
Mô hình AI tí hon: Khi khả năng suy nghĩ quan trọng hơn kích thước khổng lồ
Trong suốt thập kỷ qua, ngành AI luôn tin rằng trí tuệ chỉ xuất hiện ở quy mô lớn. Tuy nhiên, mô hình Tiny Recursion Model (TRM) mới đây đã chứng minh điều ngược lại: một mạng nơ-ron nhỏ bé chỉ với 7 triệu tham số có thể vượt qua các "gã khổng lồ" như GPT-4 hay DeepSeek nhờ khả năng suy nghĩ lặp đi lặp lại và tự sửa lỗi.

Trong suốt thập kỷ qua, toàn bộ ngành công nghiệp AI đã luôn tin vào một quy ước ngầm rằng: trí tuệ chỉ có thể xuất hiện ở quy mô lớn. Chúng ta thuyết phục bản thân rằng để các mô hình thực sự bắt chước được lập luận của con người, chúng ta cần những mạng lưới neural lớn hơn và sâu hơn. Không ngạc nhiên khi điều này dẫn đến việc chồng chất các khối transformer lên nhau, thêm hàng tỷ tham số và đào tạo chúng trên các trung tâm dữ liệu tiêu tốn hàng megawatt điện năng.
Nhưng cuộc đua để tạo ra những mô hình ngày càng lớn hơn có đang làm mờ mắt chúng ta trước một con đường hiệu quả hơn nhiều không? E rằng trí tuệ thực sự không liên quan đến kích thước của mô hình, mà nằm ở việc bạn cho nó suy nghĩ trong bao lâu. Một mạng nơ-ron tí hon, nếu được tự do lặp lại giải pháp của chính nó, có thể đánh bại một mô hình lớn hơn hàng nghìn lần không?
Sự mong manh của những người khổng lồ
Để hiểu tại sao chúng ta cần một cách tiếp cận mới, trước hết hãy nhìn vào lý do khiến các mô hình lập luận hiện tại như GPT-4, Claude và DeepSeek vẫn gặp khó khăn với các logic phức tạp.
Các mô hình này chủ yếu được đào tạo với mục tiêu Dự đoán Token tiếp theo (Next-Token-Prediction - NTP). Chúng xử lý câu lệnh thông qua các tầng tham số tỷ đô để dự đoán token tiếp theo trong một chuỗi. Ngay cả khi chúng sử dụng kỹ thuật "Chuỗi suy nghĩ" (Chain-of-Thought - CoT) để "lập luận" về một vấn đề, thực chất chúng vẫn chỉ đang dự đoán một từ ngữ, mà đáng buồn là hành động đó không phải là suy nghĩ.
Cách tiếp cận này có hai khiếm khuyết lớn.
Thứ nhất, nó rất mong manh. Vì mô hình tạo ra câu trả lời từng token một, một sai lầm đơn giản ở giai đoạn đầu của quá trình suy luận có thể gây ra hiệu ứng tuyết lở, dẫn đến một câu trả lời hoàn toàn khác và thường là sai. Mô hình thiếu khả năng dừng lại, quay ngược lại và sửa logic nội bộ của mình trước khi trả lời. Nó buộc phải cam kết hoàn toàn với con đường mà nó đã bắt đầu, thường xuyên "ảo giác" một cách tự tin chỉ để hoàn thành câu văn.
Thứ hai, các mô hình lập luận hiện đại dựa vào việc ghi nhớ hơn là suy luận logic. Chúng hoạt động tốt trên các nhiệm vụ chưa từng thấy vì có khả năng cao là chúng đã gặp một vấn đề tương tự trong dữ liệu đào tạo khổng lồ. Nhưng khi đối mặt với một vấn đề hoàn toàn mới—một thứ mà mô hình chưa từng thấy (như chuẩn mực ARC-AGI)—số lượng tham số khổng lồ của chúng trở nên vô dụng. Điều này cho thấy các mô hình hiện tại chỉ có thể thích nghi một giải pháp đã biết, thay vì xây dựng một giải pháp từ đầu.
Tiny Recursive Models: Đổi không gian lấy thời gian
Tiny Recursion Model (TRM) phá vỡ quá trình suy luận thành một quy trình nhỏ gọn và tuần hoàn. Các mạng transformer truyền thống (hay còn gọi là các mô hình LLM của chúng ta) là kiến trúc tiến về phía trước (feed-forward), nơi chúng phải xử lý đầu vào để tạo ra đầu ra trong một lần duy nhất. Ngược lại, TRM hoạt động giống như một máy đệ quy với một mô-đun MLP duy nhất nhỏ gọn, có thể cải thiện đầu ra của nó theo cách lặp đi lặp lại. Điều này cho phép nó đánh bại các mô hình lập luận chủ đạo tốt nhất hiện nay, trong khi kích thước của nó chưa đến 7 triệu tham số.
