
Mô hình AI chưa bao giờ thực sự 'xong': Hiểu và xử lý Model Drift
Model Drift là hiện tượng hiệu suất của mô hình dự đoán suy giảm theo thời gian, ngay cả khi nó đã được huấn luyện kỹ lưỡng. Bài viết này sẽ giải thích cơ chế, cách phát hiện sớm và các phương pháp khắc phục để duy trì độ chính xác và niềm tin vào hệ thống.

Bạn đã làm được rồi.
Mô hình của bạn đã được đưa vào môi trường sản xuất (production). Nó đang đưa ra các dự đoán và phục vụ cho các bên liên quan (stakeholders). Quy trình dữ liệu đã được tự động hóa. Đã đến lúc ngả lưng thư giãn, công việc của bạn đã hoàn tất.
Tôi cũng thích mơ mộng như vậy.
Được rồi, hãy quay lại thực tế. Hãy cùng thảo luận về Model Drift (sự trôi dạt của mô hình): nó là gì, tại sao nó lại xảy ra, cách phát hiện và cách giải quyết trước khi nó âm thầm phá hủy hiệu suất cũng như niềm tin của mọi người vào mô hình.
 Hình ảnh minh họa trừu tượng về dữ liệu
Hình ảnh minh họa trừu tượng về dữ liệu
Model Drift là gì?
Model Drift là sự suy giảm hiệu suất của một mô hình dự đoán theo thời gian. Ngay cả những mô hình mạnh mẽ và chính xác nhất cũng có nguy cơ gặp phải tình trạng này. Model Drift không phải là phản ánh của kỹ thuật huấn luyện kém hay quá trình thu thập dữ liệu sai sót, mà là điều mà mọi nhà khoa học dữ liệu phải luôn giữ mắt nhìn chằm chằm.
Hãy xem một ví dụ. Một mô hình bộ phân loại nhị phân được huấn luyện trên dữ liệu lịch sử hai năm. Hiệu suất rất tốt, AUC ở mức thấp 0.9, độ chính xác (precision) và độ phủ (recall) đều đủ cao. Mô hình vượt qua giai đoạn đánh giá ngang hàng và được đưa vào môi trường sản xuất. Tại đây, nó bắt đầu đưa ra các dự đoán theo thời gian thực. Sau 90 ngày, nhà khoa học dữ liệu truy vấn các dự đoán mà mô hình đã thực hiện trong sản xuất và chạy chúng qua một tập lệnh xác thực tính toán các chỉ số hiệu suất. Hiệu suất hoàn toàn phù hợp với kỳ vọng từ POC (bằng chứng khái niệm), và thông báo được gửi đến các bên liên quan: "Mô hình đang hoạt động như mong đợi. Các dự đoán là chính xác."
Nhảy nhanh lên hai năm sau. Có một yêu cầu điều tra mô hình. Được báo cáo là mô hình liên tục đưa ra các dự đoán sai, và các bên liên quan đang mất niềm tin vào nó. Thậm chí có đề xuất sử dụng lại phương pháp bảng tính Excel cũ nếu tình trạng này tiếp diễn. Nhà khoa học dữ liệu truy vấn dữ liệu 6 tháng qua và chạy nó qua tập lệnh xác thực. Nhà khoa học dữ liệu dụi mắt, kiểm tra ghi chú của mình và hoàn toàn ngỡ ngàng. AUC rơi xuống mức 0.6, precision và recall đều cực kỳ thấp. "Làm sao chuyện này có thể xảy ra? Tôi đã huấn luyện một mô hình tốt. Tôi thậm chí đã xác thực mô hình sau khi nó chạy trực tiếp! Đã có chuyện gì xảy ra?", nhà khoa học dữ liệu tự hỏi. Đó chính là Model Drift. Nó đã lẻn vào, không bị phát hiện trong nhiều tháng và gây ra sự hỗn loạn cho các dự đoán.
Đó là thực tế khắc nghiệt mà nhiều mô hình dự đoán phải đối mặt trong môi trường sản xuất. Hãy nói về lý do tại sao nó lại xảy ra.
Tại sao Model Drift lại xảy ra?
Tóm lại, Model Drift xảy ra vì các mô hình sống trong thế giới thực. Mô hình được huấn luyện trên một thực tế, và thực tế đó đã thay đổi theo một cách nào đó kể từ khi được triển khai.
Một trong những nguyên nhân phổ biến nhất của Model Drift là sự thay đổi trong cách ghi lại dữ liệu. Khi dữ liệu ban đầu được thu thập để huấn luyện, các đặc trưng dự đoán và mục tiêu trông có vẻ theo một cách, và bây giờ, chúng đã khác. Thuật toán đã học được mối quan hệ cụ thể giữa chúng, nhưng bây giờ, mối quan hệ đó đã thay đổi. Mô hình chưa học được cách xử lý mối quan hệ mới, vì vậy nó tiếp tục đưa ra dự đoán tốt nhất có thể dựa trên cách nó được huấn luyện.
