
Mô hình Hy3 bí ẩn đang dẫn đầu bảng xếp hạng OpenRouter vượt xa các đối thủ
Mô hình Hy3 từ Tencent đã bất ngờ chiếm ngôi đầu bảng về lượng sử dụng token trên nền tảng OpenRouter, vượt qua cả các "gã khổng lồ" như Claude và DeepSeek. Bài viết phân tích nguyên nhân đằng sau sự phổ biến này, từ giá cả, hiệu suất cho đến chiến lược caching độc đáo của các nhà cung cấp.
OpenRouter là dịch vụ cung cấp quyền truy cập vào hầu hết các mô hình ngôn ngữ lớn (LLM) thông qua một API duy nhất, trở nên vô cùng hữu ích trong bối cảnh các LLM mới được ra mắt liên tục gần đây. Nhờ vai trò trung gian giữa người dùng và các API của LLM, OpenRouter sở hữu dữ liệu đại diện mạnh mẽ về cách người dùng tương tác với các mô hình này và công bố dữ liệu đó trên trang Bảng xếp hạng Mô hình AI. Đây là một điểm khác biệt thú vị so với các phòng lab phát triển LLM, nơi họ thường giữ bí mật dữ liệu này vì lý do cạnh tranh.
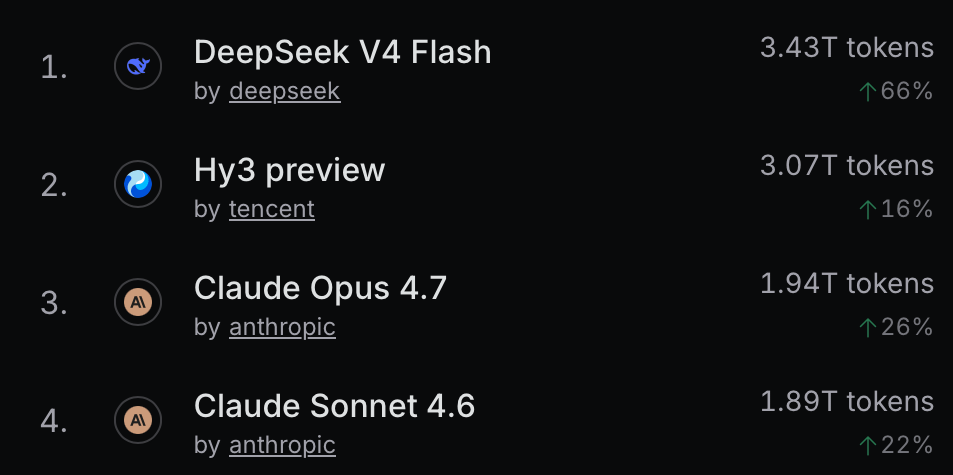
Gần đây, khi kiểm tra bảng xếp hạng của OpenRouter, tôi đã nhận thấy một điều kỳ lạ. Hai mô hình mới hiện đang vượt mặt "ngôi sao" Claude về lượng sử dụng token với biên độ hơn 50%.
 Bảng xếp hạng các mô hình AI trên OpenRouter tính đến ngày 25/5/2026
Bảng xếp hạng các mô hình AI trên OpenRouter tính đến ngày 25/5/2026
Tôi đã nghe nói về DeepSeek Flash V4: đây là bản phát hành mã nguồn mở từ DeepSeek không chỉ nhanh và rẻ mà còn có hiệu suất gần với các mô hình LLM hàng đầu với chi phí rất thấp, nên sự phổ biến của nó không có gì ngạc nhiên. Nhưng Hy3 preview là cái quái gì vậy? Tôi chưa từng nghe nói về Hy3 hay bất kỳ ai thảo luận về nó.
Google tìm kiếm chỉ trả về một thông báo từ tập đoàn khổng lồ Trung Quốc Tencent về việc phát hành mã nguồn mở của Hy3. Trang mô hình của nó trên Hugging Face khá sơ sài và bao gồm các kết quả benchmark một cách kỳ lạ là không thuận lợi cho mô hình này so với các mô hình mã nguồn mở Trung Quốc khác.