Để hiểu cách mạng lưới này giải quyết vấn đề hiệu quả đến vậy, hãy cùng đi qua kiến trúc từ đầu vào đến giải pháp.
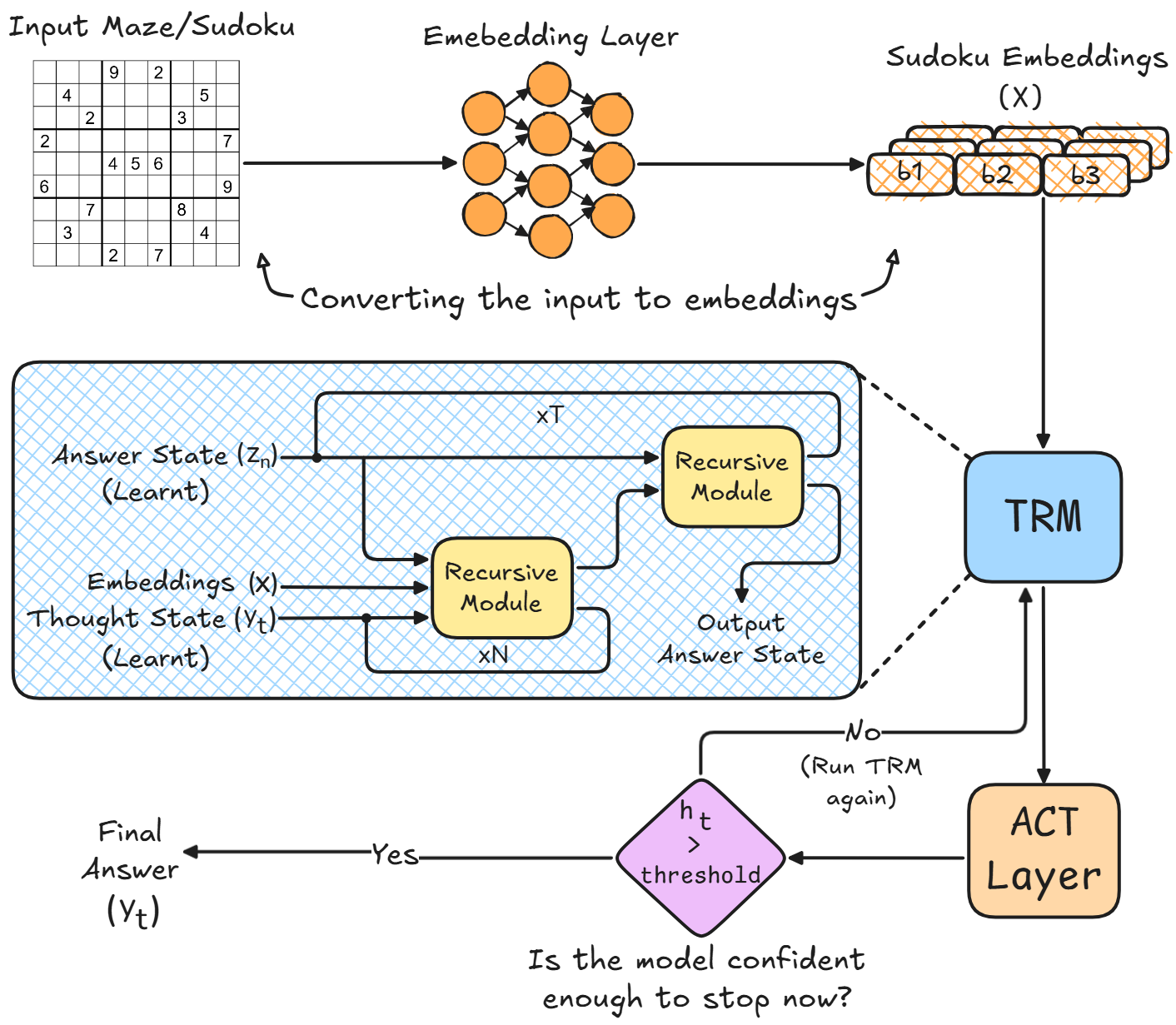 Minh họa kiến trúc TRM
Minh họa kiến trúc TRM
Cấu trúc: "Bộ ba" của Trạng thái
Trong các LLM tiêu chuẩn, "trạng thái" duy nhất là bộ nhớ đệm KV của lịch sử hội thoại. Trong khi đó, TRM duy trì ba vector thông tin riêng biệt cung cấp thông tin cho nhau:
- Câu hỏi bất biến (x): Vấn đề gốc (ví dụ: một Mê cung hoặc lưới Sudoku), được nhúng vào không gian vector. Trong suốt quá trình đào tạo/suy luận, điều này không bao giờ được cập nhật.
