
Mô hình Ngôn ngữ Đệ quy (RLM): Khám phá kiến trúc AI mới vượt trội hơn ReAct và CodeAct
Bài viết này phân tích sâu về Mô hình Ngôn ngữ Đệ quy (RLM) - một kiến trúc đang thống trị các benchmark về ngữ cảnh dài. Chúng ta sẽ tìm hiểu cách RLM giải quyết các hạn chế của ReAct và CodeAct thông qua cơ chế truyền tham chiếu và môi trường REPL.
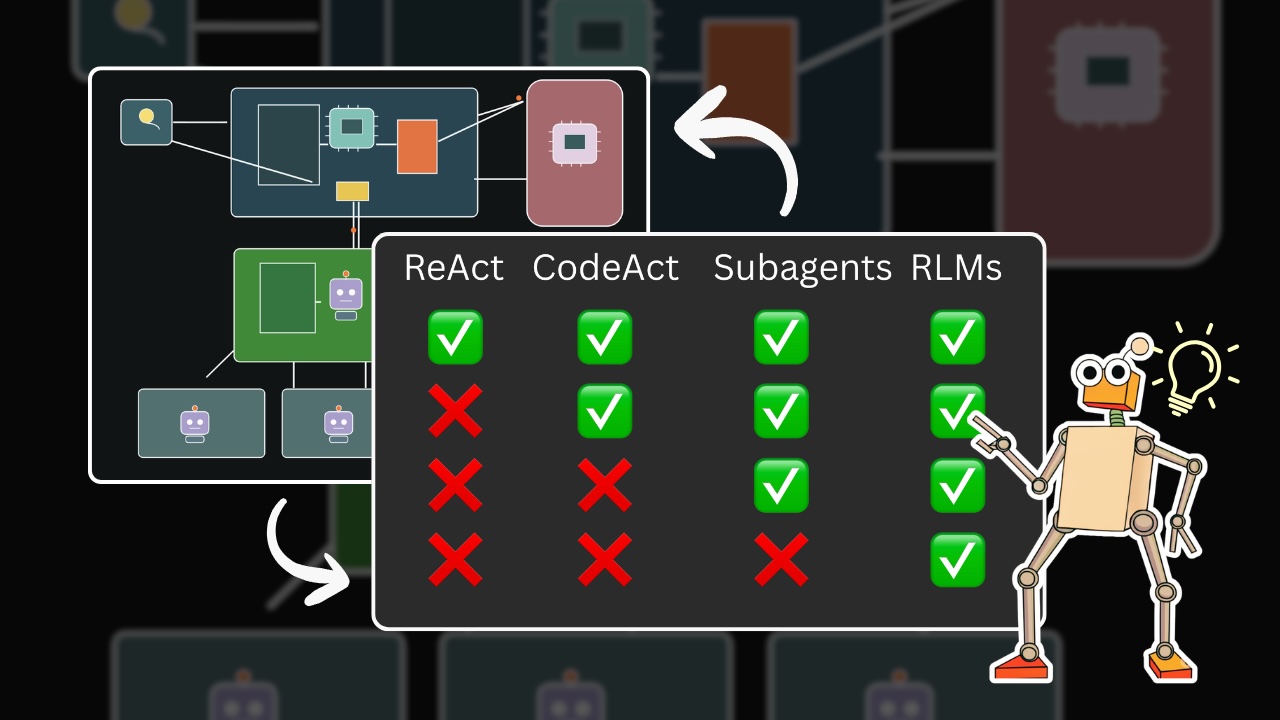
Mô hình Ngôn ngữ Đệ quy (RLM) đang tạo nên một làn sóng mới trong thế giới AI, đặc biệt là trong việc xử lý các tác yêu cầu ngữ cảnh dài và phức tạp. Vậy chính xác RLM là gì và tại sao nó lại vượt trội so với các kiến trúc tác nhân (agent) hiện hành như ReAct hay CodeAct? Hãy cùng đi sâu vào tìm hiểu qua bài viết này.
