
Mạng Bayesian và Mạng Markov: Hướng dẫn trực quan về sự không chắc chắn có cấu trúc
Bài viết khám phá cách lý luận với sự không chắc chắn trong trí tuệ nhân tạo, từ các mạng Bayesian có hướng đến mạng Markov không hướng, và cách chúng mô hình hóa các biến phức tạp thông qua cấu trúc đồ thị.
Mạng Bayesian và Mạng Markov: Hướng dẫn trực quan về sự không chắc chắn có cấu trúc
Hầu hết các giải thích về học máy đều bắt đầu từ việc dự đoán. Một mô hình dự đoán khách hàng rời bỏ (churn) ước tính liệu một người dùng có khả năng ra đi hay không. Một mô hình phát hiện gian lận ước tính xem một giao dịch có đáng ngờ hay không. Một mô hình chẩn đoán ước tính khả năng mắc bệnh từ các triệu chứng và lịch sử bệnh án.
Trong mỗi trường hợp, cách thiết lập về cơ bản là giống nhau. Chúng ta có một số thông tin quan sát được (thường được gọi là đầu vào hoặc đặc trưng - inputs/features) và một thứ chúng ta muốn dự đoán (thường được gọi là mục tiêu - target). Nếu viết đầu vào là X và mục tiêu là Y, thì bài toán học có giám sát thông thường là học một mô hình của:
P(Y | X)
Tức là, cho các đầu vào, khả năng của mỗi kết quả đầu ra có thể là bao nhiêu? Khung lý thuyết này rất hữu ích, mang lại cho chúng ta hồi quy logistic, máy vector hỗ trợ (SVM), rừng ngẫu nhiên, tăng cường độ dốc (gradient boosting), mạng nơ-ron và một phần lớn ứng dụng học máy hiện đại.
Tuy nhiên, mạng Bayesian xuất phát từ một bản năng mô hình hóa khác biệt. Chúng hữu ích khi chúng ta muốn đại diện cho một thế giới không chắc chắn nhỏ thay vì chỉ học một ánh xạ từ đầu vào đến một đầu ra duy nhất. Thay vì chia thế giới thành "đầu vào" và "mục tiêu", chúng ta mô tả một tập hợp các biến không chắc chắn:
X₁, …, Xₙ
Một số biến này có thể được quan sát, một số có thể bị ẩn, và bất kỳ biến nào trong số đó có thể trở thành thứ chúng ta quan tâm dự đoán. Đồ thị mô tả cách các biến không chắc chắn này phụ thuộc vào nhau, bằng chứng có thể nhập vào đâu, và niềm tin nên được cập nhật như thế nào khi thông tin mới đến.
Một bộ phân loại thường được xây dựng xung quanh một câu hỏi dự đoán: Cho các đầu vào này, kết quả là gì? Một mạng Bayesian được xây dựng xung quanh một câu hỏi không chắc chắn tổng quát hơn: Những thứ không chắc chắn này có liên quan. Cho bằng chứng ở bất kỳ đâu trong hệ thống, bây giờ chúng ta nên tin điều gì về phần còn lại?
 Cấu trúc đồ thị
Cấu trúc đồ thị
Thay vì chỉ hỏi P(Y | X), chúng ta đại diện cho một phân phối liên hợp đầy đủ hơn trên các biến:
P(X₁, …, Xₙ)
Mục đích của đồ thị là làm cho phân phối liên hợp đó trở nên dễ quản lý bằng cách mã hóa các biến phụ thuộc trực tiếp vào biến nào khác.
Phân phối liên hợp đầy đủ là thứ chúng ta không thể chi trả
Hãy tưởng tượng một thế giới nhỏ với một vài sự thật không chắc chắn: trời nhiều mây, có mưa, vòi phun nước bật, cỏ ướt, đường trơn, tắc đường và đến muộn. Về nguyên tắc, mô hình xác suất hoàn chỉnh nhất sẽ mô tả xác suất của mọi cấu hình có thể:
P(Cloudy, Rain, Sprinkler, WetGrass, SlipperyPavement, Traffic, LateArrival)
Đây là phân phối liên hợp đầy đủ. Nếu chúng ta có nó, chúng ta có thể hỏi gần như mọi thứ. Tuy nhiên, vấn đề là phân phối liên hợp đầy đủ tăng lên cực kỳ nhanh. Nếu mỗi biến là nhị phân, thì n biến yêu cầu 2ⁿ cấu hình có thể. Bảy biến đã cho 128 trạng thái. Hai mươi biến cho hơn một triệu. Một trăm biến là nằm ngoài tầm với.
