
Mô hình Dữ liệu cho Kỹ sư Phân tích: Cẩm nang Toàn diện từ A đến Z
Bài viết cung cấp cái nhìn sâu sắc về các nguyên tắc cốt lõi của mô hình dữ liệu (data modeling) dành cho kỹ sư phân tích hiện đại. Từ việc phân biệt hệ thống OLTP và OLAP, quy trình chuyển đổi từ dữ liệu chuẩn hóa sang phi chuẩn hóa, đến các kỹ thuật nâng cao như lược đồ sao và quản lý chiều thay đổi chậm (SCD). Đây là nền tảng thiết yếu để xây dựng kho dữ liệu mạnh mẽ, hiệu quả và hỗ trợ đắc lực cho việc ra quyết định kinh doanh.

Mô hình dữ liệu của bạn không chỉ đơn thuần là các thông số kỹ thuật khô khan. Bản chất của nó là tư duy như một doanh nghiệp. Hãy coi nó như bản thiết kế (blueprint) cho cả ngôi nhà phân tích dữ liệu của bạn. Nếu bản thiết kế lộn xộn, ngôi nhà sẽ sụp đổ. Nếu nó có cấu trúc và tổ chức tốt, đội ngũ của bạn sẽ nhanh chóng tìm ra những thông tin chi tiết quý giá.
Bạn đang nhìn chằm chằm vào một bảng tính đầy rẫy đơn đặt hàng của khách hàng, giá sản phẩm và ngày bán. Nó lộn xộn. "Bảng điều khiển" (dashboard) của bạn chậm chạp. Bạn đã cố gắng trả lời một câu hỏi đơn giản như: Lợi nhuận từ việc bán bánh pizza trong quý vừa rồi là bao nhiêu? nhưng lại nhận được những con số không khớp nhau. Tại sao? Bởi vì mô hình dữ liệu của bạn đang thực sự hỗn loạn.
Trong bài viết này, chúng ta sẽ cùng nhau đi qua các khái niệm cốt lõi về mô hình dữ liệu mà mọi kỹ sư phân tích (analytics engineer) cần phải biết. Hãy tạm quên Power BI hay Microsoft Fabric đi. Đây là về các nguyên tắc nền tảng — lý do tại sao đằng sau các mô hình. Những ý tưởng này hoạt động bất kể bạn sử dụng công cụ nào.
Ba cấp độ của Mô hình Dữ liệu
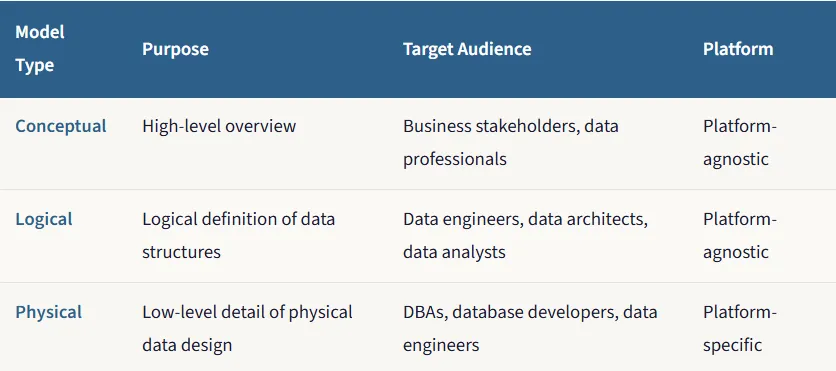
Tương tự như một kiến trúc sư không thể đi thẳng từ một ý tưởng sang một tòa nhà hoàn chỉnh, người mô hình hóa dữ liệu cũng không thể tạo ra lược đồ cơ sở dữ liệu chỉ trong một bước. Quá trình này phát triển qua ba cấp độ chi tiết tăng dần, mỗi cấp độ phục vụ một mục đích và đối tượng riêng biệt.