Vấn đề của các kiến trúc AI hiện tại
Để hiểu rõ sức mạnh của RLM, trước hết chúng ta cần nhìn vào những hạn chế của các phương pháp trước đó. Hãy tưởng tượng một bài toán đơn giản: "Hãy tạo ra danh sách 50 loại trái cây và đếm số lượng chữ 'r' trong mỗi tên, trả về dưới dạng từ điển."
Với Direct Generation (Tạo trực tiếp), mô hình ngôn ngữ (LLM) sẽ cố gắng trả lời ngay lập tức. Cách này dễ dẫn đến ảo giác (hallucination) vì đếm chữ cái không phải là thế mạnh của việc dự đoán từ tiếp theo.
 Kiến trúc các mô hình AI hiện tại
Kiến trúc các mô hình AI hiện tại
ReAct (Reasoning and Acting) ra đời để giải quyết vấn đề này bằng cách cho phép LLM sử dụng các công cụ (tools) được định nghĩa sẵn. Ví dụ, một hàm count_alphabets_in_word có thể được cung cấp. Tuy nhiên, nhược điểm lớn là bạn phải định nghĩa trước công cụ cụ thể cho từng bài toán. Hơn nữa, LLM vẫn phải ghi nhớ kết quả của từng lần gọi hàm và tái tạo lại kết quả đó từ bộ nhớ, dẫn đến nguy cơ sai sót khi truyền tải dữ liệu.
CodeAct tiến xa hơn một bước bằng cách cho phép LLM tự viết mã Python để thực thi nhiệm vụ. LLM không cần công cụ có sẵn mà tự tạo ra công cụ của mình. Mặc dù linh hoạt hơn, CodeAct vẫn gặp phải vấn đề "truyền tải": LLM phải đọc toàn bộ đầu ra từ terminal và sau đó viết lại kết quả đó token-by-token. Khi bài toán mở rộng sang nhiều danh mục (trái cây, quốc gia, động vật), lượng thông tin cần nhớ và tái tạo trở nên quá lớn, gây ra quá tải cho ngữ cảnh (context).
RLM: Sự khác biệt nằm ở "Truyền tham chiếu"
Đây chính là điểm mấu chốt khiến Mô hình Ngôn ngữ Đệ quy (RLM) trở nên đặc biệt. Trong khi các phương pháp trên hoạt động dựa trên nguyên tắc "truyền theo giá trị" (copying data back and forth), RLM sử dụng khái niệm lập trình cổ điển: Truyền tham chiếu (Pass by Reference).
Thay vì sao chép toàn bộ dữ liệu vào prompt của LLM, RLM cho phép LLM thao tác trực tiếp trên các biến (variables) trong một môi trường lập trình bên ngoài.
Môi trường REPL (Read-Eval-Print Loop)
RLM hoạt động dựa trên một môi trường REPL, tương tự như Jupyter Notebook. Một biến context chứa câu hỏi của người dùng được khởi tạo trong môi trường Python này. LLM không nhận toàn bộ nội dung văn bản vào cửa sổ ngữ cảnh ngay lập tức. Thay vào đó, nó chủ động chạy lệnh print(context) để đọc thông tin khi cần thiết.
Điều này cho phép LLM xử lý các đầu vào cực dài (ví dụ: hàng triệu token) một cách linh hoạt. Nó có thể đọc từng phần của dữ liệu, xử lý, lưu kết quả vào các biến Python mới và tiếp tục mà không bị tràn bộ nhớ.