Một tìm kiếm trên Hacker News về Hy3 chỉ trả về một bài duy nhất không thực sự nói về Hy3, trong khi các thảo luận trên Reddit chủ yếu xoay quanh việc phát hành các trọng số (weights) mở. Một luồng thảo luận trên Reddit cũng lưu ý sự trỗi dậy của Hy3 nhưng từ ngày 6/5, khi Hy3 được OpenRouter cung cấp miễn phí; hiện tại endpoint miễn phí đó không còn nữa, và do đó lượng sử dụng Hy3 trong bảng xếp hạng hàng tuần ở trên là từ những người dùng trả phí.
Dữ liệu cho thấy Hy3 preview dường như cũng phổ biến trong các lĩnh vực khác ngoài lập trình tác tử (agentic coding).
 Lượng sử dụng token theo ngày của Hy3 preview
Lượng sử dụng token theo ngày của Hy3 preview
Vậy tôi đã bỏ lỡ điều gì? Sau một số thử nghiệm không mang tính khoa học, chất lượng mô hình thực sự ngang ngửa với các mô hình Trung Quốc khác được chỉ ra và không gần bằng các mô hình như Claude Opus 4.7 hay GPT 5.5. Nó không phải là một viên ngọc thô bị lãng quên có phép màu, nên chắc chắn phải có yếu tố nào khác đang tác động.
May mắn thay, OpenRouter có dữ liệu để thu hẹp các giải thích có thể, nhưng sau khi kiểm tra dữ liệu, tôi lại càng thêm bối rối.
Hy3 preview có sẵn từ API của OpenRouter với giá niêm yết là $0,066/1M token đầu vào, thực sự rẻ hơn mô hình hàng đầu hiện tại là DeepSeek V4 Flash với giá niêm yết là $0,10/1M token đầu vào. Cho chi phí LLM và các tác tử lập trình tăng vọt, việc một mô hình rẻ hơn chiến thắng là hợp lý, nhưng chỉ khi nó mang lại chất lượng tương đương, và trường hợp của Hy3 dường không phải như vậy.
Dưới đây là biểu đồ sử dụng mô hình Hy3 preview theo thời gian trên OpenRouter từ trang mô hình:
Hy3 preview không có dữ liệu sử dụng trước ngày 8/5, điều này ngụ ý rằng đó là thời điểm mô hình chuyển từ SKU miễn phí sang SKU trả phí. Kể từ đó, việc sử dụng cũng ổn định theo thời gian với các bảng xếp hạng ban đầu được hiển thị trong bài đăng này là vài tuần sau khi ra mắt, cho thấy việc sử dụng ít nhất là hữu cơ (hoặc rất tốn kém để giả mạo) và không phải là một trường hợp bất thường ngoại lệ. Đáng chú ý, nếu bạn làm toán với các con số được trình bày ở đây, tỷ lệ phân bổ token đầu vào/đầu ra trong các cuộc gọi API LLM hiện nay là 98% đầu vào và 2% đầu ra trên tổng thể.
Đối với Bảng xếp hạng Mô hình AI của OpenRouter, trước đây đã có những đột biến do các ứng dụng cụ thể chuyển mặc định sang một LLM nhất định, chẳng hạn như khi Kilo Code cung cấp Grok Code Fast 1 miễn phí vào tháng 9/2025, giúp nó vươn lên mức độ phổ biến. Tuy nhiên, trường hợp này dường không xảy ra ở đây vì các ứng dụng chỉ chiếm một phần rất nhỏ trong hoạt động của Hy3 preview.
 Các ứng dụng hàng đầu sử dụng Hy3
Các ứng dụng hàng đầu sử dụng Hy3
Giá trị cốt lõi của OpenRouter là khả năng định tuyến tự động một yêu cầu API nhất định đến các nhà cung cấp khác nhau: đối với các mô hình có trọng số mở như DeepSeek V4 Flash, OpenRouter liệt kê 13 nhà cung cấp, nhưng Hy3 preview chỉ có một nhà cung cấp bất chấp trọng số mở của nó: SiliconFlow có trụ sở tại Singapore. Trang sử dụng của họ trên OpenRouter cho thấy SiliconFlow có tương đối ít hoạt động... cho đến khi Hy3 xuất hiện.
Khu vực màu xanh lục tương ứng với việc sử dụng Hy3 miễn phí trong khi khu vực màu xanh dương tương ứng với việc sử dụng Hy3 trả phí: OpenRouter không phân biệt chúng khi di chuột, điều tôi nghi là một lỗi.