 Ba cấp độ mô hình dữ liệu từ khái niệm đến vật lý
Ba cấp độ mô hình dữ liệu từ khái niệm đến vật lý
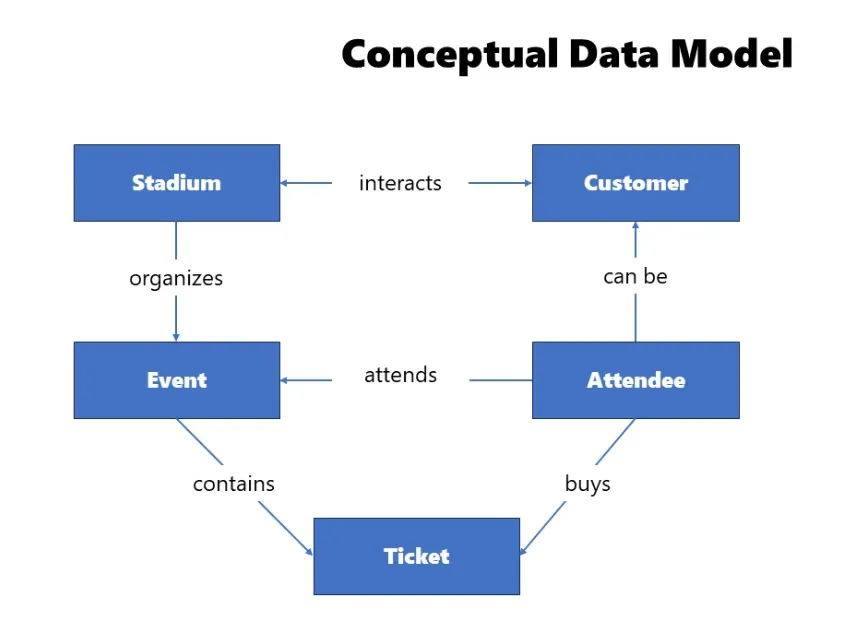
1. Mô hình khái niệm (Conceptual Model): Phác thảo trên khăn giấy
Mọi mô hình dữ liệu tuyệt vời đều bắt đầu không phải bằng mã hay bảng, mà bằng một cuộc trò chuyện. Mô hình khái niệm là cái nhìn đầu tiên, cấp độ cao nhất về dữ liệu của bạn. Nó hoàn toàn phi kỹ thuật và tập trung duy nhất vào việc hiểu và định nghĩa các khái niệm kinh doanh cũng như các quy tắc chi phối chúng.
Hãy tưởng tượng một kiến trúc sư gặp khách hàng tại một quán cà phê. Khách hàng nói: "Tôi muốn một ngôi nhà cảm thấy mở và kết nối với nhau". Kiến trúc sư lấy một chiếc khăn giấy và vẽ một vài bong bóng: Bếp, Phòng khách, Phòng ngủ, và vẽ các đường kẻ nối giữa chúng được gắn nhãn "kết nối với" hay "tách biệt với". Đó không có kích thước, vật liệu hay chi tiết kỹ thuật. Đó chỉ là về việc nắm bắt ý tưởng cốt lõi. Bản phác thảo trên khăn giấy đó chính là mô hình dữ liệu khái niệm.
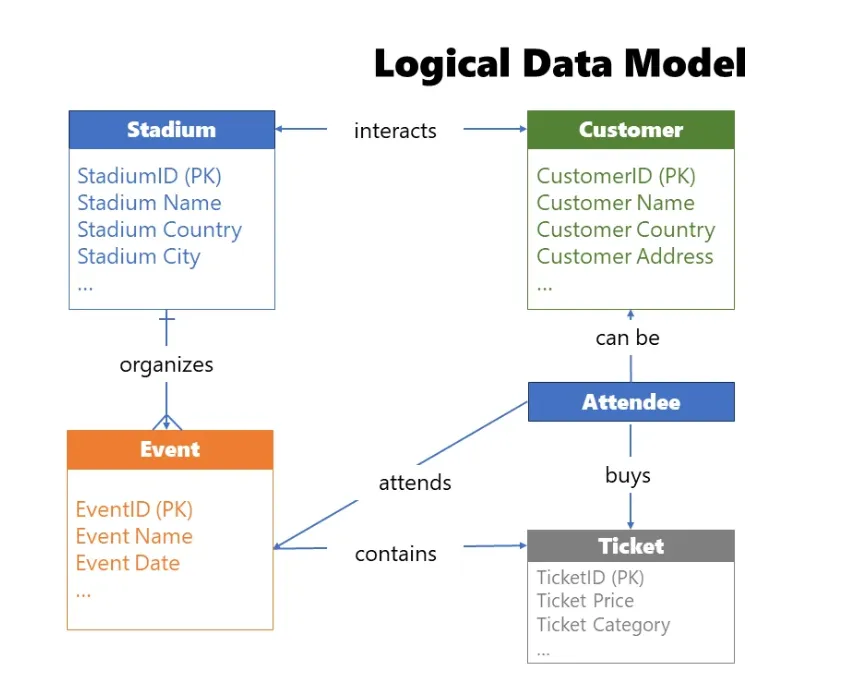
2. Mô hình logic (Logical Model): Bản thiết kế chi tiết
Sau khi các đội ngũ kinh doanh và dữ liệu thống nhất với mô hình khái niệm, bước tiếp theo là thiết kế mô hình dữ liệu logic. Ở giai đoạn này, chúng ta xây dựng dựa trên bước trước bằng cách xác định cấu trúc chính xác của các thực thể và cung cấp thêm chi tiết về mối quan hệ giữa chúng.