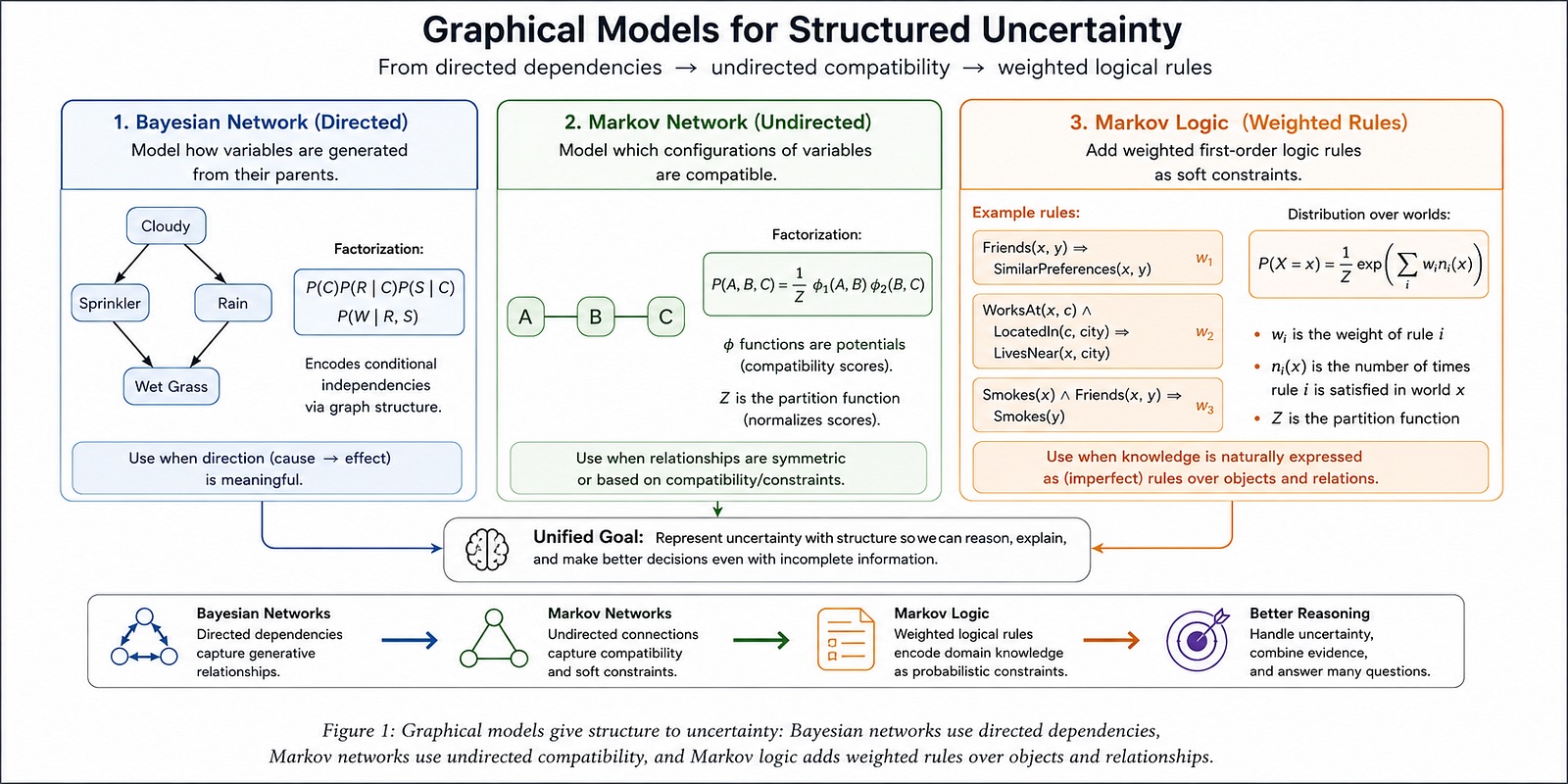
Đây là lúc các mô hình đồ thị (graphical models) xuất hiện. Một mô hình đồ thị là một cách đại diện thu gọn của một phân phối xác suất bằng cách đưa ra các giả định về cấu trúc. Đồ thị nói rằng các mối quan hệ cục bộ nào chúng ta mô hình hóa trực tiếp và các mối quan hệ nào chúng ta coi là hệ quả gián tiếp của các mảnh cục bộ đó.
Ý tưởng trung tâm rất đơn giản: Đừng mô hình hóa cả thế giới không chắc chắn như một bảng khổng lồ. Hãy chia nó thành các mảnh có điều kiện nhỏ hơn.