Tình cờ là hình ảnh trực quan hóa dữ liệu đó cho thấy việc sử dụng không giảm mạnh khi Hy3 preview chuyển từ miễn phí sang trả phí, bản thân điều này cũng rất thú vị: nếu người dùng không nhận được giá trị từ mô hình miễn phí, họ có thể sẽ ngừng sử dụng nó khi chi phí ảnh hưởng đến túi tiền.
Vậy tôi đang thiếu sót điều gì? Có phải tôi đang suy nghĩ quá nhiều và câu trả lời thực sự chỉ vì "nó là rẻ nhất" và nó đã nhận được đủ lực hút từ giai đoạn miễn phí?
...nhưng liệu Hy3 preview thực sự là LLM rẻ nhất được hỗ trợ bởi một công ty lớn trên OpenRouter không? Trong khi kiểm tra lại một số giả định, tôi phát hiện ra rằng OpenRouter có dữ liệu cho thấy Hy3 preview không phải là LLM hoạt động tốt rẻ nhất có sẵn: thực ra đó là DeepSeek V4 Flash, nhưng với những lưu ý thú vị.
Kinh tế học LLM vào năm 2026
Vì vậy, đây là một vài ghi chú thêm về cách thức hoạt động của API LLM mà ít được thảo luận. Các cuộc gọi LLM vẫn không trạng thái (stateless), điều này có nghĩa là sau mỗi lượt (bao gồm cả tin nhắn của người dùng hỏi LLM), tất cả các token trong luồng hội thoại hiện tại sẽ được xử lý lại. Điều này có nghĩa là trong trường hợp các tác tử (agents), số lượng token đầu vào tăng lên tích lũy với mỗi tin nhắn tiếp theo và là một lý do tại sao việc bắt đầu các luồng mới thường xuyên khi ngữ cảnh đầy lên được khuyến khích để sử dụng tác tử hiệu quả.
Nhưng thậm chí trước cả các quy trình tác tử, các đầu vào lớn như toàn bộ tệp PDF cũng làm phình ngữ cảnh tương tự. Kết quả là, hầu hết các nhà cung cấp LLM đã triển khai prompt caching (bộ nhớ đệm prompt), tái sử dụng các token đầu vào đã được xử lý trước đó trong cuộc hội thoại: đây là tình huống đôi bên cùng có lợi giúp tiết kiệm thời gian/tính toán cho nhà cung cấp LLM và tiết kiệm được chuyển cho khách hàng. Hầu hết các nhà cung cấp LLM cache đầu vào tự động, bao gồm cả khi truy cập qua OpenRouter: biểu tượng tia sét đĩa bên cạnh chi phí cho biết các token đã được cache và cache có thể không luôn trúng đích, đặc biệt nếu OpenRouter chuyển nhà cung cấp giữa luồng. Nhà cung cấp API ngoại lệ là API Anthropic (Claude) yêu cầu trả tiền cho việc ghi cache trước vì một lý do nào đó.
Thông thường, chi phí đọc cache là 10% chi phí đầu vào: đây là trường hợp đối với các mô hình mới nhất từ API OpenAI, API Anthropic và API Google Gemini. Đối với 13 nhà cung cấp phục vụ DeepSeek V4 Flash, chi phí đọc cache nằm trong khoảng từ 20% đến 50% chi phí đầu vào, điều này hợp lý vì họ có thể không có quy mô kinh tế tương tự. Tuy nhiên, có một nhà cung cấp DeepSeek V4 Flash là ngoại lệ:
Đó là chi phí đọc cache chỉ 2%! (nhân 2, dịch dấu thập phân sang trái 2 chỗ). Làm thế nào giá đọc cache của DeepSeek lại thấp đến vậy? DeepSeek đã triển khai cách tiếp cận mới cho KV caching bắt đầu từ V4 và với tư cách là người tạo ra mô hình, họ được định vị tốt nhất để tận dụng các đổi mới của chính mình, và như đã đề cập, lợi ích được chuyển cho khách hàng. Biến thể mô hình DeepSeek V4 Pro, khi được phục vụ bởi chính DeepSeek, có chi phí đọc cache là 0,83%! (hãy dùng máy tính cho cái này).