Model Drift thường chia thành hai loại chính:
- Data Drift (Trôi dạt dữ liệu): Các đặc trưng đầu vào thay đổi.
- Concept Drift (Trôi dạt khái niệm): Các mối quan hệ thay đổi hoặc sự dịch chuyển dân số.
Hãy xem một số ví dụ.
Ví dụ #1: Data Drift
Chiều cao và cân nặng được sử dụng để dự đoán nguy cơ mắc tiểu đường. Nhà khoa học dữ liệu đã thu thập dữ liệu của bệnh nhân trong hai năm, đảm bảo lấy chiều cao tính bằng inch, cân nặng tính bằng pound và xem liệu bệnh nhân đó có bị tiểu đường một năm sau khi được đo hay không. Hai năm sau, quy trình đo lường mới yêu cầu y tá ghi lại chiều cao bằng centimet và cân nặng bằng kilogam, và mô hình bắt đầu đưa ra các dự đoán sai lệch nghiêm trọng vì điều này. Ví dụ, một bệnh nhân cao 6 feet trước đây có chiều cao được ghi là 72 inch, nhưng bây giờ được ghi là 183 centimet. Bệnh nhân này nặng 200 pound, hiện được ghi là 91 kilogam. Mô hình không biết rằng cần phải thực hiện chuyển đổi đổi để tính đến sự thay đổi về đơn vị. Nó mong muốn được cung cấp các đặc trưng theo các đơn vị mà nó đã được huấn luyện, vì vậy nó dự đoán như thể người đó cao 183 inch (hơn 15 feet) và nặng 91 pound. Không lạ gì khi dự đoán đó không có ý nghĩa gì!
 Ví dụ về các loại Model Drift
Ví dụ về các loại Model Drift
Ví dụ #2: Concept Drift
Một mô hình dự đoán nguy cơ tái nhập viện được xây dựng cho một hệ thống bệnh viện bởi nhóm khoa học dữ liệu của họ. Ba năm sau khi đi vào hoạt động, hệ thống của họ mua lại bốn bệnh viện lớn ở bang lân cận. Những bệnh viện này có cơ cấu bệnh nhân đa dạng khác nhau, khác biệt đáng kể so với dân số ban đầu mà mô hình được huấn luyện. Khi mô hình được triển khai tại các bệnh viện mới, các nhân viên y tế nhận thấy nó đang đưa ra nhiều dự đoán dương tính giả và âm tính giả. Mô hình cần được huấn luyện lại để bao gồm dữ liệu từ các bệnh viện mới này.
Cách phát hiện và khắc phục Model Drift
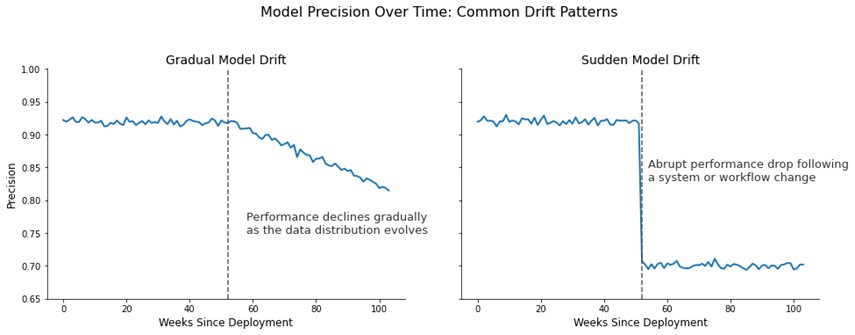
Model Drift có thể xảy ra dần dần, với hiệu suất suy giảm chậm trong một thời gian dài, hoặc nó có thể xảy ra nhanh chóng, với hiệu suất giảm đột ngột và rõ ràng. Bản chất thay đổi này có thể khiến việc chuẩn bị trở nên khó khăn và thậm chí khó phát hiện hơn nếu không có các công cụ phù hợp.
 Giám sát hiệu suất mô hình
Giám sát hiệu suất mô hình
Giám sát hiệu suất trong môi trường sản xuất thường xuyên là cách tốt nhất để phát hiện Model Drift.
Nếu bạn không giám sát mô hình của mình trong môi trường sản xuất, bạn sẽ không nhận thấy sự trôi dạt cho đến khi các bên liên quan phát hiện ra.