Mạng Bayesian là bản đồ có hướng của sự phụ thuộc cục bộ
Hãy lấy ví dụ kinh điển về cỏ ướt. Bạn bước ra ngoài và thấy cỏ ướt. Có thể đã có mưa. Có thể vòi phun nước đang bật. Có thể cả hai đều xảy ra. Mô hình nói rằng mưa và vòi phun nước đều ảnh hưởng đến việc cỏ có ướt hay không. Phân phối xác suất được phân rã thành:
P(Rain, Sprinkler, WetGrass) = P(Rain) P(Sprinkler) P(WetGrass | Rain, Sprinkler)
Thay vì viết một bảng cho mọi kết hợp của mưa, vòi phun và cỏ ướt, chúng ta viết các mảnh nhỏ hơn: P(Rain), P(Sprinkler), và P(WetGrass | Rain, Sprinkler). Mỗi biến nhận được một mô hình xác suất cục bộ được điều kiện hóa theo các "cha" của nó.
Một mạng Bayesian nhỏ trong Python
Để làm rõ điều này, hãy xây dựng phiên bản mô hình cỏ ướt nhỏ nhất hữu ích: mưa có thể xảy ra hoặc không, vòi phun có thể bật hoặc tắt, và cỏ có thể ướt hoặc không. Cấu trúc rất đơn giản.
from itertools import product
# Xác suất tiên nghiệm
P_RAIN = {True: 0.2, False: 0.8}
P_SPRINKLER = {True: 0.1, False: 0.9}
# Bảng xác suất có điều kiện: P(WetGrass = True | Rain, Sprinkler)
P_WET_GIVEN_RAIN_SPRINKLER = {
(False, False): 0.01,
(False, True): 0.80,
(True, False): 0.90,
(True, True): 0.99,
}
def joint_probability(rain, sprinkler, wet):
return (
P_RAIN[rain] *
P_SPRINKLER[sprinkler] *
(P_WET_GIVEN_RAIN_SPRINKLER[(rain, sprinkler)] if wet else 1 - P_WET_GIVEN_RAIN_SPRINKLER[(rain, sprinkler)])
)
Đây là toàn bộ mạng Bayesian. Không có thư viện, không có fitting, không có máy móc ẩn đằng sau API. Cấu trúc của mô hình hiển thị trong phép nhân. Bây giờ chúng ta có thể liệt kê mọi thế giới có thể và tính toán xác suất.
 Ví dụ Python
Ví dụ Python
Đặt câu hỏi cho mô hình và Hiện tượng "Explaining Away"
Khi đã có phân phối liên hợp, chúng ta có thể đặt câu hỏi. Ví dụ: Nếu cỏ ướt, khả năng đã có mưa là bao nhiêu? P(Rain | WetGrass). Trong mô hình nhỏ này, khi quan sát thấy cỏ ướt, xác suất mưa tăng từ giá trị tiên nghiệm 0.2 lên khoảng 0.69. Đó là cập nhật Bayesian.
Cỏ ướt cũng làm cho vòi phun nước có khả năng xảy ra hơn (tăng từ 0.1 lên khoảng 0.36). Điều đó hợp lý. Cỏ ướt là bằng chứng cho cả hai nguyên nhân có thể.
Bây giờ hãy xem hiện tượng "giải thích loại trừ" (explaining away). Giả sử chúng ta biết hai điều: cỏ ướt và chắc chắn đã có mưa. Vòi phun nước có khả năng đã bật không?
Kết quả là khoảng 0.11, thấp hơn nhiều so với 0.36 khi chỉ biết cỏ ướt. Khi chỉ biết cỏ ướt, vòi phun nước trở nên hợp lý hơn. Một khi biết rằng đã có mưa, vòi phun nước trở nên ít cần thiết hơn như một lời giải thích. Đây là "explaining away". Cỏ ướt. Lúc đầu, mưa và vòi phun đều là những lời giải thích hợp lý. Khi mưa đã được biết, một phần áp lực bằng chứng lên vòi phun biến mất.
Đồ thị mã hóa những gì không còn quan trọng
Bây giờ hãy thêm sự nhiều mây (Cloudy). Sự nhiều mây ảnh hưởng đến việc có mưa hay không, và cũng có thể ảnh hưởng đến việc ai đó bật vòi phun nước. Mưa và vòi phun sau đó ảnh hưởng đến việc cỏ có ướt hay không.
Mô hình nói rằng cỏ ướt phụ thuộc trực tiếp vào mưa và vòi phun. Nó có thể phụ thuộc gián tiếp vào sự nhiều mây, nhưng một khi chúng ta biết liệu đã có mưa và vòi phun có bật hay không, sự nhiều mây không còn thêm gì về việc cỏ ướt. Về mặt hình thức: Cỏ ướt độc lập với sự nhiều mây khi biết Mưa và Vòi phun.
Đó là một trong những ý tưởng hữu ích nhất trong mạng Bayesian. Chúng mã hóa sự độc lập có điều kiện. Chúng cho chúng ta biết thông tin nào trở nên dư thừa khi các thông tin khác đã được biết.