- Giả thuyết hiện tại (yt): "Đoán tốt nhất" hiện tại của mô hình về câu trả lời. Tại bước t=0, điều này được khởi tạo ngẫu nhiên dưới dạng một tham số có thể học được và được cập nhật cùng với chính mô hình.
- Suy luận tiềm ẩn (zn): Vector này chứa các "suy nghĩ" trừu tượng hoặc logic trung gian mà mô hình sử dụng để đưa ra câu trả lời. Tương tự như yt, điều này cũng được khởi tạo dưới dạng một tham số ngẫu nhiên ở đầu.
Động cơ cốt lõi: Vòng lặp Mạng đơn nhất
Trái tim của TRM là một mạng nơ-ron duy nhất, nhỏ gọn, thường chỉ sâu hai tầng. Mạng lưới này không phải là một "lớp mô hình" theo nghĩa truyền thống, mà giống như một hàm được gọi đi gọi lại nhiều lần.
Quá trình suy luận bao gồm một vòng lặp lồng nhau gồm hai giai đoạn riêng biệt: Suy luận Tiềm ẩn và Tinh chỉnh Câu trả lời.
Bước A: Suy luận Tiềm ẩn (Cập nhật zn)
Đầu tiên, mô hình chỉ được nhiệm vụ suy nghĩ. Nó lấy trạng thái hiện tại (ba vector được mô tả trên) và chạy một vòng lặp đệ quy để cập nhật sự hiểu biết nội bộ của nó về vấn đề. Trong một số bước con nhất định (n), mạng cập nhật vector suy nghĩ tiềm ẩn zn của nó:
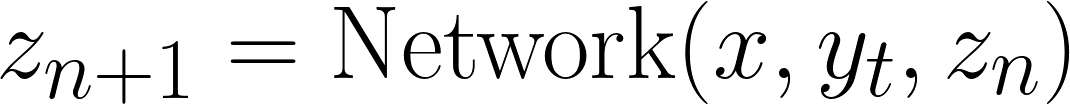 Công thức cập nhật suy nghĩ tiềm ẩn
Công thức cập nhật suy nghĩ tiềm ẩn
Tại đây, mạng nhìn vào vấn đề (x), đoán tốt nhất hiện tại của nó (yt), và suy nghĩ trước đó của nó (zn). Với điều này, mô hình có thể xác định các mâu thuẫn hoặc bước nhảy logic trong sự hiểu biết của nó, từ đó sử dụng để cập nhật zn. Lưu ý rằng câu trả lời yt chưa được cập nhật. Mô hình đang hoàn toàn suy nghĩ/lập luận về vấn đề.
Bước B: Tinh chỉnh Câu trả lời (Cập nhật yt)
Khi vòng lặp suy luận tiềm ẩn hoàn tất lên đến n bước, mô hình sau đó cố gắng chiếu những hiểu biết này vào trạng thái câu trả lời của nó. Nó sử dụng cùng một mạng để thực hiện phép chiếu này:
Mô hình chuyển đổi quá trình suy luận (zn) của nó thành một dự đoán hữu hình (yt). Câu trả lời mới này sau đó trở thành đầu vào cho chu kỳ suy luận tiếp theo, chu kỳ này lại tiếp tục trong tổng số T bước.
Bước C: Vòng lặp tiếp tục
Sau mỗi n bước tinh chỉnh suy nghĩ, một bước tinh chỉnh câu trả lời sẽ chạy (lần lượt phải được gọi T lần). Điều này tạo ra một vòng lặp phản hồi mạnh mẽ nơi mô hình có thể tinh chỉnh đầu ra của chính mình qua nhiều lần lặp. Câu trả lời mới (yt+1) có thể tiết lộ một số thông tin mới bị bỏ lỡ bởi tất cả các bước trước đó (ví dụ: "điền ô Sudoku này cho thấy số 5 phải nằm ở đây"). Mô hình lấy câu trả lời này, đưa trở lại Bước A và tiếp tục tinh chỉnh suy nghĩ cho đến khi nó điền được toàn bộ lưới sudoku.
