
Modal tối ưu hóa GPU serverless: Cắt giảm 40 lần thời gian khởi động lạnh cho AI inference
Modal đã giới thiệu một giải pháp kỹ thuật toàn diện giúp giảm thời gian khởi động lạnh (cold start) của các tác vụ suy luận AI xuống còn vài chục giây, thay vì hàng chục phút như trước đây. Bằng cách kết hợp bộ đệm đám mây, hệ thống tệp tùy chỉnh và công nghệ snapshot cho cả CPU lẫn GPU, nền tảng này giúp tối ưu hóa đáng kể hiệu suất sử dụng GPU và chi phí vận hành.

Chúng ta đang sống trong kỷ nguyên của suy luận (inference). Các mạng nơ-ron với hàng tỷ đến hàng nghìn tỷ tham số được chạy trên các bộ tăng tốc chuyên dụng để tạo ra phương tiện, viết phần mềm và gấp protein ở quy mô lớn. Khác với các tác vụ huấn luyện (training), khối lượng công việc suy luận có tính biến động cao và khó dự đoán hơn, khiến nó trở thành ứng cử viên lý tưởng cho mô hình tính toán serverless.
Tuy nhiên, tính toán serverless chỉ thực sự hiệu quả nếu các bản sao (replicas) mới có thể được khởi tạo nhanh chóng để đáp ứng nhu cầu thay đổi theo từng giây. Một cách tiếp cận ngây nhiên để khởi tạo một phiên bản mới chạy SGLang trên GPU B200 có thể mất hàng chục phút, thậm chí hàng giờ để chờ GPU khả dụng.
Tại Modal, chúng tôi đã dành 5 năm qua để giải quyết vấn đề này thông qua 4 yếu tố kỹ thuật then chốt: bộ đệm đám mây (Cloud buffers), hệ thống tệp tùy chỉnh (Custom filesystem), Checkpoint/Restore (C/R) cho CPU và CUDA checkpoint/restore cho GPU. Kết hợp lại, chúng giúp giảm thời gian khởi động của AI inference từ hàng chục phút xuống chỉ còn vài chục giây.
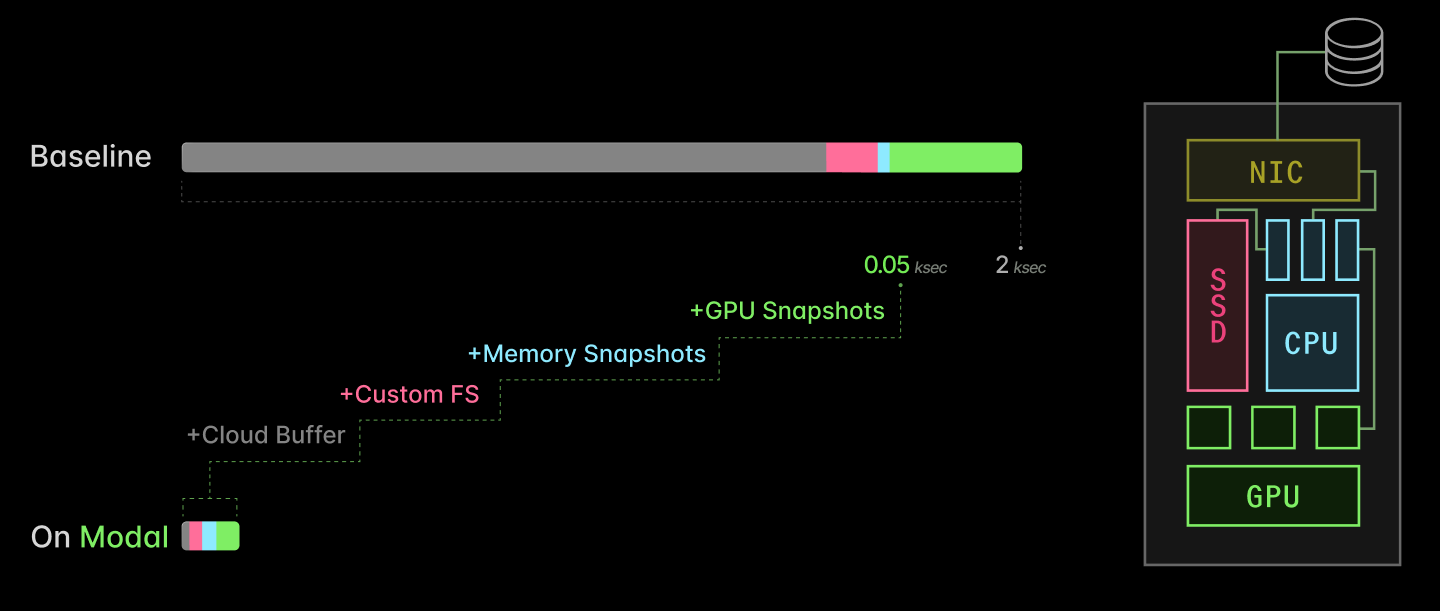 Sơ đồ kiến trúc tối ưu hóa GPU serverless của Modal
Sơ đồ kiến trúc tối ưu hóa GPU serverless của Modal
Tại sao GPU serverless lại quan trọng?
