
Liquid AI ra mắt LFM2.5-8B-A1B: Mô hình AI nhỏ gọn, siêu tốc cho thiết bị cá nhân
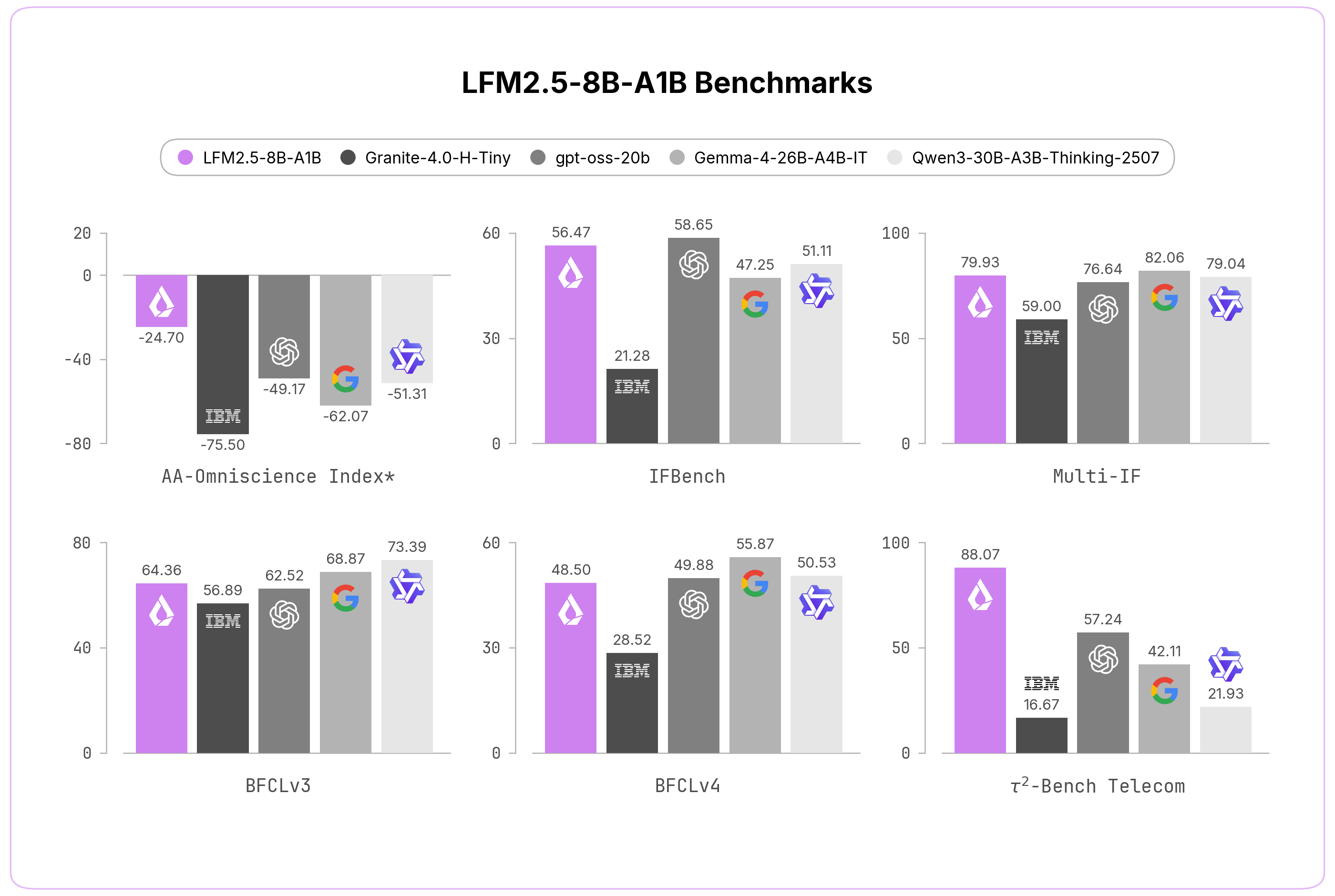
Liquid AI vừa công bố LFM2.5-8B-A1B, mô hình AI thế hệ mới được tối ưu hóa để chạy trực tiếp trên thiết bị người dùng với khả năng gọi công cụ xuất sắc. Mô hình này mở rộng cửa sổ ngữ cảnh lên 128K token, cải thiện đáng kể khả năng xử lý tiếng Việt và đạt hiệu suất suy luận hàng đầu trong phân khúc.
