
Kỹ thuật Context Engineering cho AI Agents: Tối ưu hóa tài nguyên ngữ cảnh
Hiệu suất thực tế của AI Agents phụ thuộc nhiều vào cách ngữ cảnh được xây dựng và quản lý hơn là kích thước của nó. Bài viết này phân tích các nguyên tắc của Context Engineering giúp bạn xác định thông tin cần thiết để tạo ra các tác nhân AI mượt mà và đáng tin cậy.

Chúng ta thường bàn luận rất nhiều về những mô hình tốt hơn, các cửa sổ ngữ cảnh (context window) lớn hơn và những tác nhân AI có khả năng cao hơn. Tuy nhiên, phần lớn các thất bại trong thế giới thực không đến từ khả năng của mô hình — mà đến từ cách ngữ cảnh được xây dựng, truyền tải và duy trì.
Đây là một bài toán khó. Lĩnh vực này phát triển rất nhanh và các kỹ thuật vẫn đang tiếp tục tiến hóa. Phần lớn nó vẫn là một khoa học thực nghiệm và phụ thuộc vào ngữ cảnh, các ràng buộc cũng như môi trường mà bạn đang vận hành.
Trong quá trình xây dựng các hệ thống đa tác nhân (multi-agent systems), tôi nhận thấy một mô hình thường xuyên lặp lại: hiệu suất ít liên quan đến việc bạn cung cấp bao nhiêu ngữ cảnh cho mô hình, mà phụ thuộc nhiều hơn vào việc bạn định hình nó chính xác như thế nào.
Bài viết này là nỗ lực chắt lọc những kinh nghiệm đó thành những kiến thức bạn có thể áp dụng được. Nó tập trung vào các nguyên tắc quản lý ngữ cảnh như một tài nguyên bị giới hạn — quyết định cái gì nên bao gồm, cái gì nên loại trừ và cách cấu trúc thông tin để các tác nhân giữ được sự mạch lạc, hiệu quả và đáng tin cậy theo thời gian.
Bởi vì cuối cùng, những tác nhân mạnh mẽ nhất không phải là những tác nhân nhìn thấy nhiều nhất, mà là những tác nhân nhìn thấy đúng thứ, dưới đúng hình thức, vào đúng thời điểm.
 Kiến trúc Context Engineering cho AI Agents
Kiến trúc Context Engineering cho AI Agents
Các thuật ngữ cốt lõi
Context Engineering (Kỹ thuật ngữ cảnh)
Context Engineering là nghệ thuật cung cấp đúng thông tin, công cụ và định dạng cho một Mô hình Ngôn ngữ Lớn (LLM) để nó có thể hoàn thành một nhiệm vụ. Context Engineering tốt có nghĩa là tìm tập hợp nhỏ nhất các token tín hiệu cao mang lại cho LLM xác suất cao nhất để tạo ra kết quả tốt.
Trong thực tế, Context Engineering tốt thường quy về bốn hành động chính:
- Context Offloading (Tải ngoại): Chuyển tải thông tin sang các hệ thống bên ngoài để mô hình không cần phải mang tất cả theo trong băng thông.
- Context Retrieval (Truy xuất ngữ cảnh): Truy xuất thông tin động thay vì nạp tất cả ngay từ đầu.
- Context Isolation (Cách ly ngữ cảnh): Cô lập ngữ cảnh để một tác vụ con không làm ô nhiễm tác vụ khác.
- Context Reduction (Giảm thiểu lịch sử): Cắt giảm lịch sử khi cần thiết, nhưng chỉ theo những cách vẫn bảo lưu những gì tác nhân sẽ cần sau này.
Một trạng thái thất bại phổ biến ở phía ngược lại là context pollution (ô nhiễm ngữ cảnh): sự hiện diện của quá nhiều thông tin không cần thiết, xung đột hoặc dư thừa khiến LLM bị xao nhãng.
