu chuẩn hiện nay có thể đạt tốc độ suy luận (inference) cực nhanh, lên tới 3.000 token mỗi giây cho mỗi yêu cầu. Con số này tương đương với hiệu suất của các phần cứng chuyên dụng đắt đỏ, mở ra cơ hội lớn cho việc phát triển các tác nhân AI tự chủ (autonomous AI agents) mà không bị ràng buộc bởi các giải pháp phần cứng độc quyền.
Trong bản xem trước kỹ thuật (tech preview) của mình, Kog sử dụng một nút máy chủ gồm 8 GPU AMD MI300X để chạy mô hình lập trình 2 tỷ tham số (2B). Điểm mấu chốt ở đây không phải là phần cứng, mà là việc tối ưu hóa toàn bộ stack phần mềm thông qua việc thiết kế đồng bộ (co-design) kiến trúc mô hình, runtime và mã GPU cấp thấp.
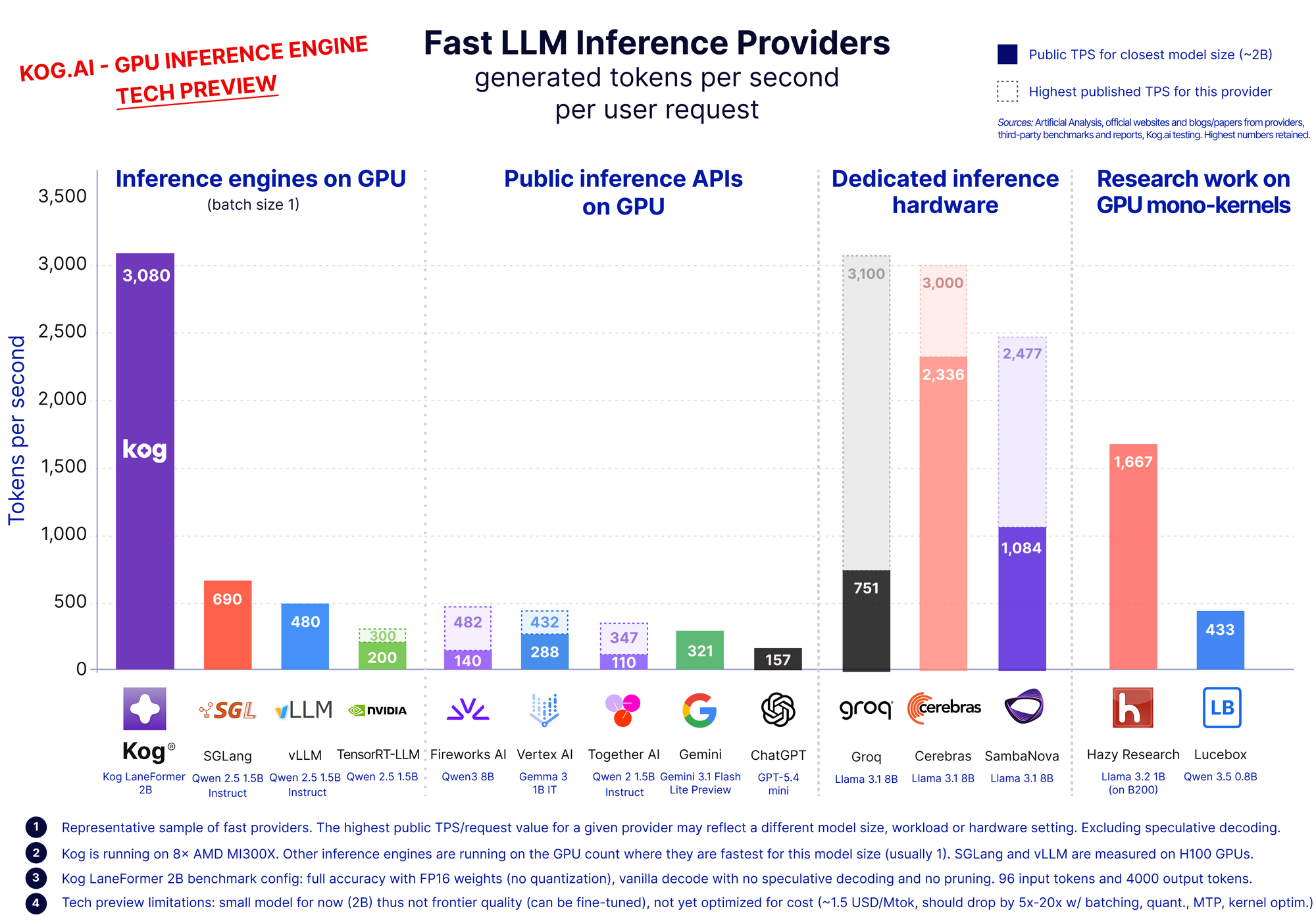 Benchmark tốc độ suy luận của Kog AI
Benchmark tốc độ suy luận của Kog AI
Tại sao tốc độ suy luận đơn lẻ lại quan trọng?
Thông thường, các benchmark AI tập trung vào tổng lượng token xử lý trên toàn hệ thống (aggregate throughput) hoặc độ trễ của token đầu tiên (time to first token). Tuy nhiên, đối với các tác nhân AI — những hệ thống tự động thực hiện các chuỗi tác vụ phức tạp như kiểm tra, lập kế hoạch, viết code và sửa lỗi — chỉ số quan trọng nhất lại là tốc độ giải mã cho từng yêu cầu đơn lẻ (decode speed per request).
Hãy tưởng tượng một tác nhân AI cần tạo ra 50.000 token để hoàn thành một quy trình làm việc. Với tốc độ 100 token/giây, người dùng sẽ phải chờ khoảng 8 phút. Nhưng nếu đạt tốc độ 3.000 token/giây, thời gian chờ giảm xuống dưới 20 giây. Sự khác biệt này thay đổi hoàn toàn khả năng phản ứng và trải nghiệm người dùng của sản phẩm.
Nút thắt phần mềm trên GPU
Kog chỉ ra rằng, ở kích thước lô (batch size) bằng 1, tốc độ tạo token bị giới hạn bởi băng thông bộ nhớ (memory bandwidth) chứ không phải sức mạnh tính toán (FLOPS). Các GPU hiện đại như NVIDIA H200 hay AMD MI300X đều có băng thông HBM rất lớn, nhưng các stack suy luận hiện tại (như vLLM, TensorRT-LLM) thường không khai thác hết được khả năng này do các chi phí phần mềm.
Vấn đề nằm ở việc các framework truyền thống chia nhỏ quy trình suy luận thành hàng chục kernel riêng biệt, mỗi lần chạy đều phải tốn chi phí khởi động và đồng bộ hóa. Ở tốc độ mục tiêu 3.000 token/giây, ngân sách thời gian cho mỗi token chỉ khoảng 333 microgiây. Chỉ một vài microgiây lãng phí ở mỗi lớp cũng đủ làm giảm đáng kể tốc độ tổng thể.