Liquid AI vừa chính thức công bố LFM2.5-8B-A1B, một mô hình ngôn ngữ thế hệ mới được thiết kế đặc biệt cho các thiết bị biên (edge devices). Đây là phiên bản nâng cấp đáng kể từ LFM2-8B-A1B ra mắt vào tháng 10 năm 2025, tập trung vào khả năng gọi công cụ (tool calling) nhanh chóng, đáng tin cậy ngay trên phần cứng tiêu dùng.
Mô hình mới này sở hữu cửa sổ ngữ cảnh mở rộng lên tới 128K token, quy mô huấn luyện tiền luyện (pretraining) được tăng từ 12T lên 38T token, cùng với quá trình học tăng cường quy mô lớn. Đặc biệt, Liquid AI đã nhân đôi kích thước từ vựng lên 128K, giúp tối ưu hóa hiệu suất tokenization cho các ngôn ngữ không phải Latin, bao gồm cả tiếng Việt.
.png) Kiến trúc của LFM2.5-8B-A1B
Kiến trúc của LFM2.5-8B-A1B
Nâng cấp kiến trúc và hỗ trợ đa ngôn ngữ
So với người tiền nhiệm, LFM2.5-8B-A1B mang đến những bước tiến vượt bậc. Cửa sổ ngữ cảnh được mở rộng từ 32.768 lên 128.000 token, cho phép mô hình xử lý các tài liệu dài và duy trì quá trình suy luận trong thời gian dài hơn.
Kích thước từ vựng cũng được tăng từ 65.536 lên 128.000. Việc mở rộng này mang lại lợi ích nén dữ liệu lớn cho nhiều ngôn ngữ như Hindi, Thái Lan, Tiếng Việt, Indonesia và Ả Rập. Kiến trúc của mô hình vẫn duy trì sự kết hợp giữa MoE (Mixture of Experts), GQA và các khối tích chập ngắn có cổng (gated short convolution blocks).
Một thay đổi quan trọng khác là LFM2.5-8B-A1B được thiết kế như một mô hình chỉ tập trung vào suy luận (reasoning-only). Nó sẽ tạo ra một chuỗi suy luận rõ ràng trước khi đưa ra câu trả lời cuối cùng. Chiến lược này tận dụng lợi thế của các mô hình MoE trong môi trường giới hạn về tính toán, giúp giảm chi phí cho mỗi token suy luận mà vẫn tăng cường chất lượng.
Giảm thiểu ảo giác và vòng lặp vô tận
Để giải quyết vấn đề "doom loops" (vòng lặp vô tận) trong các chuỗi suy luận dài, Liquid AI đã thêm một giai đoạn tối ưu hóa ưu tiên có mục tiêu. Giai đoạn này xác định các token có xu hướng gây ra hành vi lặp lại và phân bổ lại xác suất cho các phương án thay thế hợp lý. Ngoài ra, một phần thưởng hình dạng nhẹ cũng được áp dụng để hạn chế việc sử dụng quá mức các từ khởi động lại gây lặp.