Mô hình logic đóng vai trò như bài kiểm tra đảm bảo chất lượng tốt nhất, giúp xác định các khoảng trống và vấn đề trong việc hiểu quy trình công việc kinh doanh, từ đó tiết kiệm đáng kể thời gian và công sức về lâu dài. Việc xây dựng mô hình dữ liệu logic được coi là một phần của chu trình mô hình hóa dữ liệu linh hoạt (agile), đảm bảo các mô hình chắc chắn, có khả năng mở rộng và tương lai.
3. Mô hình vật lý (Physical Model): Kế hoạch xây dựng
Mô hình dữ liệu vật lý đại diện cho nét chạm cuối cùng: mô hình dữ liệu sẽ thực sự được triển khai trong một cơ sở dữ liệu cụ thể như thế nào. Khác với mô hình khái niệm và logic, việc triển khai vật lý yêu cầu xác định các chi tiết cấp thấp có thể cụ thể cho một nhà cung cấp cơ sở dữ liệu nhất định.
Ở bước này, bạn phải chọn nền tảng, dịch chuyển các thực thể logic thành các bảng vật lý với các kiểu dữ liệu cụ thể, thiết lập các khóa, các ràng buộc và tạo ra các chỉ mục (indexes) hoặc phân vùng (partitions) để tăng hiệu quả. Lợi ích chính của mô hình dữ liệu vật lý là đảm bảo hiệu quả, hiệu suất tối ưu và khả năng mở rộng. Mô hình càng hiệu quả thì càng phục vụ được nhiều người dùng nhanh hơn, mang lại nhiều giá trị hơn cho doanh nghiệp.
OLTP so với OLAP: Ghi dữ liệu hay Đọc dữ liệu?
Hệ thống OLTP (Xử lý giao dịch trực tuyến)
Để thành công trong vai trò kỹ sư phân tích, bạn trước hết phải hiểu dữ liệu của mình đến từ đâu. Đa số dữ liệu kinh doanh không được tạo ra cho mục đích phân tích. Nó được tạo ra bởi các ứng dụng chạy các hoạt động hàng ngày của doanh nghiệp: hệ thống POS, công cụ CRM, backend của website thương mại điện tử...
Các hệ thống nguồn này được gọi là hệ thống xử lý giao dịch trực tuyến (OLTP). Chúng được thiết kế và tối ưu hóa cho một mục tiêu chính: xử lý khối lượng giao dịch lớn một cách nhanh chóng và đáng tin cậy. Để đạt được điều này, các hệ thống OLTP sử dụng mô hình dữ liệu quan hệ được chuẩn hóa (normalized) cao độ.
Chuẩn hóa (Normalization) là quá trình tổ chức dữ liệu để giảm thiểu dư thừa và cải thiện tính toàn vẹn. Nói một cách đơn giản, đừng lặp lại thông tin nếu không cần thiết. Ví dụ, thay vì lưu địa chỉ của khách hàng John Smith trong mọi dòng đơn hàng, bạn chỉ lưu ID của John Smith và để địa chỉ nằm trong một bảng riêng biệt. Nếu John chuyển nhà, bạn chỉ cần cập nhật một nơi duy nhất.