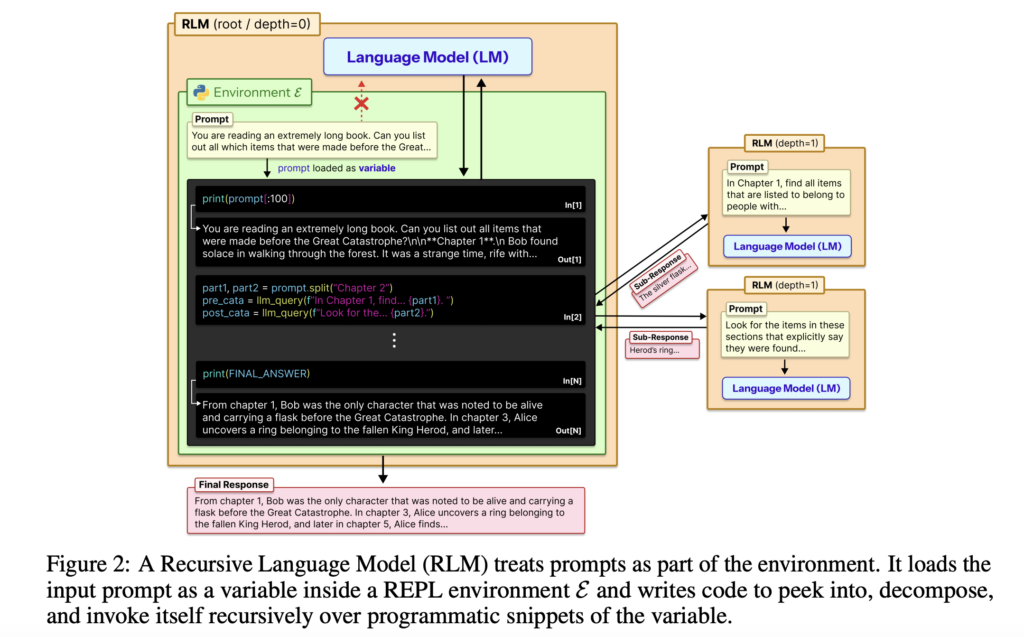 Môi trường REPL trong RLM
Môi trường REPL trong RLM
Quay lại bài toán đếm chữ 'r', với RLM, quy trình sẽ như sau:
- LLM viết mã để tạo danh sách trái cây và lưu vào biến
FRUIT_NAMES. - LLM viết mã để đếm chữ 'r' và lưu kết quả vào biến
fruit_r_count. - Quan trọng nhất: LLM trả về kết quả bằng lệnh
FINAL(fruit_r_count).
Lưu ý rằng LLM không cần đọc toàn bộ từ điển fruit_r_count vào ngữ cảnh của mình để viết lại. Nó chỉ cần trả về tham chiếu đến biến đó. Điều này giúp kết quả đầu ra không bị giới hạn bởi độ dài cửa sổ ngữ cảnh của LLM.
Tác nhân đệ quy (Recursive Subagents)
RLM còn đi xa hơn với khả năng gọi các tác nhân con (subagents) một cách đệ quy thông qua hàm llm_query.
Khi cần giải quyết bài toán phức tạp với nhiều danh mục (trái cây, quốc gia, động vật), tác nhân chính có thể gọi song song các tác nhân con:
FRUIT_DICT = llm_query("...")COUNTRY_DICT = llm_query("...")ANIMAL_DICT = llm_query("...")
Các tác nhân con này sẽ trả về kết quả dưới dạng các đối tượng Python trực tiếp vào REPL của tác nhân chính, thay vì các chuỗi văn bản dài dòng. Tác nhân chính sau đó chỉ cần gom các biến này lại và trả về kết quả cuối cùng.
Cơ chế này giúp giảm thiểu tối đa việc truyền tải dữ liệu dư thừa giữa các tác nhân, tăng tốc độ xử lý và độ chính xác.
Kết luận
Recursive Language Models (RLM) đại diện cho một bước tiến lớn trong kiến trúc AI, chuyển từ việc "sao chép và dán" thông tin sang "tham chiếu và thao tác" dữ liệu. Bằng cách tận dụng môi trường REPL và truyền tham chiếu, RLM giải quyết triệt để vấn đề giới hạn ngữ cảnh và các lỗi truyền tải dữ liệu mà ReAct hay CodeAct đang gặp phải. Đây là lý do tại sao RLM đang ngày càng được chú trọng và áp dụng trong các ứng dụng AI đòi hỏi xử lý dữ liệu quy mô lớn.
Đối với các nhà phát triển, việc hiểu và áp dụng RLM sẽ mở ra nhiều khả năng mới trong việc xây dựng các hệ thống AI thông minh và hiệu quả hơn trong tương lai.