Về vấn đề ảo giác (hallucinations), do các mô hình biên có dung lượng kiến thức hạn chế, nhóm phát triển đã triển khai một giai đoạn RL sử dụng phần thưởng dựa trên avg@k trên tập dữ liệu kiến thức đa dạng. Mục tiêu là củng cố khả năng từ chối trả lời các câu hỏi vượt quá kiến thức đáng tin cậy, từ đó tạo ra ranh giới kiến thức sắc bén hơn và thể hiện sự không chắc chắn một cách rõ ràng.
Hiệu suất suy luận ấn tượng
LFM2.5-8B-A1B được tối ưu hóa để chạy mượt mà trên nhiều nền tảng phần cứng khác nhau ngay từ ngày đầu ra mắt.
Suy luận trên CPU
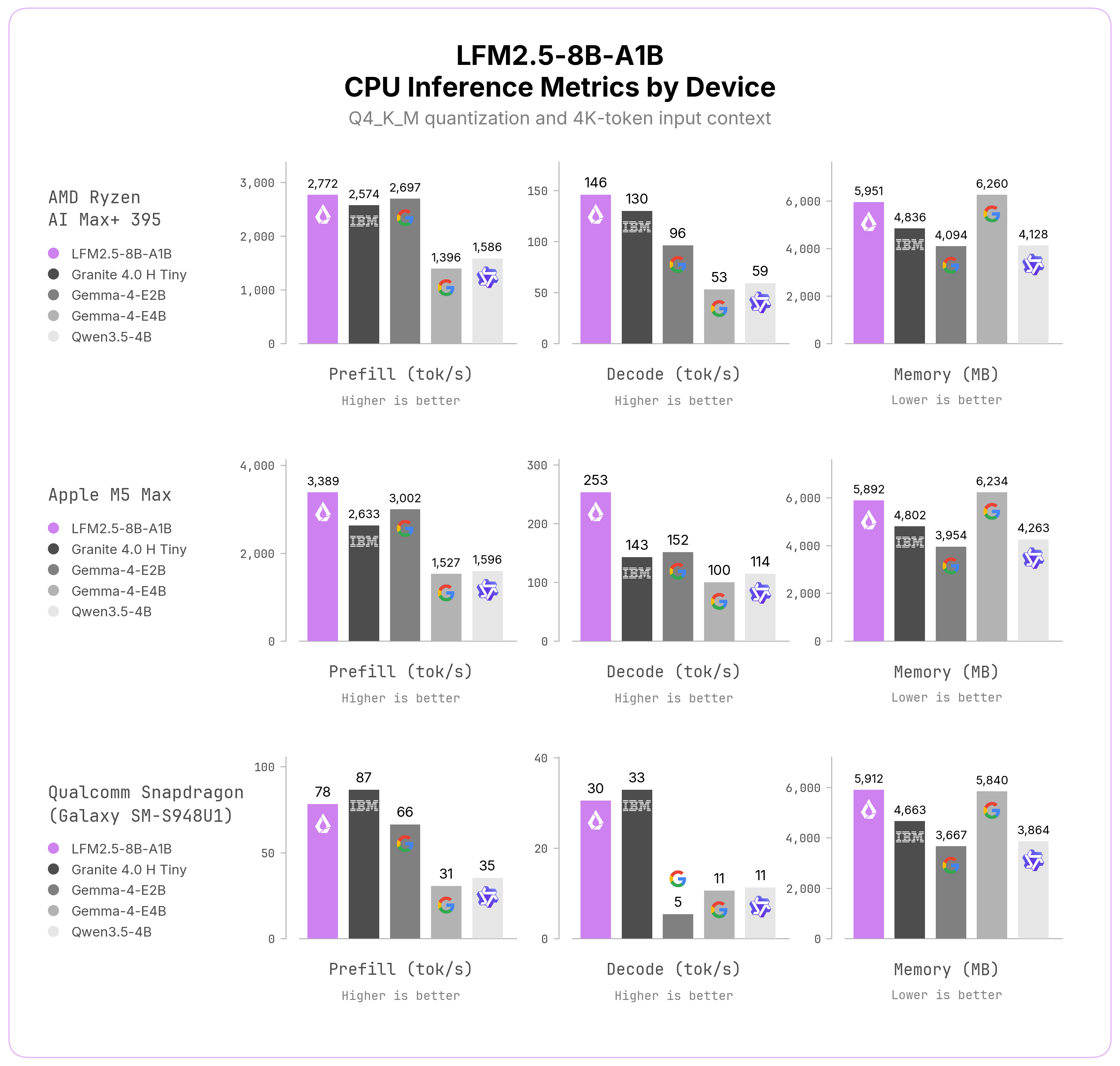
Mô hình hỗ trợ llama.cpp và có thể chạy trên phần cứng tiêu dùng hàng ngày. Trên các chip laptop cấp cao, đây là mô hình nhanh nhất trong các thử nghiệm về tốc độ đọc câu lệnh và tạo câu trả lời.