GPU đắt đỏ và khan hiếm, do đó việc tối ưu hóa tỷ lệ sử dụng phân bổ GPU (GPU Allocation Utilization) là yếu tố sống còn đối với các tác vụ suy luận. Các ứng dụng inference thường có nhu cầu biến động mạnh, driven bởi hành vi của người dùng thay vì kiểm soát của kỹ sư.
Nếu cố định phân bổ quá nhiều GPU để đáp ứng đỉnh tải, phần lớn thời gian chúng sẽ nằm im, gây lãng phí. Ngược lại, nếu phân bổ thiếu, hệ thống sẽ bị quá tải khi có cú sốc nhu cầu, dẫn đến trải nghiệm người dùng kém. Theo báo cáo "State of AI Infrastructure at Scale" năm 2024, phần lớn các tổ chức chỉ đạt được dưới 70% tỷ lệ sử dụng GPU, và con số thực tế thường chỉ ở mức 10-20%.
Giải pháp tự động mở rộng quy mô (auto-scaling) thường gặp vấn đề về độ trễ khởi động (startup latency). Nếu việc cấp phát mới quá chậm, chất lượng dịch vụ (QoS) sẽ bị suy giảm và hệ thống có thể bỏ lỡ các đợt tăng trưởng ngắn hạn.
1. Bộ đệm đám mây (Cloud Buffers)
Bước đầu tiên và tốn nhiều thời gian nhất trong việc khởi tạo bản sao là khởi chạy một phiên bản máy chủ mới và kiểm tra sức khỏe (health check). Thay vì thực hiện việc này theo thời gian thực (real-time), chúng tôi thực hiện trước bằng cách duy trì một bộ đệm nhỏ các GPU đang hoạt động, khỏe mạnh nhưng ở trạng thái rảnh rỗi.
Khi nhu cầu tăng lên, các bản sao mới được lập lịch ngay lập tức lên các đơn vị GPU có sẵn này. Việc quản lý bộ đệm này là một bài toán lập trình tuyến tính thú vị, cân bằng giữa giá cả của các nhà cung cấp đám mây và nhu cầu của người dùng.
 Charles Frye, Member of Technical Staff tại Modal
Charles Frye, Member of Technical Staff tại Modal
Việc duy trì bộ đệm giúp loại bỏ hàng chục phút độ trễ khỏi quy trình khởi tạo bản sao. Mặc dù việc này giới hạn tỷ lệ sử dụng đỉnh dưới 100%, nhưng đó là sự đánh đổi hợp lý vì một hệ thống hoạt động ở 100% không có dư địa cho lỗi và rất dễ bị sập.
2. Hệ thống tệp tùy chỉnh với FUSE
Bước tiếp theo thường tốn vài phút là tải chương trình và trạng thái hệ thống tệp (thường là các container). Các hình ảnh container (container images) rất lớn, chứa hàng chục nghìn tệp và gigabyte dữ liệu.
Chúng tôi sử dụng một hệ thống tệp tùy chỉnh gọi là ImageFS, được xây dựng với libfuse. "Mẹo" chính ở đây là sự lười biếng (lazy loading). Thay vì tải toàn bộ hệ thống tệp trước khi container bắt đầu, chúng tôi chỉ chặn khởi động để tải siêu dữ liệu (metadata) - chỉ vài megabyte và có thể tải trong vòng 100ms. Phần còn lại được tải song song hoặc không bao giờ tải nếu không cần thiết.
Hệ thống này kết hợp với bộ nhớ đệm đa tầng (multi-tiered cache) được định địa chỉ nội dung (content-addressed) để tận dụng sự chồng lấn giữa các hình ảnh container khác nhau, giúp tăng tốc độ tải đáng kể.