Context Rot (Sự suy giảm ngữ cảnh)
Context rot là tình trạng hiệu năng của LLM bị suy giảm khi cửa sổ ngữ cảnh đầy lên, ngay cả khi nó vẫn nằm trong giới hạn kỹ thuật cho phép. LLM vẫn còn chỗ để đọc thêm, nhưng khả năng lập luận bắt đầu bị nhòe đi.
Bạn có thể nhận thấy rằng cửa sổ ngữ cảnh hiệu dụng — nơi mô hình hoạt động với chất lượng cao — thường nhỏ hơn nhiều so với khả năng kỹ thuật của mô hình.
Có hai khía cạnh ở đây. Thứ nhất, mô hình không duy trì khả năng ghi nhớ hoàn hảo trên toàn bộ cửa sổ ngữ cảnh. Thông tin ở phần đầu và phần cuối được ghi nhớ đáng tin cậy hơn những thứ ở giữa.
Thứ hai, các cửa sổ ngữ cảnh lớn hơn không giải quyết được vấn đề cho các hệ thống doanh nghiệp. Dữ liệu doanh nghiệp về cơ bản là vô hạn và được cập nhật thường xuyên, do đó ngay cả khi mô hình có thể tiêu thụ tất cả, điều đó không có nghĩa là nó có thể duy trì sự hiểu biết mạch lạc về nó.
Giống như con người có dung lượng bộ nhớ làm việc hạn chế, mọi token mới được đưa vào LLM sẽ làm cạn kiệt ngân sách chú ý của nó một chút. Sự khan hiếm sự chú ý này bắt nguồn từ các ràng buộc kiến trúc trong bộ biến đổi (transformer), nơi mỗi token chú ý đến mọi token khác. Điều này dẫn đến mẫu tương tác n² cho n token. Khi ngữ cảnh phát triển, mô hình bị buộc phải trải sự chú ý mỏng hơn trên nhiều mối quan hệ hơn.
Context Compaction (Nén ngữ cảnh)
Context compaction là câu trả lời chung cho context rot.
Khi mô hình tiến tới giới hạn cửa sổ ngữ cảnh của nó, nó sẽ tóm tắt nội dung và khởi tạo lại một cửa sổ ngữ cảnh mới với tóm tắt trước đó. Điều này đặc biệt hữu ích cho các tác vụ chạy dài để cho phép mô hình tiếp tục làm việc mà không bị suy giảm hiệu suất quá nhiều.
Các công trình gần đây về context folding cung cấp một cách tiếp cận khác — các tác nhân chủ động quản lý ngữ cảnh làm việc của chính mình. Một tác nhân có thể phân nhánh để xử lý một tác vụ con rồi gấp lại (fold) khi hoàn thành, thu gọn các bước trung gian trong khi vẫn giữ lại bản tóm tắt ngắn gọn về kết quả.
Tuy nhiên, khó khăn không nằm ở việc tóm tắt, mà nằm ở việc quyết định cái gì được giữ lại. Một số thứ nên giữ ổn định và gần như không thay đổi, chẳng hạn như mục tiêu của nhiệm vụ và các ràng buộc cứng. Những thứ khác có thể được loại bỏ an toàn. Thách thức là tầm quan trọng của thông tin thường chỉ được lộ ra sau này.
Do đó, việc nén tốt cần bảo lưu các thực tế tiếp tục ràng buộc các hành động trong tương lai: cách tiếp cận nào đã thất bại, tệp tin nào đã được tạo, giả định nào bị vô hiệu, phần tử nào có thể xem lại và những sự không chắc chắn nào vẫn chưa được giải quyết. Nếu không, bạn sẽ có một bản tóm tắt gọn gàng, ngắn gọn đọc rất thoải mái cho con người nhưng vô dụng với tác nhân.