 Hiệu suất CPU của LFM2.5-8B-A1B
Hiệu suất CPU của LFM2.5-8B-A1B
Cụ thể, mô hình đạt tốc độ giải mã 253 token/giây trên chip M5 Max và 146 token/giây trên Ryzen AI Max+ 395, trong khi mức tiêu thụ RAM vẫn dưới 6 GB. Ngay cả trên điện thoại, mô hình vẫn duy trì tốc độ khoảng 30 token/giây, cho phép một trợ lý AI mạnh mẽ hoạt động tức thì và riêng tư ngay trên thiết bị của bạn.
Suy luận trên GPU
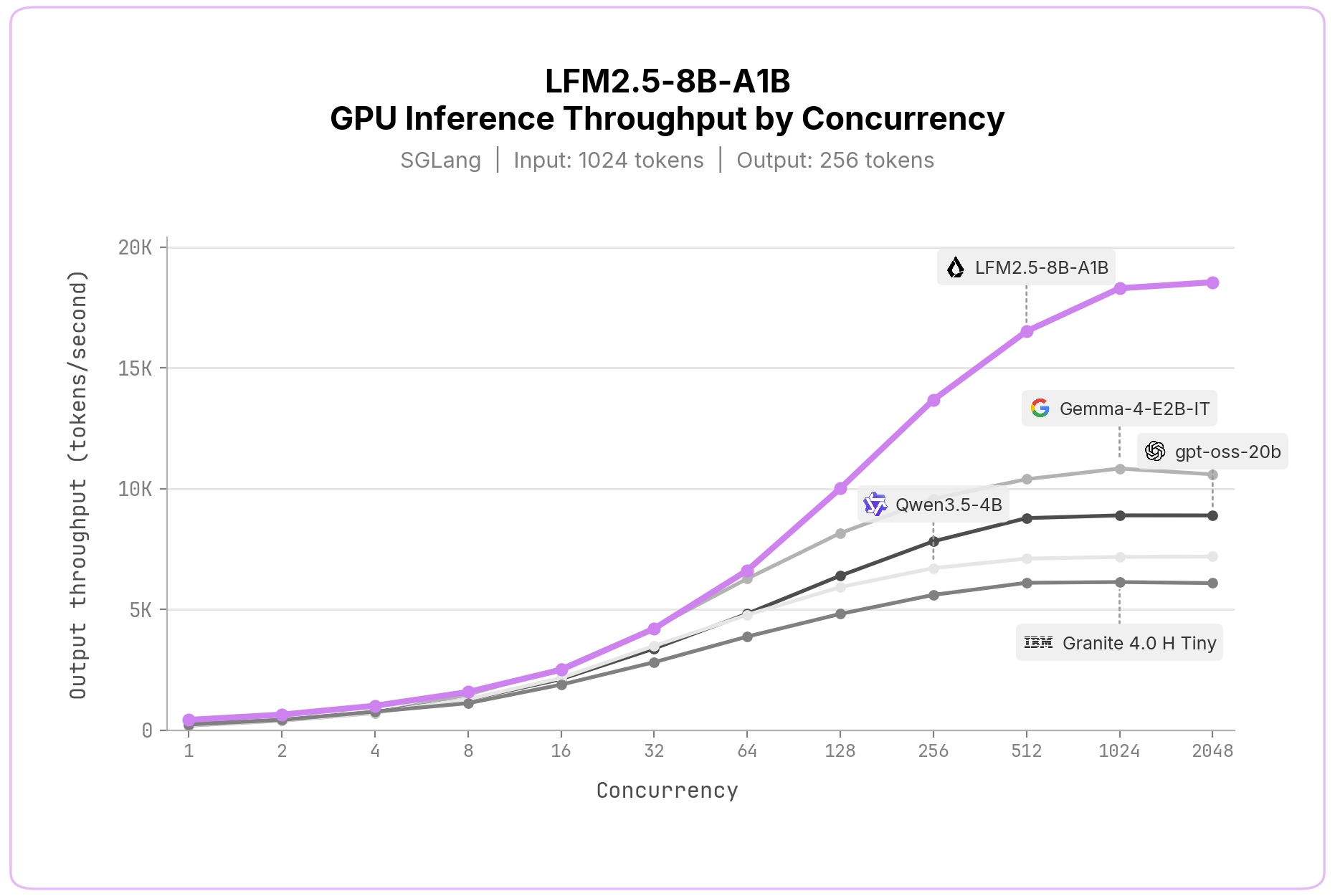
Liquid AI cũng hỗ trợ suy luận qua vLLM và SGLang. Khi đo lường trên một GPU NVIDIA H100 SXM5 duy nhất, LFM2.5-8B-A1B là mô hình nhanh nhất trong phân khúc kích thước của nó, đạt tốc độ 18.500 token đầu ra mỗi giây ở mức độ đồng thời cao, tương đương hơn 1,6 tỷ token mỗi ngày trên một card H100.
 Hiệu suất GPU của LFM2.5-8B-A1B
Hiệu suất GPU của LFM2.5-8B-A1B
Tương lai của Agent cục bộ
Bản demo LocalCowork, một tác nhân desktop mã nguồn mở của Liquid AI, hiện đã chạy trên LFM2.5-8B-A1B. Cài đặt demo sử dụng một chiếc laptop duy nhất với 67 công cụ trên 13 máy chủ MCP, hoàn toàn không sử dụng đám mây, không cần API key và không có dữ liệu nào rời khỏi máy.