Nút "Thoát": Thời gian tính toán thích ứng
Một đổi mới lớn khác của cách tiếp cận TRM nằm ở cách nó xử lý toàn bộ quá trình suy luận một cách hiệu quả. Một vấn đề đơn giản có thể được giải chỉ trong hai vòng lặp, trong khi một vấn đề khó có thể yêu cầu 50 vòng hoặc hơn. Điều này có nghĩa là việc mã hóa cứng một số lượng vòng lặp cố định là hạn chế và do đó không lý tưởng. Mô hình cần có khả năng quyết định xem nó đã giải quyết xong vấn đề hay vẫn cần nhiều lần lặp hơn để suy nghĩ.
TRM sử dụng Thời gian tính toán thích ứng (Adaptive Computation Time - ACT) để quyết định động khi nào nên dừng, dựa trên độ khó của vấn đề đầu vào.
TRM coi việc dừng lại như một vấn đề phân loại nhị phân đơn giản, dựa trên mức độ tự tin của mô hình về câu trả lời hiện tại của chính nó.
Xác suất dừng (h):
Ở cuối mỗi bước tinh chỉnh câu trả lời T, mô hình chiếu trạng thái câu trả lời nội bộ của nó thành một giá trị vô hướng duy nhất giữa 0 và 1, nhằm đại diện cho sự tự tin của mô hình:
ht: Xác suất dừng. σ: Hàm kích hoạt Sigmoid để giới hạn đầu ra giữa 0 và 1. Linear: Phép biến đổi tuyến tính thực hiện trên vector câu trả lời.
Mục tiêu đào tạo:
Mô hình được đào tạo với hàm mất mát Binary Cross-Entropy (BCE). Nó học cách xuất ra 1 (dừng) khi câu trả lời hiện tại yt khớp với thực tế, và 0 (tiếp tục) nếu không.
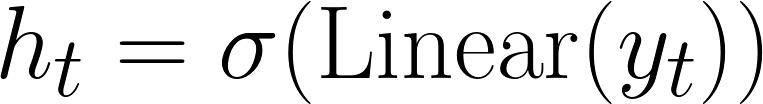 Hàm mất mát trong quá trình đào tạo
Hàm mất mát trong quá trình đào tạo
Suy luận:
Khi mô hình chạy trên một vấn đề mới, nó kiểm tra xác suất ht này sau mỗi vòng lặp.
Nếu ht > ngưỡng: Mô hình đủ tự tin. Nó nhấn "Nút Thoát" và trả về câu trả lời hiện tại yt làm câu trả lời cuối cùng. Nếu ht < ngưỡng: Mô hình vẫn chưa chắc chắn. Nó đưa yt và zn trở lại vòng lặp TRM để cân nhắc và tinh chỉnh thêm.
Cơ chế này cho phép TRM hiệu quả về mặt tính toán. Nó đạt độ chính xác cao không phải vì to lớn, mà vì sự kiên trì—phân bổ ngân sách tính toán chính xác nơi nó cần thiết.
Kết quả gây sốc
Để thực sự kiểm tra giới hạn của TRM, nó đã được chạy thử nghiệm trên một số bộ dữ liệu logic khó nhất hiện có, như thử thách Sudoku và ARC-AGI.
Thử thách Sudoku-Extreme
Bài kiểm tra đầu tiên là trên chuẩn mực Sudoku-Extreme, một tập dữ liệu gồm các câu đố Sudoku khó được tuyển chọn đặc biệt yêu cầu suy luận logic sâu và khả năng quay lại các bước mà mô hình sau này nhận ra là sai.
Kết quả hoàn toàn trái ngược với quy ước thông thường. TRM, với chỉ 5 triệu tham số, đã đạt độ chính xác 87,4% trên tập dữ liệu này.
Để bạn dễ hình dung:
- Các LLM lập luận tiêu chuẩn hiện nay như Claude 3.7, GPT o3-mini và DeepSeek R1 không thể hoàn thành bất kỳ câu đố Sudoku nào từ toàn bộ tập dữ liệu, dẫn đến độ chính xác 0% trên toàn bộ.
- Mô hình đệ quy tiên phong trước đó (HRM) sử dụng 27 triệu tham số (lớn hơn hơn 5 lần) và đạt độ chính xác 55,0%.
Bằng cách đơn giản là loại bỏ kiến trúc phân cấp phức tạp của HRM và tập trung vào một vòng lặp đệ quy duy nhất, TRM đã cải thiện độ chính xác hơn 30 điểm phần trăm đồng thời giảm số lượng tham số.