3. Checkpoint/Restore bộ nhớ CPU
Để khởi động chương trình trên máy chủ (host) và sẵn sàng phục vụ yêu cầu, ứng dụng thường phải thực hiện hàng nghìn dòng mã khởi tạo, chẳng hạn như import torch trong Python. Quá trình này có thể mất hàng chục giây.
Chúng tôi sử dụng kỹ thuật snapshot bộ nhớ để "tua nhanh" quá trình này. Bằng cách lưu trữ trạng thái của quá trình (heap, threads, file descriptors) vào đĩa, chúng tôi có thể khôi phục nó nhanh hơn nhiều so với việc thực thi lại từ đầu.
Modal sử dụng gVisor's runsc để chạy các container người dùng. runsc cho phép tạo checkpoint và khôi phục trạng thái container một cách minh bạch. Kết quả là thời gian tải các thành phần phía máy chủ của một bản sao mới được giảm khoảng 10 lần.
4. CUDA Checkpoint/Restore cho GPU
Thách thức lớn nhất và tốn nhiều thời gian nhất nằm ở bước khởi động chương trình trên thiết bị (GPU). Điều này bao gồm việc tải trọng số mạng nơ-ron (có thể lên tới hàng trăm GB) và thiết lập "inference engine" (ví dụ: biên dịch Torch, tạo CUDA graphs).
Trong khi việc tải trọng số bị giới hạn bởi băng thông lưu trữ, thì việc thiết lập inference engine tạo ra các tạo tác trong bộ nhớ nhỏ nhưng tốn nhiều tính toán để tạo ra và khó lưu vào bộ nhớ đệm.
Các phiên bản trình điều khiển Nvidia gần đây đã hỗ trợ giải pháp checkpoint cho bộ nhớ GPU. Trình điều khiển này lưu trữ trạng thái thiết bị trong bộ nhớ máy chủ, cho phép nó được checkpoint bởi hệ thống phía máy chủ. Sau đó, khi bộ nhớ máy chủ được khôi phục, trình điều khiển sẽ khôi phục lại bộ nhớ GPU.
 Akshat Bubna, CTO và Co-founder tại Modal
Akshat Bubna, CTO và Co-founder tại Modal
Kết quả là tốc độ khởi động tăng lên 4-10 lần, giảm thời gian khởi động container từ vài phút xuống còn vài chục giây.
Kết quả thực tế
Nhờ sự kết hợp của 4 kỹ thuật trên, Modal đã giảm thời gian khởi động lạnh (cold start) cho các máy chủ suy luận từ hơn 2000 giây (khoảng 33 phút) xuống chỉ còn khoảng 50 giây — một cải tiến 40 lần.
Trên hơn mười nghìn lần khởi động lạnh với các mô hình ngôn ngữ khoảng 1 GiB (Qwen 3 0.6B) chạy trên vLLM và SGLang, chúng tôi quan sát thấy độ trễ vượt trội ở mọi phân vị cho các triển khai sử dụng snapshot.
Ví dụ, Reducto — một nền tảng xử lý tài liệu sử dụng mô hình thị giác-ngôn ngữ — đã sử dụng công nghệ này để mở rộng quy mô xử lý hàng nghìn GPU một cách liền mạch. Việc thêm snapshot bộ nhớ GPU đã giúp giảm thời gian khởi động lạnh khoảng 6 lần, từ ~70 giây xuống còn ~12 giây, cho phép họ chạy khối lượng công việc inference lớn theo mô hình "thực sự serverless" mà không cần duy trì dung lượng thừa.
Kết luận
Các dịch vụ đám mây hiện tại được xây dựng cho thế hệ khối lượng công việc cũ như lưu trữ web, không phải cho AI inference. Modal được xây dựng để đưa cơ sở hạ tầng đám mây bắt kịp tốc độ của trí tuệ nhân tạo. Bằng cách chia sẻ cách chúng tôi tối ưu hóa GPU serverless, chúng tôi hy vọng sẽ khuyến khích nhiều kỹ sư giỏi cùng tham gia giải quyết những bài toán khó khăn này.
Bài viết liên quan

Công nghệ
Cisco sa thải 4.000 nhân sự dù doanh thu kỷ lục, chuyển hướng mạnh sang AI
14 tháng 5, 2026
Công nghệ
Fox Corp Đang Trong Tầm Ngắm Để Mua Đổi Roku: Một Bước Ngoặt Lớn Của Thị Trường Streaming
15 tháng 6, 2026

Phần cứng
Belkin ra mắt tay cầm sạc cho Switch 2: vừa cầm thoải mái vừa tăng thời lượng pin
04 tháng 6, 2026