Tuy nhiên, cấu trúc được chuẩn hóa này tuy tuyệt vời để ghi dữ liệu lại kém hiệu quả khi phân tích nó. Để trả lời một câu hỏi như "Tổng doanh số bán sản phẩm danh mục 'Widgets' cho khách hàng ở New York là bao nhiêu?", bạn sẽ phải thực hiện nhiều thao tác JOIN phức tạp. Với hàng chục hoặc hàng trăm bảng, các truy vấn này trở nên cực kỳ chậm.
 Chuyển đổi dữ liệu từ mô hình tối ưu ghi sang mô hình tối ưu đọc
Chuyển đổi dữ liệu từ mô hình tối ưu ghi sang mô hình tối ưu đọc
Hệ thống OLAP (Xử lý phân tích trực tuyến)
Nếu OLTP dành cho vận hành doanh nghiệp, thì OLAP dành cho hiểu doanh nghiệp. Mục tiêu chính của chúng ta là xây dựng các hệ thống OLAP. Chúng được thiết kế để trả lời các câu hỏi kinh doanh phức tạp trên khối lượng dữ liệu lớn nhanh nhất có thể.
Ở đây chúng ta sử dụng Phi chuẩn hóa (Denormalization): Đây là việc đảo ngược có chủ đích quá trình chuẩn hóa. Chúng ta cố ý kết hợp lại nhiều bảng nhỏ thành một vài bảng lớn hơn, rộng hơn, ngay cả khi điều đó có nghĩa là lặp lại một chút dữ liệu. Đây là sự đánh đổi: hy sinh một chút không gian lưu trữ để có được lợi ích khổng lồ về hiệu suất truy vấn.
Mô hình hóa Chiều (Dimensional Modeling): Lược đồ Sao và xa hơn nữa
Mô hình chiều đại diện cho phương thức tiêu chuẩn vàng khi thiết kế các hệ thống OLAP. Phương pháp tiếp cận của Ralph Kimball, cha đẻ của khái niệm này, rất elegants trong sự đơn giản. Nó chia dữ liệu thành hai loại bảng chính:
- Dimensions (Các bảng chiều): Trả lời các câu hỏi W. Bảng chiều giống như bảng tra cứu, cung cấp thông tin mô tả về đối tượng. Khi chúng ta bán vé? Ở đâu? Loại nào? Ai là khách hàng?
- Facts (Các bảng sự kiện): Lưu trữ dữ liệu về các sự kiện — những thứ xảy ra do quá trình kinh doanh. Thường được biểu thị bằng các giá trị số: Bao nhiêu vé đã bán? Bao nhiêu doanh thu?
Lược đồ Sao (Star Schema) và Lược đồ Bông tuyết (Snowflake Schema)
Trong Lược đồ Sao, bạn có một bảng sự kiện trung tâm chứa tất cả các phép đo và sự kiện, được bao quanh bởi các bảng chiều. Bảng sự kiện và các bảng chiều được nối với nhau thông qua các mối quan hệ. Sự sắp xếp này trông giống như một ngôi sao — do đó có tên gọi này.
Mặc dù có nhiều cuộc tranh luận về sự phù hợp của lược đồ sao trong các giải pháp nền tảng dữ liệu hiện đại, nó vẫn là phương pháp được áp dụng rộng rãi nhất khi thiết kế các hệ thống thông minh kinh doanh hiệu quả.
Lược đồ Bông tuyết tương tự, nhưng các chiều được chuẩn hóa và chia nhỏ thành các chiều con. Mặc dù điều này giúp giảm dư thừa dữ liệu, nó làm cho cấu trúc mô hình phức tạp hơn và hiệu suất có thể bị ảnh hưởng do các thao tác JOIN giữa các bảng chiều.
Lược đồ sao nên là lựa chọn mặc định — lược đồ bông tuyết là ngoại lệ.
Quản lý Chiều thay đổi chậm (Slowly Changing Dimensions - SCD)
Bạn biết câu nói "Điều duy nhất không đổi trong cuộc sống là sự thay đổi"? Điều đó cũng đúng với dữ liệu của bạn. Khách hàng chuyển nhà, sản phẩm đổi tên, nhân viên được thăng chức. Nếu chúng ta chỉ đơn giản là ghi đè các bản ghi cũ, chúng ta sẽ mất lịch sử. Đây là nơi Chiều thay đổi chậm (SCD) phát huy tác dụng.