Việc lựa chọn công cụ nhanh hơn và đáng tin cậy hơn nhiều trên cùng một menu công cụ. Mục tiêu của bản demo này là chứng minh rằng vòng lặp điều phối công cụ mang tính tương tác cao trên phần cứng tiêu dùng: hỏi, đề xuất, xác nhận, chạy, lặp lại, tất cả trong dưới một giây cho mỗi lần điều phối, với đầy đủ nhật ký kiểm toán và dữ liệu không bao giờ rời khỏi thiết bị.
Với LFM2.5, Liquid AI đang hiện thực hóa tầm nhìn về AI có thể chạy ở bất cứ đâu. Các phiên bản Base (LFM2.5-8B-A1B-Base) và Post-trained (LFM2.5-8B-A1B) hiện đã có sẵn trên Hugging Face và Playground của Liquid AI.
Bài viết liên quan

Công nghệ
Sự trở lại của Xbox: Chiến lược mới, thay đổi nhân sự và tương lai Project Helix
07 tháng 5, 2026

Công nghệ
Samsung Galaxy Book6 Ultra: Bản sao MacBook Pro đắt đỏ nhưng đầy khiếm khuyết
07 tháng 5, 2026

Công nghệ
Tạm biệt "Ferrynoia": Công nghệ hàng hải xanh đang thay đổi ngành vận tải thủy
05 tháng 6, 2026