Giải pháp "Monokernel" và thiết kế đồng bộ
Để giải quyết vấn đề này, Kog đã tiếp cận từ gốc rễ bằng cách thiết kế đồng bộ ba lớp: kiến trúc mô hình, runtime và mã GPU.
Thay vì sử dụng nhiều kernel, Kog triển khai một "Monokernel" (kernel đơn nhất) liên tục. Đây là một chương trình GPU duy nhất chạy xuyên suốt quá trình giải mã mà không bị gián đoạn. Cách tiếp cận này loại bỏ hoàn toàn chi phí khởi động kernel, giảm thiểu sự đồng bộ hóa giữa CPU và GPU, và cho phép kiểm soát chặt chẽ việc luân chuyển dữ liệu bộ nhớ.
Ngoài ra, Kog còn phát triển KCCL, một thư viện truyền thông tập thể (collective communication) tùy chỉnh để tối ưu hóa việc trao đổi dữ liệu giữa các GPU, giảm độ trễ xuống dưới 3 microgiây — thấp hơn nhiều so với các thư viện chuẩn của nhà sản xuất. Họ cũng giới thiệu kiến trúc Laneformer với công nghệ "Delayed Tensor Parallelism" (DTP), giúp chồng lấn việc truyền dữ liệu giữa các thiết bị với quá trình tính toán, tránh làm tắc nghẽn đường dẫn quan trọng.
Tiềm năng mở rộng cho các mô hình lớn
Mặc dù bản xem trước hiện tại sử dụng mô hình 2B, Kog tin rằng công nghệ này có thể mở rộng cho các mô hình MoE (Mixture of Experts) khổng lồ hàng đầu hiện nay như DeepSeek-V4 hay Qwen3. Với sự gia tăng băng thông bộ nhớ ở các thế hệ GPU tiếp theo (như Rubin hay MI450), họ dự đoán rằng các mô hình tiên tiến sẽ có thể đạt tốc độ từ 1.000 đến 5.000 token/giây ngay trên phần cứng GPU tiêu chuẩn.
Điều này có ý nghĩa to lớn đối với các doanh nghiệp và phòng lab AI. Thay vì phải đầu tư vào các thẻ suy luận chuyên dụng đắt đỏ và bị khóa hệ sinh thái, họ có thể tận dụng tối đa các GPU trung tâm dữ liệu đang có để đạt hiệu suất thời gian thực.
Kog hiện đang cung cấp môi trường thử nghiệm (playground) công khai để các nhà phát triển có thể trải nghiệm tốc độ suy luận này. Thành tựu của họ là minh chứng rõ ràng cho việc tối ưu hóa phần mềm có thể giải phóng tiềm năng phần cứng đang bị lãng phí, đưa hiệu suất của GPU tiêu chuẩn lên một tầm cao mới.
Bài viết liên quan

Công nghệ
Sự trở lại của Xbox: Chiến lược mới, thay đổi nhân sự và tương lai Project Helix
07 tháng 5, 2026

Công nghệ
Samsung Galaxy Book6 Ultra: Bản sao MacBook Pro đắt đỏ nhưng đầy khiếm khuyết
07 tháng 5, 2026

Công nghệ
Tạm biệt "Ferrynoia": Công nghệ hàng hải xanh đang thay đổi ngành vận tải thủy
05 tháng 6, 2026