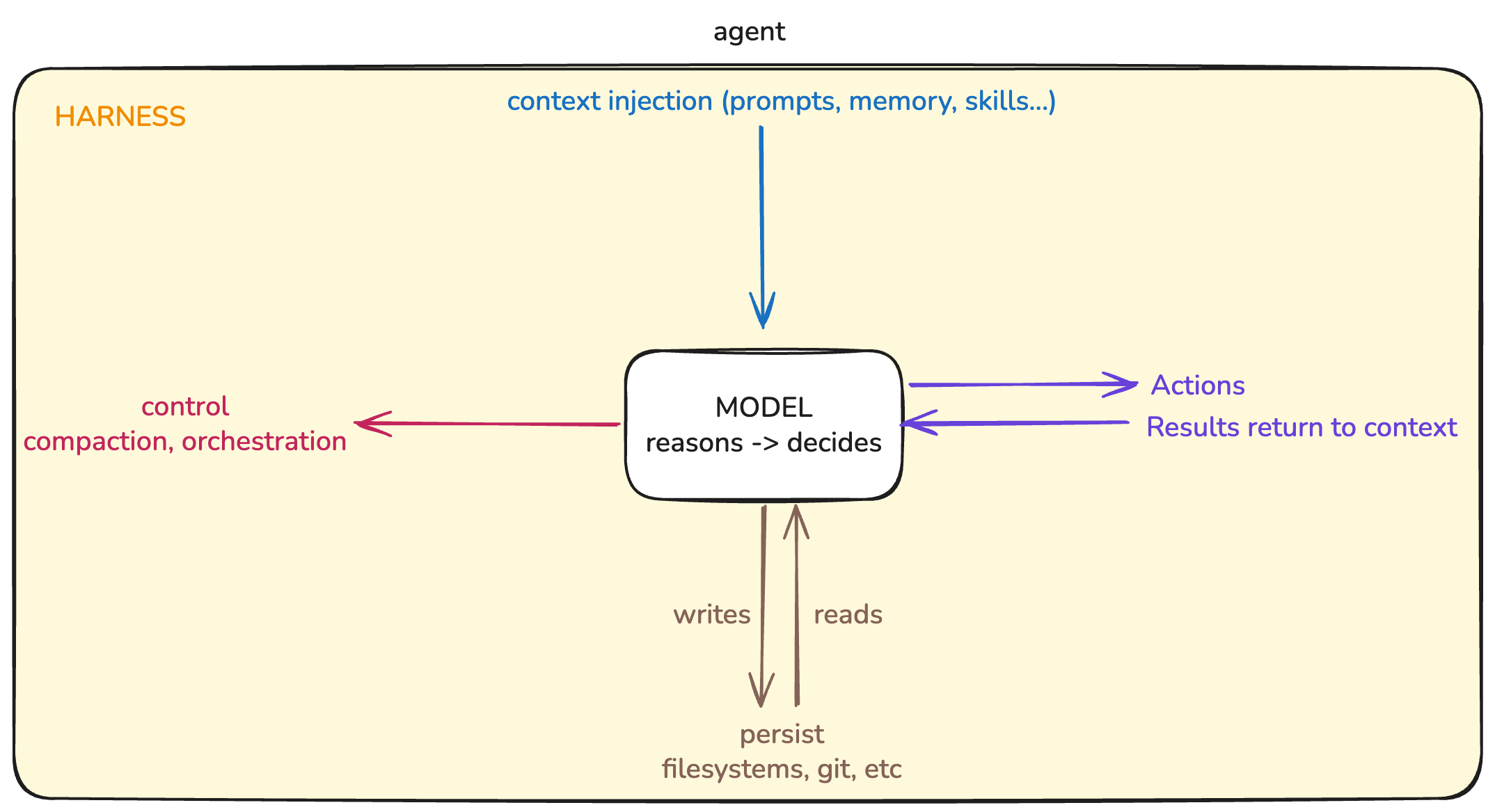
Agent Harness (Khung đỡ cho tác nhân)
Một mô hình không phải là một tác nhân. Harness là thứ biến một mô hình thành tác nhân.
Theo harness, tôi có nghĩa là mọi thứ xung quanh mô hình quyết định cách ngữ cảnh được lắp ráp và duy trì: tuần tự hóa prompt (prompt serialization), định tuyến công cụ (tool routing), chính sách thử lại, các quy tắc chi phối những gì được bảo lưu giữa các bước, v.v.