Mạng Markov: Khi hướng không còn quan trọng
Mạng Bayesian sử dụng các cạnh có hướng. Các mũi tên quan trọng. Tuy nhiên, một số lĩnh vực có các mối quan hệ mà hướng trở nên lúng túng. Hãy xem xét khử nhiễu hình ảnh. Các điểm ảnh lân cận có xu hướng có nhãn tương tự. Nếu một điểm ảnh là tiền cảnh, các lân cận của nó có khả năng cũng là tiền cảnh. Điểm ảnh nào gây ra điểm ảnh nào? Thường thì không có. Mối quan hệ là đối xứng.
Đây là nơi mạng Markov (Markov networks), hay còn gọi là trường ngẫu nhiên Markov (Markov Random Fields), trở nên tự nhiên. Mạng Markov là một mô hình đồ thị không có hướng. Thay vì các mũi tên và bảng xác suất có điều kiện, nó sử dụng các hàm tương thích (compatibility functions) trên các nhóm biến được kết nối.
Một trực giác hữu ích là:
- Một mạng Bayesian mô tả cách các biến được sinh ra từ các cha của chúng.
- Một mạng Markov mô tả cấu hình nào của các biến là tương thích.
Mạng Bayesian cảm thấy như một câu chuyện nhân quả hoặc chẩn đoán. Mạng Markov cảm thấy như một hệ thống các ràng buộc mềm. Sử dụng mạng Bayesian khi hướng có ý nghĩa (bệnh gây ra triệu chứng). Sử dụng mạng Markov khi sự tương thích tự nhiên hơn hướng (các điểm ảnh lân cận nên đồng thuận).
Suy luận và Cây giao lộ (Junction Tree)
Khi đã có một đồ thị và các bảng xác suất cục bộ, suy luận (inference) có nghĩa là trả lời các câu hỏi như P(Rain | WetGrass). Cơ chế có thể mang tính kỹ thuật cao: loại bỏ biến, truyền niềm tin, cây giao lộ, các phương pháp lấy mẫu. Nhưng trực giác thì đơn giản. Bằng chứng đi vào đồ thị. Niềm tin được cập nhật cục bộ. Các cập nhật đó lan truyền qua các biến được kết nối.
Trong các đồ thị có dạng cây, điều này có thể hiệu quả và chính xác. Trong các đồ thị dày đặc hoặc có vòng lặp (loopy), suy luận có thể trở nên đắt đỏ. Một cây giao lộ (junction tree) là một cách tổ chức lại đồ thị để suy luận chính xác trở nên khả thi.
Ý tưởng là: lấy mô hình đồ thị ban đầu, nhóm các biến được kết nối chặt chẽ thành các cụm, và sắp xếp các cụm đó thành một cây. Thay vì chuyển tin nhắn giữa các biến riêng lẻ, thuật toán chuyển tin nhắn giữa các cụm biến.
 Cây giao lộ
Cây giao lộ
Phương pháp này chính xác, nhưng có cái giá. Mỗi cụm cần một bảng trên tất cả các biến của nó. Nếu một cây giao lộ tạo ra một cụm với 20 biến nhị phân, cụm đó có hơn 1 triệu trạng thái. Bài học thực tế là mạng Bayesian dễ lý luận hơn khi đồ thị thưa và các phụ thuộc là cục bộ.
Kết luận
Mạng Bayesian và mạng Markov cung cấp một ngôn ngữ mạnh mẽ để lý luận về sự không chắc chắn có cấu trúc. Khác với các bộ phân loại học có giám sát truyền thống chỉ ánh xạ đầu vào đến đầu ra, các mô hình này đại diện cho một hệ thống các biến phụ thuộc lẫn nhau.
Chúng cho phép chúng ta đưa bằng chứng ở bất kỳ đâu, cập nhật niềm tin theo nhiều hướng, và xử lý các tình huống thiếu dữ liệu hoặc cần giải thích nguyên nhân. Tuy nhiên, sức mạnh này đi kèm với chi phí: ai đó phải tin vào cấu trúc đồ thị, và việc học cấu trúc đó từ dữ liệu đòi hỏi kỷ luật mô hình hóa chặt chẽ.
Bài viết liên quan

Công nghệ
Anthropic và OpenAI mang cuộc chiến công nghệ sang chính trường Mỹ
20 tháng 5, 2026

Phần cứng
Cerebras khẳng định chip của họ chạy mô hình AI nghìn tham số nhanh hơn gấp 7 lần so với đám mây GPU
20 tháng 5, 2026

Phần cứng
Nvidia chính thức đưa siêu vi xử lý Grace Blackwell lên PC với dòng notebook RTX Spark
01 tháng 6, 2026