Một bảng điều khiển (dashboard) nhanh hoặc một notebook có thể chạy mỗi vài tuần có thể là một cách đơn giản để trực quan hóa hiệu suất của mô hình và bắt kịp bất kỳ sự suy giảm nào theo thời gian. Chỉ cần vẽ các chỉ số hiệu suất phù hợp cho mô hình của bạn như precision, recall, AUC, MAE, MSE trên trục y, và ngày tháng trên trục x. Những gì bạn nên mong đợi là sự biến động nhỏ tuần này qua tuần khác, nhưng sự lệch lớn so với mức trung bình tín hiệu cho thấy một điều gì đó đã thay đổi, và trôi dạt có thể đang xảy ra. Biểu đồ sự thiếu hụt đặc trưng (feature missingness) và phân phối đặc trưng cũng có thể giúp bạn đi sâu vào từng yếu tố dự báo riêng lẻ, giúp bạn xác định nguyên nhân của sự trôi dạt. Điều này có thể giống như số lượng giá trị NA hoặc NULL trên mỗi đặc trưng theo thời gian, hoặc giá trị trung bình trên mỗi đặc trưng theo thời gian.
Tôi thực sự đã bắt gặp Model Drift trong một trong các mô hình của mình bằng phương pháp trên. Tôi nhận thấy sự sụt giảm về độ chính xác trong mô hình dự đoán khó tiếp cận tĩnh mạch (Difficult IV Access) của mình. Sau vài tuần có giá trị độ chính xác liên tục thấp hơn mong đợi, tôi bắt đầu nghi ngờ. Quản lý của tôi đã đề xuất xem xét sự thiếu hụt đặc trưng như một nguyên nhân tiềm năng. Không ngờ, đặc trưng quan trọng thứ ba, tiền sử suy dinh dưỡng, đã có sự gia tăng lớn các giá trị NULL ngay trong tuần mà hiệu suất của mô hình bắt đầu suy giảm. Chúng tôi đã phát hiện ra rằng câu lệnh SQL điều chỉnh việc tạo đặc trưng trong môi trường sản xuất đã được điều chỉnh một chút, và một phép nối (join) không hoạt động như dự định. Chúng tôi đã cập nhật SQL và độ chính xác đã trở lại mức bình thường từ ngày hôm đó.
Điều này đưa tôi đến điểm cuối cùng: cách khắc phục Model Drift. Có một số cách để khắc phục sự trôi dạt, mỗi cách phù hợp trong các kịch bản khác nhau. Như bạn đã thấy ở trên, một cách để khắc phục sự trôi dạt là sửa chữa các đầu vào/dữ liệu về cùng định dạng mà nó tồn tại trong quá trình huấn luyện mô hình. Đây là cách đơn giản và nhanh nhất để khắc phục sự trôi dạt, và nên là phương pháp mặc định nếu có thể. Điều này có thể được thực hiện ở bất kỳ đâu trong quy trình tải dữ liệu, từ ETL cơ sở dữ liệu, đến mã notebook hạ lưu nơi các dự đoán được thực hiện. Nếu chiều cao được ghi bằng centimet và mô hình của bạn mong muốn nó tính bằng inch, việc chuyển đổi có thể được thực hiện trước khi dự đoán.
Tuy nhiên, đôi khi dữ liệu không thể thay đổi. Có lẽ quản trị dữ liệu đã định nghĩa một điểm dữ liệu một cách chính thức hơn, và bây giờ các đơn vị được chuẩn hóa, và những đơn vị đó khác với đơn vị mà mô hình của bạn được huấn luyện. Hoặc, một quy trình công việc ngăn chặn dữ liệu được tải ở cùng định dạng. Một giải pháp khác, mặc dù đòi hỏi nhiều công sức hơn một chút, là huấn luyện lại mô hình (retrain). Việc huấn luyện lại mô hình trên dữ liệu mới cho phép nó học lại mối quan hệ giữa các biến, thiết lập một mô hình hoạt động đáng tin cậy trên dữ liệu mới mà nó đang được cung cấp. Những thay đổi trong dân số hầu như luôn yêu cầu huấn luyện lại mô hình.
Tổng kết
Model Drift có thể ập đến bất ngờ với bất kỳ nhà khoa học dữ liệu nào. Để nó kéo dài đủ lâu, nó có thể phá hủy hiệu suất và niềm tin của người dùng. Nhưng, đó không phải là điều đáng sợ. Với các công cụ phù hợp, việc phát hiện sự trôi dạt là khả thi, và việc khắc phục nó là có thể đạt được. Khả năng nhận biết khi nào Model Drift đang xảy ra, và có kiến thức để xác định nguyên nhân và xác định giải pháp khắc phục là điều phân biệt các nhà khoa học dữ liệu chỉ vui mừng khi đưa được mô hình vào môi trường sản xuất, với những người biết cách xây dựng một mô hình có thể tạo ra tác động lâu dài.