Sơ đồ mô tả Agent Harness
Khi bạn nhìn vào các hệ thống tác nhân thực theo cách này, nhiều "thất bại của mô hình" được cho là bây giờ trông khác đi. Tôi đã gặp nhiều trường hợp như vậy trong công việc. Thực ra đây là các lỗi của harness: tác nhân quên vì không có gì lưu lại trạng thái phù hợp; nó lặp lại công việc vì harness không hiển thị tạo phẩm bền vững nào của thất bại trước đó; nó chọn sai công cụ vì harness quá tải không gian hành động; v.v.
Một harness tốt, theo một nghĩa nào đó, là một vỏ bọc xác định (deterministic shell) bọc quanh một lõi ngẫu nhiên (stochastic core). Nó làm cho ngữ cảnh rõ ràng, ổn định và có thể khôi phục đủ để mô hình có thể chi tiêu ngân sách lập luận hạn chế của mình cho nhiệm vụ thay vì để tái tạo lại trạng thái của chính nó từ một dấu vết lộn xộn.
Giao tiếp giữa các tác nhân
Khi các nhiệm vụ trở nên phức tạp hơn, các nhóm đã mặc định hướng tới các hệ thống đa tác nhân.
Sai lầm là giả định rằng nhiều tác nhân hơn có nghĩa là ngữ cảnh chia sẻ nhiều hơn. Trong thực tế, đổ một bản ghi chép khổng lồ chia sẻ vào mọi tác nhân con thường tạo ra kết quả ngược lại với sự chuyên môn hóa. Bây giờ mọi tác nhân đều đọc tất cả mọi thứ, kế thừa sai lầm của người khác và trả cùng một hóa đơn ngữ cảnh hết lần này đến lần khác.
Nếu chỉ có một phần ngữ cảnh được chia sẻ, một vấn đề mới xuất hiện. Cái gì được coi là có thẩm quyền khi các tác nhân không đồng ý? Cái gì vẫn giữ nguyên cục bộ, và các xung đột được giải quyết như thế nào?
Cách giải quyết là coi giao tiếp không phải là bộ nhớ chia sẻ, mà là chuyển đổi trạng thái (state transfer) thông qua các giao diện được xác định rõ.
Đối với các nhiệm vụ rời rạc có đầu vào và đầu ra rõ ràng, các tác nhân thường nên giao tiếp thông qua các tạo phẩm (artifacts) thay vì các dấu vết thô (raw traces). Ví dụ, một tác nhân tìm kiếm web không cần chuyển tiếp toàn bộ lịch sử duyệt web. Nó chỉ cần đưa ra tài liệu mà các tác nhân hạ nguồn thực sự có thể sử dụng.
Điều này có nghĩa là lập luận trung gian, các thử nghiệm thất bại và các dấu vết khám phá vẫn giữ riêng trừ khi được yêu cầu rõ ràng. Những gì được chuyển tiếp là các đầu ra chưng cất: các thực tế được trích xuất, các phát hiện đã được xác thực hoặc các quyết định ràng buộc bước tiếp theo.
Đối với các nhiệm vụ kết nối chặt chẽ hơn, như một tác nhân gỡ lỗi nơi lập luận hạ nguồn thực sự phụ thuộc vào các thử nghiệm trước đó, một dạng chia sẻ dấu vết hạn chế có thể được giới thiệu. Nhưng điều này nên có chủ đích và có phạm vi, không phải là mặc định.
Hình phạt bộ nhớ đệm KV (KV Cache Penalty)
Khi các mô hình AI tạo văn bản, chúng thường lặp lại nhiều phép tính giống nhau. KV caching là một kỹ thuật tối ưu hóa thời gian suy luận giúp tăng tốc quá trình này bằng cách ghi nhớ thông tin quan trọng từ các bước trước thay vì tính toán lại tất cả.