SCD Loại 1: Ghi đè "hay quên"
Đây là cách dễ nhất để thực hiện. Khi một thuộc tính thay đổi (như địa chỉ email), bạn chỉ cần ghi đè giá trị cũ bằng giá trị mới. Thay đổi là tức thì và không thể đảo ngược. Nếu doanh nghiệp không quan tâm đến lịch sử của một thuộc tính (như số điện thoại chính), Loại 1 là giải pháp sạch sẽ và đơn giản.
SCD Loại 2: Tiêu chuẩn vàng - Du hành thời gian
Loại 2 là phương pháp phổ biến nhất cho bất cứ điều gì doanh nghiệp cần để phân tích dữ liệu lịch sử. Khi một thuộc tính thay đổi, bạn không bao giờ cập nhật bản ghi cũ. Thay vào đó, bạn tạo một bản ghi mới để giữ phiên bản mới của chiều. Đây là cách bạn đạt được "du hành thời gian" trong các báo cáo của mình.
Mỗi lần một thuộc tính chính thay đổi, một dòng mới được sinh ra. Điều này giữ nguyên tất cả các phiên bản trước đó của bản ghi, mỗi phiên bản hợp lệ cho một khoảng thời gian cụ thể. SCD Loại 2 là "nước sốt bí mật" cho các báo cáo lịch sử đáng tin cậy, cho phép các nhà phân tích biết chính xác mọi thứ diễn ra như thế nào vào quá khứ.
 Các loại bảng sự kiện và cách lựa chọn phù hợp
Các loại bảng sự kiện và cách lựa chọn phù hợp
Các loại Bảng sự kiện (Fact Tables)
Không phải mọi phép đo đều được tạo ra như nhau. Chúng ta có bốn loại bảng sự kiện chính, mỗi loại được thiết kế cho một loại phép đo kinh doanh cụ thể:
- Bảng sự kiện giao dịch (Transactional Fact Table): Ghi lại một sự kiện tức thì. Mỗi dòng là khoảnh khắc duy nhất (một lần nhấp chuột, một mục đơn hàng). Các phép đo có thể cộng gộp hoàn toàn (fully additive).
- Bảng sự kiện chụp nhanh định kỳ (Periodic Snapshot Fact Table): Chụp nhanh trạng thái của nhiều thứ tại một thời điểm định kỳ (cuối tháng, cuối tuần). Các phép đo thường là bán cộng gộp (semi-additive); bạn có thể cộng chúng qua hầu hết các chiều nhưng không thể cộng qua thời gian (ví dụ: tồn kho kho hàng).
- Bảng sự kiện tích lũy (Accumulating Snapshot Fact Table): Theo dõi tiến trình của một quy trình nhiều bước từ đầu đến cuối (ví dụ: vận chuyển gói hàng). Một dòng được tạo ra khi quy trình bắt đầu và được cập nhật khi nó đi qua các cột mốc quan trọng.
- Bảng sự kiện không có số liệu (Factless Fact Table): Không có các phép đo số học. Nhiệm vụ duy nhất của nó là bắt lấy mối quan hệ giữa các chiều (ví dụ: danh sách sinh viên tham dự các lớp học bắt buộc).
Tổng kết
Chúng ta đã đi qua một hành trình dài, từ bản phác thảo khái niệm đến kế hoạch vật lý, từ việc hiểu sự khác biệt giữa ghi và đọc dữ liệu, đến các kỹ thuật mô hình hóa chiều tinh vi. Mô hình dữ liệu không chỉ là kỹ thuật, đó là cầu nối giữa ngôn ngữ công nghệ và tư duy kinh doanh. Nắm vững các nguyên tắc này sẽ giúp bạn xây dựng những hệ thống dữ liệu không chỉ chạy nhanh mà còn trả lời đúng những câu hỏi quan trọng nhất của doanh nghiệp.
Bài viết liên quan

Công nghệ
Các tác nhân AI đã khiến thế giới công nghệ chao đảo: Câu chuyện đằng sau cuộc cách mạng Claude Code và OpenClaw
26 tháng 5, 2026

Công nghệ
Threads cán mốc 500 triệu người dùng hoạt động hàng tháng
16 tháng 6, 2026

Công nghệ
Alienware 15 mới: Dell đang làm loãng thương hiệu cao cấp vì khủng hoảng RAM?
14 tháng 5, 2026