Nhớ cách tôi đã chỉ ra rằng 98% chi phí API LLM hiện nay là token đầu vào, được tích cực cache? Điều này có nghĩa là các "giá niêm yết" của LLM hiện nay gây hiểu lầm, nhưng một cách bất thường là có lợi cho khách hàng vì giá hiệu quả sẽ rẻ hơn nhiều! Để phản ứng lại sự mơ hồ này, OpenRouter hiện có bảng giá hiệu quả trên trang mô hình, tính toán khoản tiết kiệm chi phí từ các lần trúng cache. Dưới đây là giá hiệu quả cho DeepSeek V4 Flash qua OpenRouter theo nhà cung cấp, khác nhau cho từng nhà cung cấp vì họ có chi phí đọc cache và tỷ lệ trúng cache khác nhau:
 Giá hiệu quả của DeepSeek V4 Flash theo nhà cung cấp
Giá hiệu quả của DeepSeek V4 Flash theo nhà cung cấp
Các giá cả dao động khá nhiều, nhưng hãy chú ý hàng thứ hai nơi chính DeepSeek là nhà cung cấp, được định giá ở mức $0,018/1M token đầu vào khổng lồ! Chi phí đọc cache 2% đó thực sự mang lại lợi ích. So sánh tương tự với Hy3 preview, giá hiệu quả cho Hy3 preview như được ghi chú trên trang mô hình của nó từ SiliconFlow (với chi phí đọc cache cao ngất ngưởng 44%) là $0,034/1M: gần gấp đôi DeepSeek V4 Flash từ DeepSeek! Tất nhiên, điều này chỉ áp dụng nếu DeepSeek được sử dụng rõ ràng làm nhà cung cấp, điều mà một số ứng dụng khách/tác tử OpenRouter hạ nguồn có thể không hỗ trợ: giá OpenRouter khớp với giá trực tiếp từ DeepSeek, vì vậy sử dụng khóa API DeepSeek trực tiếp sẽ hoạt động tương tự.
Tuy nhiên, vẫn còn một vấn đề lớn: DeepSeek là một công ty có trụ sở tại Trung Quốc và một số người có thể không muốn — hoặc có thể không được phép về mặt pháp lý — cung cấp thông tin xử lý thanh toán hoặc dữ liệu đầu vào LLM cho một công ty Trung Quốc đã đặt prompt training = true trong thông tin chính sách dữ liệu OpenRouter của họ, đây là một lo ngại chính đáng.
Có, các dịch vụ LLM dựa trên đăng ký như Claude Code và Codex vẫn là lựa chọn tốt nhất về hiệu quả chi phí nếu bạn có thể sử dụng hết giới hạn sử dụng một cách nhất quán. Nhưng DeepSeek V4 Flash siêu rẻ thông qua API không khóa bạn vào đăng ký, và nếu bạn cần thêm một chút tính toán tác tử để hoàn thành dự án, nó rẻ hơn là trả cho việc sử dụng thêm từ các dịch vụ đăng ký. Ít nhất, đó là một kiểm tra vi mô chống lại các trò chơi定价 (pricing shenanigans) bổ sung có thể sẽ tiếp tục trong suốt năm 2026 khi cạnh tranh trong AI tác tử nóng lên.
Nhìn chung, tôi vẫn không hiểu sự phổ biến của Hy3 preview trên OpenRouter. Dựa trên dữ liệu và phân tích có sẵn ở trên, tôi đoán rằng một ứng dụng lớn duy nhất không liên kết với Tencent thực sự đang sử dụng Hy3 làm xương sống xử lý dữ liệu của mình, và ứng dụng này không chỉ là ứng dụng lập trình tác tử. Nhưng một trong những ưu điểm của OpenRouter là việc chuyển đổi mô hình và nhà cung cấp rất ít tốn sức: tôi sẽ không ngạc nhiên nếu DeepSeek V4 Flash có sự đột biến trong vài tuần tới khi mọi người nhận ra giá cả của nó.
Giấy phép của Hy3 rất hạn chế theo cách có thể ngăn các nhà cung cấp áp dụng mô hình này.
DeepSeek cũng vừa thông báo nền tảng tác tử lập trình của riêng họ với V4 Flash tuyên bố tận dụng caching mạnh mẽ của họ, tuy nhiên nó ở mức chi phí đầu vào 50% nhưng với chi phí đọc cache đắt hơn đáng kể là 20% nên không rõ kinh tế học thực sự có rẻ hơn chỉ sử dụng khóa API DeepSeek với một tác tử khác hay không.