Tuy nhiên, trong các hệ thống đa tác nhân, nếu mọi tác nhân chia sẻ cùng một ngữ cảnh, bạn sẽ gây nhầm lẫn cho mô hình với một tấn chi tiết không liên quan và phải chịu mức phạt bộ nhớ đệm KV khổng lồ. Nhiều tác nhân làm việc trên cùng một nhiệm vụ cần giao tiếp với nhau, nhưng điều này không nên thực hiện thông qua việc chia sẻ bộ nhớ.
Đó là lý do tại sao các tác nhân nên giao tiếp thông qua các đầu ra tối thiểu, có cấu trúc theo cách được kiểm soát.
Giữ bộ công cụ của tác nhân nhỏ và phù hợp
Lựa chọn công cụ thực ra là vấn đề ngữ cảnh được ngụy trang thành vấn đề năng lực.
Khi một tác nhân tích lũy nhiều công cụ hơn, không gian hành động trở nên khó điều hướng hơn. Giả sử xác suất mô hình đi theo hành động sai và lấy một tuyến đường kém hiệu quả sẽ cao hơn.
Điều này có hậu quả. Schema công cụ cần phải khác biệt rõ ràng hơn nhiều so với suy nghĩ của hầu hết mọi người. Các công cụ phải được hiểu rõ và có sự chồng chéo tối thiểu về chức năng. Nên rất rõ ràng về việc sử dụng chúng như thế nào và có các tham số đầu vào rõ ràng, không mơ hồ.
Một chế độ thất bại phổ biến mà tôi nhận thấy ngay cả trong nhóm của mình là chúng tôi thường có các bộ công cụ phình to được thêm vào theo thời gian. Điều này dẫn đến việc ra quyết định không rõ ràng về việc nên sử dụng công cụ nào.
Agentic Memory (Bộ nhớ tác nhân)
Đây là một kỹ thuật trong đó tác nhân thường xuyên viết các ghi chú được lưu trữ vào bộ nhớ nằm ngoài cửa sổ ngữ cảnh. Các ghi chú này được kéo trở lại cửa sổ ngữ cảnh vào những thời điểm sau đó.
Phần khó nhất là quyết định cái gì xứng đáng được thăng hạng vào bộ nhớ. Quy tắc của tôi là bộ nhớ bền vững nên chứa những thứ tiếp tục ràng buộc lập luận trong tương lai: các sở thích bền bỉ. Mọi thứ khác nên có rào cản rất cao. Lưu trữ quá nhiều chỉ là một con đường khác quay lại ô nhiễm ngữ cảnh, chỉ rằng giờ đây bạn đã làm cho nó bền vững.
Nhưng bộ nhớ không có sự sửa đổi là một cái bẫy. Một khi các tác nhân duy trì ghi chú qua các bước hoặc phiên làm việc, chúng cũng cần các cơ chế để giải quyết xung đột, xóa và hạ cấp. Nếu không, bộ nhớ dài hạn sẽ trở thành một bãi rác của những niềm tin lỗi thời.
Tóm lại
Context Engineering vẫn đang phát triển và không có cách duy nhất đúng đắn để làm điều đó. Phần lớn nó vẫn mang tính thực nghiệm, được định hình bởi các hệ thống chúng ta xây dựng và các ràng buộc mà chúng ta vận hành.
Nếu không được kiểm tra, ngữ cảnh sẽ phát triển, trôi dạt và cuối cùng sụp đổ dưới chính trọng lượng của nó.
Nếu được quản lý tốt, ngữ cảnh sẽ tạo nên sự khác biệt giữa một tác nhân chỉ biết phản hồi và một tác nhân có thể lập luận, thích ứng và giữ được sự mạch lạc trên các nhiệm vụ dài và phức tạp.
Bài viết liên quan

Công nghệ
Các tác nhân AI đã khiến thế giới công nghệ chao đảo: Câu chuyện đằng sau cuộc cách mạng Claude Code và OpenClaw
26 tháng 5, 2026

Công nghệ
Threads cán mốc 500 triệu người dùng hoạt động hàng tháng
16 tháng 6, 2026

Công nghệ
Alienware 15 mới: Dell đang làm loãng thương hiệu cao cấp vì khủng hoảng RAM?
14 tháng 5, 2026