"Bẫy Dung lượng": Tại sao sâu hơn lại tệ hơn
Có lẽ một sự thật ngược đời nhất mà các tác giả tìm thấy trong cách tiếp cận của họ là điều gì xảy ra khi họ cố gắng làm cho TRM "tốt hơn" bằng cách nhân đôi số lượng tham số.
Khi họ tăng độ sâu mạng từ 2 lớp lên 4 lớp, hiệu suất không tăng lên; thay vào đó, nó bị sụt giảm nghiêm trọng.
- TRM 2 lớp: 87,4% độ chính xác trên Sudoku.
- TRM 4 lớp: 79,5% độ chính xác trên Sudoku.
Trong thế giới của LLM, thêm nhiều lớp và làm cho mô hình sâu hơn luôn là cách mặc định để tăng trí thông minh. Nhưng đối với lập luận đệ quy trên các tập dữ liệu nhỏ (TRM chỉ được đào tạo trên ~1.000 ví dụ), các lớp bổ sung có thể trở thành một gánh nặng vì chúng cho phép mô hình quá nhiều dung lượng để ghi nhớ các mẫu thay vì suy luận chúng, dẫn đến quá khớp (overfitting).
Điều này xác nhận giả thuyết cốt lõi của bài báo: chiều sâu trong thời gian đánh bại chiều sâu trong không gian. Việc có một mô hình nhỏ hơn suy nghĩ trong một thời gian dài có thể hiệu quả hơn nhiều so với việc có một mô hình lớn hơn suy nghĩ trong một thời gian ngắn. Mô hình không cần nhiều dung lượng để ghi nhớ; nó chỉ cần nhiều thời gian và một phương tiện hiệu quả để suy luận.
Thử thách ARC-AGI: Sỉ nhục những người khổng lồ
Abstraction and Reasoning Corpus (ARC-AGI) được coi rộng rãi là một trong những chuẩn mực khó nhất để kiểm tra nhận dạng mẫu và lập luận logic trong các mô hình AI. Về bản chất, nó kiểm tra trí thông minh lỏng—khả năng học các quy tắc trừu tượng mới của một hệ thống chỉ từ một vài ví dụ. Đây là nơi hầu hết các LLM hiện đại thường thất bại.
Kết quả ở đây còn gây sốc hơn. TRM, được đào tạo với chỉ 7 triệu tham số, đã đạt độ chính xác 44,6% trên ARC-AGI-1.
Hãy so sánh với những gã khổng lồ trong ngành:
- DeepSeek R1 (671 Tỷ tham số): 15,8% độ chính xác.
- Claude 3.7 (Không xác định, có lẽ hàng trăm tỷ): 28,6% độ chính xác.
- Gemini 2.5 Pro: 37,0% độ chính xác.
Một mô hình chỉ lớn bằng 0,001% kích thước của DeepSeek R1 đã vượt qua nó gần gấp 3 lần. Đây có lẽ là hiệu suất hiệu quả nhất từng được ghi nhận trên chuẩn mực này. Chỉ có mô hình Grok-4 với 1,7 nghìn tỷ tham số mới cho thấy hiệu suất vượt qua các cách tiếp cận lập luận đệ quy của HRM và TRM.
Kết luận
Trong nhiều năm, chúng ta đã đo lường sự tiến bộ của AI bằng số lượng số 0 phía sau số lượng tham số. Tiny Recursion Model mang đến một sự thay thế cho quy ước này. Nó chứng minh rằng một mô hình không cần phải khổng lồ để thông minh; nó chỉ cần thời gian để suy nghĩ hiệu quả.
Khi chúng ta hướng tới AGI (Trí tuệ nhân tạo tổng quát), câu trả lời có thể không nằm ở việc xây dựng các trung tâm dữ liệu lớn hơn để kết hợp các mô hình nghìn tỷ tham số. Thay vào đó, nó có thể nằm ở việc xây dựng các mô hình logic nhỏ gọn, hiệu quả có thể cân nhắc một vấn đề trong bao lâu tùy thích—bắt chước chính hành động con người của việc dừng lại, suy nghĩ và giải quyết.
Bài viết liên quan

Phần cứng
Gemma 4 áp dụng Multi-Token Prediction, tăng tốc độ suy luận lên tới 3 lần
25 tháng 5, 2026

Công nghệ
Các tác nhân AI đã khiến thế giới công nghệ chao đảo: Câu chuyện đằng sau cuộc cách mạng Claude Code và OpenClaw
26 tháng 5, 2026

Phần cứng
Nvidia chính thức đưa siêu vi xử lý Grace Blackwell lên PC với dòng notebook RTX Spark
01 tháng 6, 2026